
跳跃表
1、跳跃表的定义
跳跃表(Skip List):增加了向前指针的链表叫做指针。跳表全称叫做跳跃表,简称跳表。跳表是一个随机化的数据结构,实质是一种可以进行二分查找的有序链表。跳表在原有的有序链表上增加了多级索引,通过索引来实现快速查询。跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
跳表是一个随机化的数据结构,可以被看做是二叉树的一个变种,它在性能上和红黑树、AVL树不相上下,但是跳表的原理非常简单, 举生活中一个简单例子,例如我们做公交车,有快线和慢线,想起我之前在广州念书,学校距离市中心比较远,也没有到达,有快线和慢线,快线的站比较少,慢线的站比较多,所以一般我得去快线。
2、跳跃表的原理分析
接下来我们详细得来谈谈跳跃表:

对于一个单链表来说,即使链表中的数据是有序的,如果我们想要查找某个数据,也必须从头到尾的遍历链表,很显然这种查找效率是十分低效的,时间复杂度为O(n)。
那么我们如何提高查找效率呢?我们可以对链表建立一级“索引”,每两个结点提取一个结点到上一级,我们把抽取出来的那一级叫做索引或者索引层,如下图所示。

假设我们要查找59这个结点,你可以先查找第一级索引,依次是14,34, 50,59在50和66之间,所以你查找他的下一级链表,也就是原始链表,查到59这个结点。大大提高了其效率。
当然我们可以在这个基础之上在建立多一级“索引”,如下图所示,
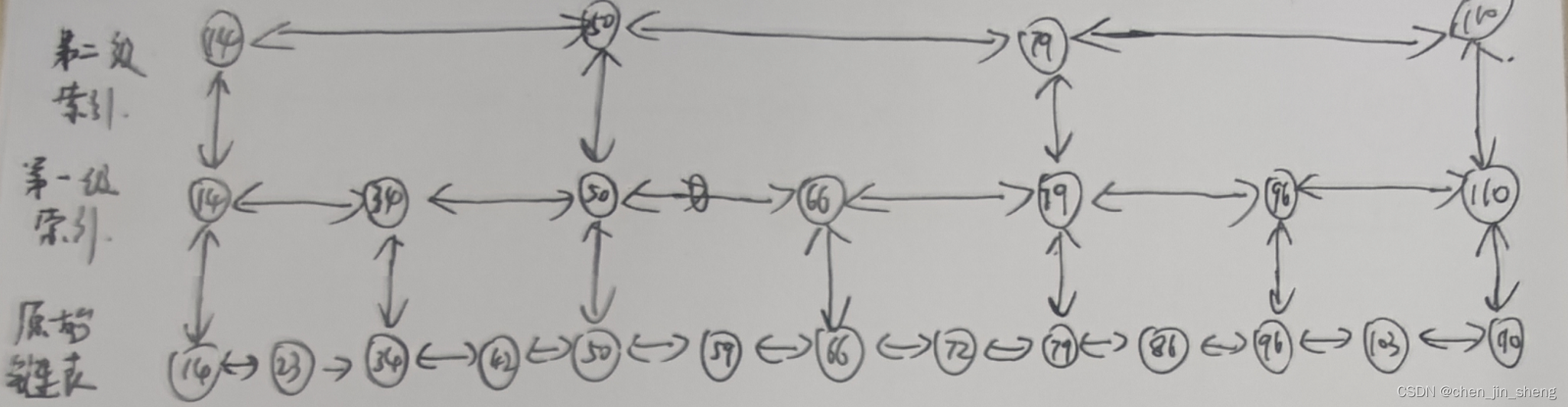
我们还是查找59这个结点,先查找14,50, 介于50和79之间,下一级链表,跳入下一级数,59介于50与66之间,跳入下一级链表,然后找到59。
上面的数量不大,不能够体现其威力,例如我的数据有1000000000个,这个时候的威力也就体现出来,虽然看起来简单,但威力是十分powerful。
3、跳跃表的时间复杂度
单链表的查找时间复杂度为:O(n),下面分析下跳表这种数据结构的查找时间复杂度:
