mysql需要了解哪些知识
1.sql操作
2.索引 索引原理 索引优化 sql语句优化
3.事务 并发读异常的问题 并发死锁怎么解决
4. mysql与缓存 解决读性能问题 集群的内容
OLTP:
OLTP(online transaction processing)翻译为联机事务处理;主要对数据库增删改查;
OLTP主要用来记录某类业务事件的发生;数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功;后端开发主要使用的事OLTP
OLAP:
OLAP(On-Line Analytical Processing)翻译为联机分析处理;主要对数据库查询;
当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做OLAP了;
SQL:
定义:
结构化查询语言(Structured Query Language)简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。SQL是关系数据库系统的标准语言。
关系型数据库包括:MySQL, SQL Server, Oracle, Sybase, postgreSQL 以及 MS Access等;
SQL命令包括:DQL、DML、DDL、DCL以及TCL;
DQL:
Data Query Language - 数据查询语言;
select :从一个或者多个表中检索特定的记录;
DML:
Data Manipulate Language - 数据操作语言;
insert :插入记录;
update :更新记录;
delete :删除记录;
DDL:
Data Define Languge - 数据定义语言;
create :创建一个新的表、表的视图、或者在数据库中的对象;
alter :修改现有的数据库对象,例如修改表的属性或者字段;
drop :删除表、数据库对象或者视图
DCL:
Data Control Language - 数据控制语言;
grant :授予用户权限;
revoke :收回用户权限;
TCL:
Transaction Control Language - 事务控制语言;
commit :事务提交;
rollback :事务回滚;
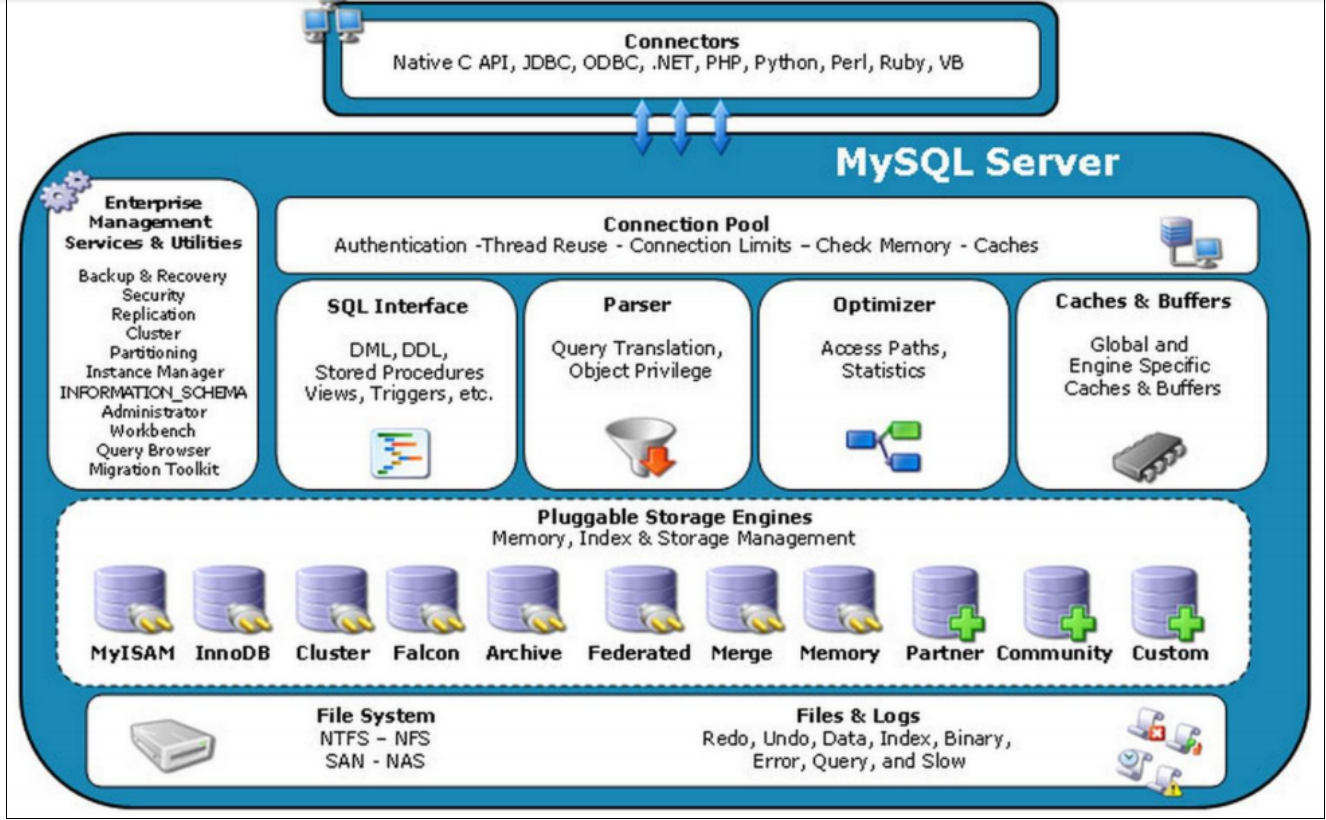
MySQL体系结构
![]()
MySQL由以下几部分组成:
连接池组件、管理服务和工具组件、SQL接口组件、查询分析器组件、优化器组件、缓冲组件、插件式存储引擎、物理文件。
开启多个连接也会影响数据库的效率
连接者:
不同语言的代码程序和mysql的交互(SQL交互);
连接池:
管理缓冲用户连接、用户名、密码、权限校验、线程处理等需要缓存的需求;
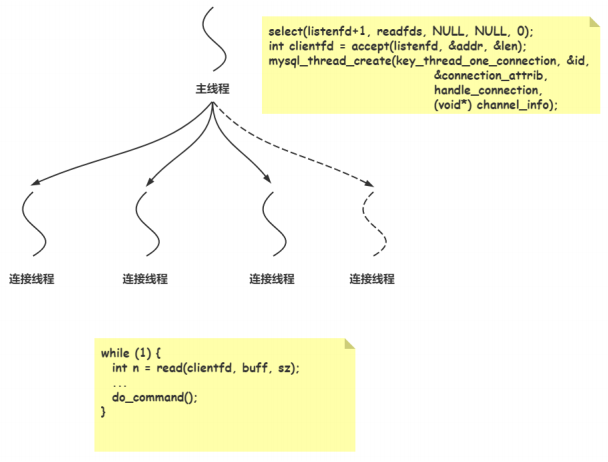
网络处理流程:主线程接收连接,接收连接交由连接池处理;
主要处理方式:IO多路复用select + 阻塞的io;
需要理解:MySQL命令处理是并发处理的;
![]()