我们首先考虑这样一个问题,如果链表里有n个结点,那么会有多少级索引呢?按照上面讲的,每两个结点都会抽出一个结点作为上一级索引的结点。那么第一级索引的个数大约就是n/2,第二级的索引大约就是n/4,第三级的索引就是n/8,依次类推,也就是说,第k级索引的结点个数是第k-1级索引的结点个数的1/2,那么第k级的索引结点个数为:2/n^{k}。
假设索引有h级,最高级的索引有2个结点,通过上面的公式,我们可以得到n/(2^{h}) = 2,从而可得:h = log{2}n - 1。如果包含原始链表这一层,整个跳表的高度就是\log_{2}n。我们在跳表中查找某个数据的时候,如果每一层都要遍历m个结点,那么在跳表中查询一个数据的时间复杂度就为:O(m*logn)。
如上面的例子,m=2,所以跳表查找任意数据的时间复杂度为O(logn),这个查找的时间复杂度和二分查找是一样的,但是我们却是基于单链表这种数据结构实现的。不过,天下没有免费的午餐,这种查找效率的提升是建立在很多级索引之上的,即空间换时间的思想。其具体空间复杂度见下文详解。
4、跳跃表的空间复杂度
比起单纯的单链表,跳表就需要额外的存储空间去存储多级索引。假设原始链表的大小为n,那么第一级索引大约有n/2个结点,第二级索引大约有4/n个结点,依次类推,每上升一级索引结点的个数就减少一半,直到剩下最后2个结点,如下图所示,其实就是一个等比数列。

这几级索引结点总和为:n/2 + n/4 + n/8 + ... + 8 + 4 + 2 = n - 2。所以跳表的空间复杂度为O(n)。也就是说如果将包含n个结点的单链表构造成跳表,我们需要额外再用接近n个结点的存储空间。
5、跳跃表的改进
其实从上面的分析,我们利用空间换时间的思想,已经把时间压缩到了极致,因为每一级每两个索引结点就有一个会被抽到上一级的索引结点中,所以此时跳表所需要的额外内存空间最多,即空间复杂度最高。其实我们可以通过改变抽取结点的间距来降低跳表的空间复杂度,在其时间复杂度和空间复杂度方面取一个综合性能,当然也要看具体情况,如果内存空间足够,那就可以选择最小的结点间距,即每两个索引结点抽取一个结点到上一级索引中。如果想降低跳表的空间复杂度,则可以选择每三个或者每五个结点,抽取一个结点到上级索引中。
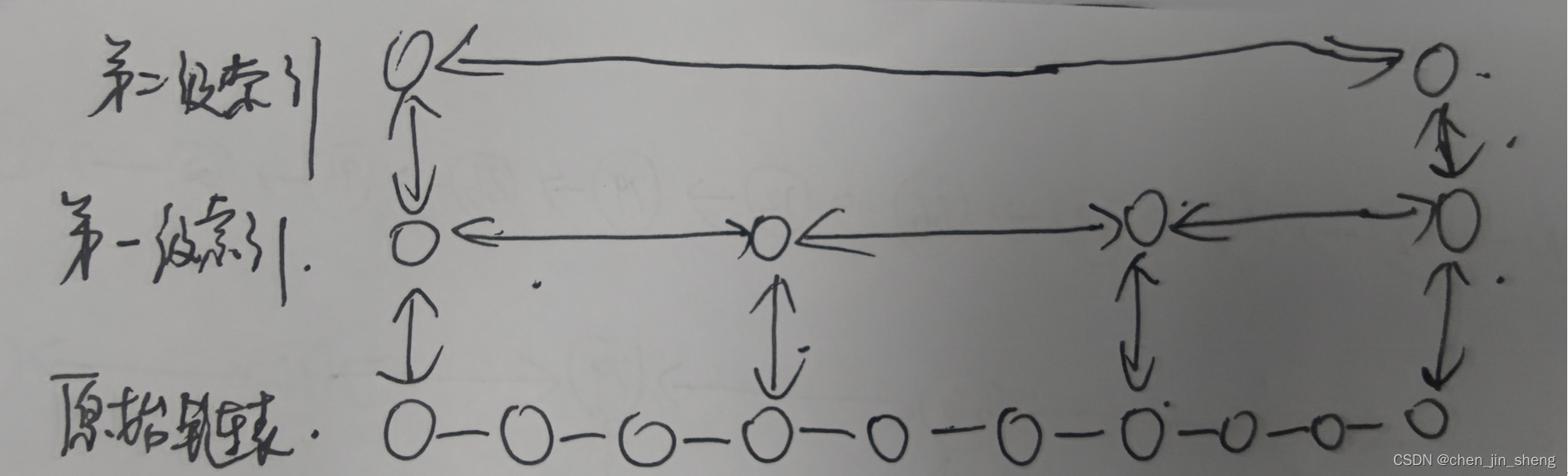
如上图所示,每三个结点抽取一个结点到上一级索引中,则第一级需要大约n/3个结点,第二级索引大约需要n/9个结点。每往上一级,索引的结点个数就除以3,为了方便计算,我们假设最高一级的索引结点个数为1,则可以得到一个等比数列,去下图所示:

通过等比数列的求和公式,总的索引结点大约是:n/3 + n /9 + n/27 + ... + 9 + 3 + 1 = n/2。尽管空间复杂度还是O(n),但是比之前的每两个结点抽一个结点的索引构建方法,可以减少了一半的索引结点存储空间。
实际上,在软件开发中,我们不必太在意索引占用的额外空间。在讲数据结构的时候,我们习惯性地把要处理的数据看成整数,但是在实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,那索引占用的额外空间就可以忽略了。
6、跳跃表的操作
6.1、跳跃表的插入操作
跳表插入的时间复杂度为:O(logn),支持高效的动态插入。
在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1)。但是为了保证原始链表中数据的有序性,我们需要先找到要插入的位置,这个查找的操作就会比较耗时。
对于纯粹的单链表,需要遍历每个结点,来找到插入的位置。但是对于跳表来说,查找的时间复杂度为O(logn),所以这里查找某个数据应该插入的位置的时间复杂度也是O(logn),
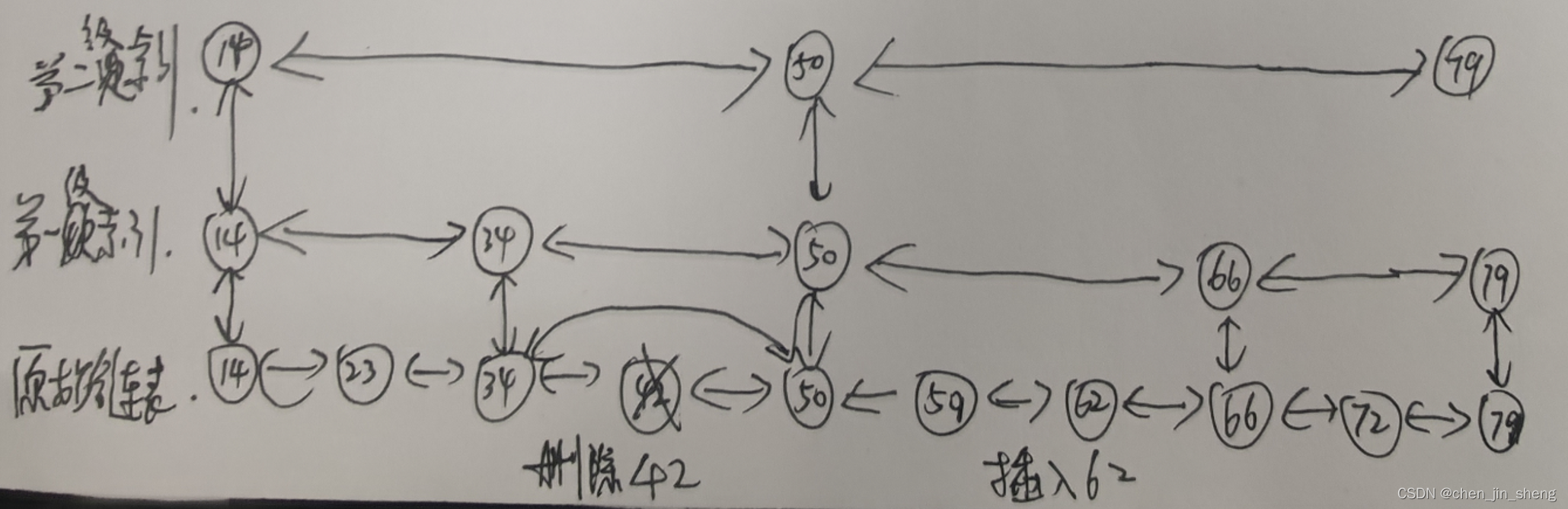
6.3、跳跃表的更新
当我们不断地往跳表中插入数据时,我们如果不更新索引,就有可能出现某2个索引节点之间的数据非常多的情况,在极端情况下,跳表还会退化成单链表,如下图所示:
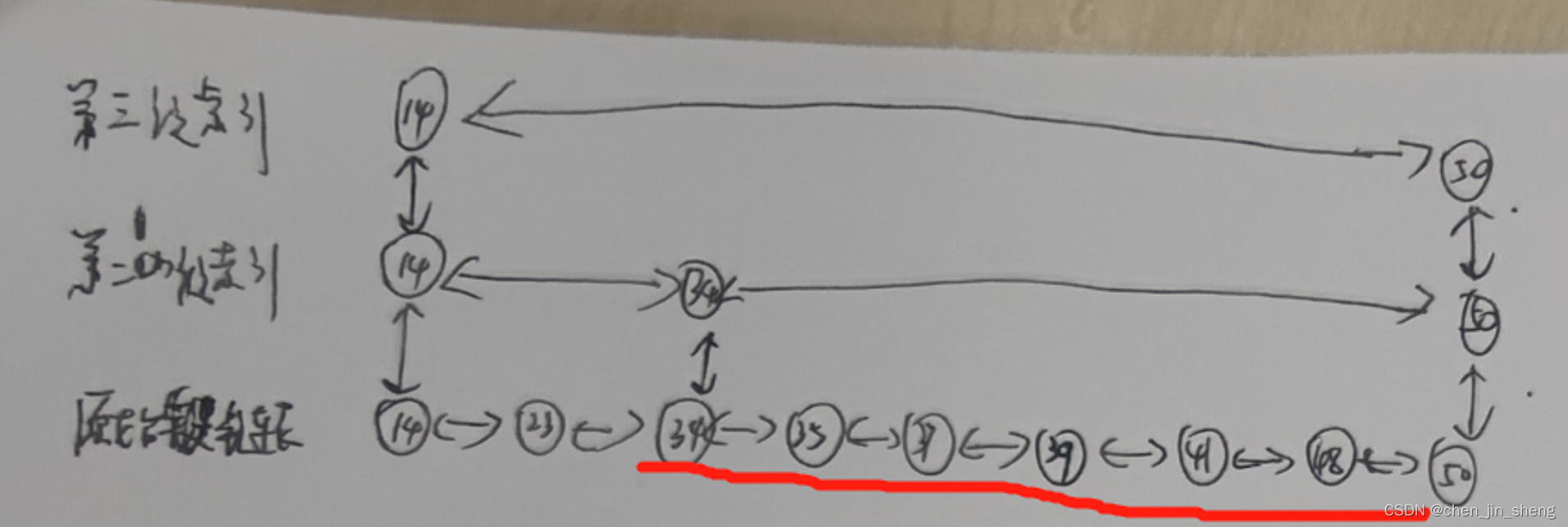