数据库主线程只关注读 事件,只监听listenfd,连接的事件。MySQL采用的阻塞的IO,因为mysql需要访问磁盘,重IO,是同步的。redis采用的reactor异步的。mysql只支持150左右的连接,连接数量多会影响性能。
主线程负责接收客户端连接,然后为每个客户端 fd 分配一个连接线程,fd是阻塞的,负责处理该客户端的 sql命令处理;
1.词法句法分析,对象权限验证,制定执行计划与路径,缓存由引擎操作,如果需要查找的在buffer中存在,就从buffer中取,否则访问磁盘。
流程:sql是个语言,首先做词法句法分析(SQL Interface),对象的权限验证,过滤(parser),优化执行路径,根据索引(optimizer),缓存
存储引擎是描述表的。
管理服务和工具组件:
系统管理和控制工具,例如备份恢复、Mysql复制、集群等;
SQL接口:
将SQL语句解析生成相应对象;DML,DDL,存储过程,视图,触发器等;
查询解析器
将SQL对象交由解析器验证和解析,并生成语法树;
查询优化器
SQL语句执行前使用查询优化器进行优化;
缓冲组件
是一块内存区域,用来弥补磁盘速度较慢对数据库性能的影响;在数据库进行读取页操作,首先将
从磁盘读到的页存放在缓冲池中,下一次再读相同的页时,首先判断该页是否在缓冲池中,若在缓
冲池命中,直接读取;否则读取磁盘中的页,说明该页被LRU淘汰了;缓冲池中LRU采用最近最少
使用算法来进行管理;
缓冲池缓存的数据类型有:索引页、数据页、以及与存储引擎缓存相关的数据(比如innodb引
擎:undo页、插入缓冲、自适应hash索引、innodb相关锁信息、数据字典信息等);
mysql中有三种条件语句:
1.select *from table where condition;
普通用where
2.group by column having condition;
分组用having
3.join table on condition;
联表用on
innoDB才有外键,
管理缓冲用户连接、用户名、密码、权限校验、线程处理等需要缓存的需求;
网络处理流程:主线程接收连接,接收连接交由连接池处理;
主要处理方式:IO多路复用select + 阻塞的io;
需要理解:MySQL命令处理是并发处理的;
数据库的三范式:
1.确保每列保持原子性;数据库表总的所有字段都是不可分解的原子值;
2.确保表中的每列都和逐渐相关,而不能只与主键的一部分相关。
3.确保每列都和逐渐直接相关,不是间接相关;减少数据冗余。
反范式:
如果重复数据相对较少,并且经常被查询。
删除表数据:
truncate:截断表,以页为单位(至少有两行数据),有自增索引的话,从0开始。
delete:逐行删除,有自增索引的话,从之前值继续累加。
有几种条件语句:
1.select * from table where condition; :筛选
2.group by 列名 having condition; :分组
3. ...join table on condition; :联表
条件判断中尽量选择索引。索引是帮助我们快速查询数据的。
去重:
select distinct 列名 from table
group by
合并
group_concat 通常与group by联合用
聚合函数 (列)
sum()
avg()
max()
min()
count(0
判空查询:
即使条件是索引, 判空时也不会走索引,... where class_id is not null;
is null 会造成索引失效;
模糊查询
使用like关键字, %代表任意数量字符, _代表占位符
分页查询
分页查询主要查看第N条到第M条信息,通常和排序一起。速度快。
OLTP读次数大约是 写的10倍左右,因此要解决读的性能
为什么innodb需要主动创建主键索引,并且以自增的整数作为主键?
![]()
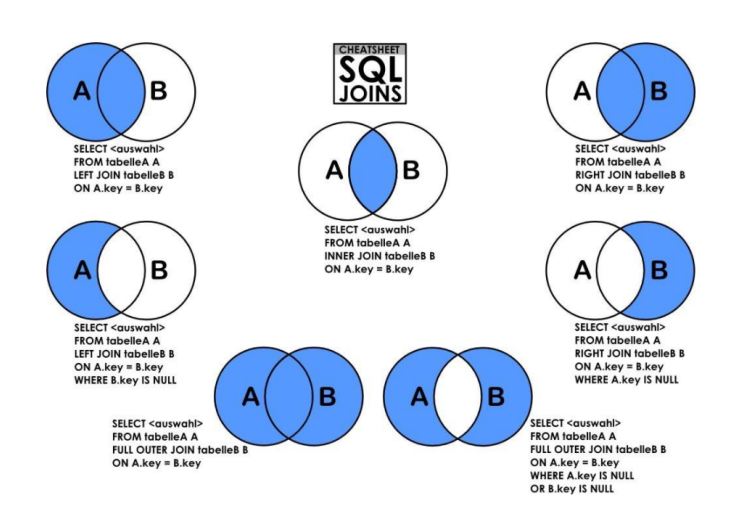
1.select column from tableA left join tableB on A.key = B.key;
2.select column from tableA inner join tableB on A.key = B.key;
3.select column from tableA right join tableB on A.key = B.key;
4.select column from tableA left join tableB on A.key = B.key where B.key is null;
5.select column from tableA right join tableB on A.key = B.key where A.key is null;
6.select column from tableA full outer join tableB on A.key = B.key;
7.select column from tableA full outer join tableB on A.key = B.key where A.key is null or B.key is null;
where B.key is null
一. B树与B+树的区别?
答:两者都是排序的,B+树叶子节点都保存着上节点和下节点的物理地址
1,就是B+树所有关键码都在叶子节点·
2,B+树的叶子节点是带有指针的,且叶节点本身按关键码从小到大顺序连接
3,在搜索过程中,如果查询和内部节点的关键字一致,那么搜索过程不停止,而是继续向下搜索这个分支。
4.B树没有冗余索引,都是不同的
为什么不适用hash?
仅能满足“=”,“IN”,不支持范围查询
二.为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
表结构是靠主键来组织,如果不建立主键,就找一个唯一的,如果再没有就自己创建一个rowid,尽量不要让数据库做其他操作。查找数据时,比较整型比其他的要快。自增,减少节点分裂的可能
编写sql语句时,首先把功能拆分,然后再聚合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号