作为一种动态数据结构,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中的结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入和删除操作性能的下降。
如果你了解红黑树、AVL树这样的平衡二叉树,你就会知道它们是通过左右旋的方式保持左右子树的大小平衡,而跳表是通过随机函数来维护“平衡性”。
当我们往跳表中插入数据的时候,我们可以通过一个随机函数,来决定这个结点插入到哪几级索引层中,比如随机函数生成了值K,那我们就将这个结点添加到第一级到第K级这个K级索引中。如下图中要插入数据为45,K=1的例子:
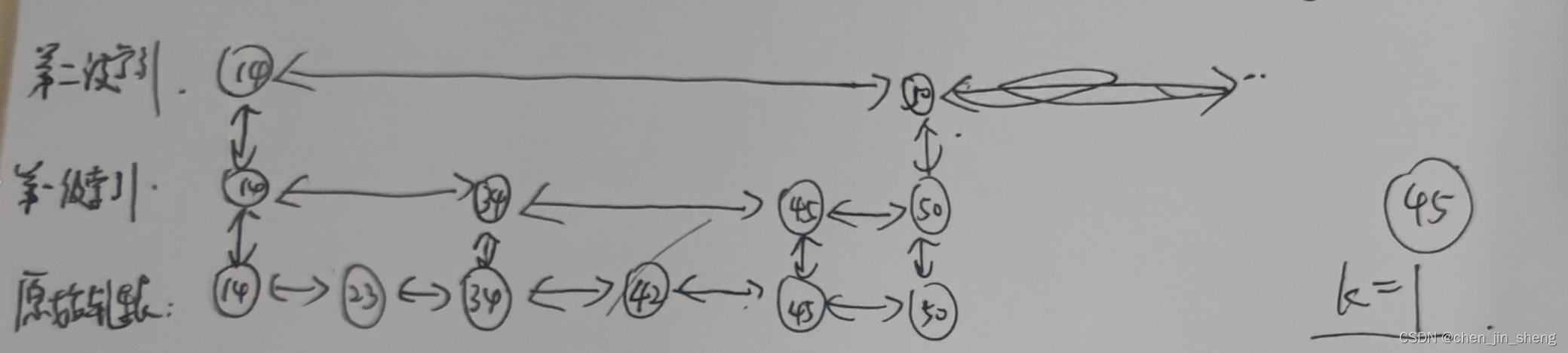
随机函数的选择是非常有讲究的,从概率上讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能的过度退化。至于随机函数的选择,见下面的代码实现过程,而且实现过程并不是重点,掌握思想即可。
7、跳跃表的应用
应用场景:
节点增加和更新比较少,查询频次较多的情况。
使用跳跃表的产品:
1、Lucene, elasticSearch
2、Redis:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的 是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
(30条消息) Redis—跳跃表_平塘码道的博客-CSDN博客_redis跳跃表
————————————————
版权声明:本文为CSDN博主「chen_jin_sheng」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chen_jin_sheng/article/details/121919953

 浙公网安备 33010602011771号
浙公网安备 33010602011771号