

第二章 API的理解和使用
2.1.1全局命令
Key * 查看所有键,(慎用,会把所有键都遍历一次并列出)
Dbsize 查看键总数,不会遍历所有键,只是从内置函数中读取一个数
Exists [key] 检查键是否存在
Del [key] 删除键
Expire [key] [seconds] 设置键过期时间
Type [key] 键的数据结构类型
2.1.2数据结构和内部编码
Type命令实际返回的就是当前键的数据结构类型:string字符串,hash哈希,list列表,set集合,zset有序集合,但这些只是redis对外的数据结构,
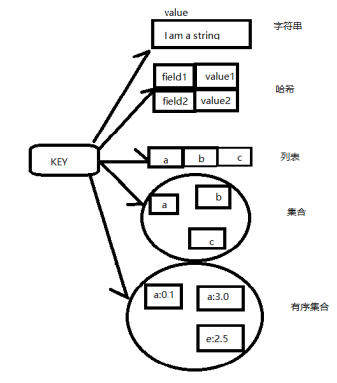
实际上每种数据结构都有自己底层的内部编码实现,而且试多种实现,这样redis会在合适的场景选择合适的内部编码
String raw,int,embstr
Hash hashtable,ziplist
Key List linkedlist,ziplist
Set hashtable,intset
Zset skiplist,ziplist
可以通过object encoding命令查询内部编码。这样的设计可以适应不同业务场景
2.1.3单线程架构
Redis使用了单线程架构和I/O多路复用模型来实现高性能的内存数据库服务。
客户端与服务端的模型可以简化为:发送命令,执行命令,返回结果三步。
其中第二步因为redis是单线程来处理命令的,所以一条命令从客户端到达服务端不会立刻被执行,所有命令都会进入一个队列中,然后逐个被执行。这样可以避免并发的问题。
为什么单线程还能这么快?
第一,纯内存访问,redis将所有数据放在内存中,内存的响应时长大约在100纳秒,这是redis达到每秒万级别访问的重要基础。
第二,非阻塞I/O,Redis使用epoll作为io多路复用技术的实现,再加上redis自身的事件处理模型将epoll中的连接,读写,关闭都转换为事件,不在网络io上浪费过多的时间
单线程避免了线程切换和竟态产生的消耗。
2.2字符串
是最基础的数据类型,其它几种数据类型也是在字符串的基础上构建的;实际上字符串类型的值还可以是:字符串,数字,二进制,但值不能超过512MB
2.2.1命令
设置值
Set key value [ex seconds] [px milliseconds] [nx|xx]
Ex seconds:设置秒级过期时间
px milliseconds:设置毫秒级过期时间
Nx 键必须不存在,才可以设置成功,用于添加
Xx:与nx相反,键必须存在,才可以设置成功,用于更新
获取值
Get key
批量设置值:
Mset key value [key value key value]
批量获取
Mget key [key key key]
计数
Incr key
命令用于对值进行自增操作,返回结果又3种:
值不是整数,返回错误
值是整数,返回自增后结果
键不存在,按照值为0自增,返回结果为1
相关的还提供了decr自减,incrby自增指定数字,decrby自减指定数字,incrbyfloat自增浮点型
追加命令
Append key value
向value的尾部追加值
字符串长度:
strlen key
设置并返回原值
Getset key value
设置指定位置的字符
Setrange key offeset value
获取部分字符串
Getrange key start end
2.2.2内部编码
字符串类型有三种内部编码:
Int:8个字节的长整形
Embstr:小于等于39个字节的字符串
Raw:大于39个字节的字符串
Redis会根据当前值的类型和长度决定使用那种内部编码
2.2.3使用场景
缓存功能;
使用redis作为系统的缓存层关系型数据库作为数据层。Reids具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
UserInfo getUserInfo(long id){
1,检查redis种是否存在用户信息
2,从redis种获取session信息
3,如果没有则序列化到redis
}
计数
许多应用都会使用redis实现计数功能
共享session
一个分布式web服务将用户的session信息保存再各个服务器中,这会造成一个问题:出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同的服务器上,用户刷新一次会造成重复登陆的现象。为了解决这个问题,可以使用redis将用户的session进行集中管理,每次用户更新或者查询登陆信息都直接从reids种获取信息
限数
很多应用出于安全考虑,会再每次进行登陆时,让用户输入验证码,但为了短信接口不被频繁访问会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。
2.3哈希
哈希类型是指键值本身又是一个键值结构。
Key - value={
{field,value} {field,value} {field,value}...}
2.3.1命令
设置值 hset key field value
获取值 hget key field
删除field: hdel field [field...]
计算个数:hlen key
批量操作:
Hmget key field
Hmset key value[field value,field value]
是否存在:hexists key field
获取所有的field:hkeys key
获取所有的value:hvals key
获取所有的field-value:hgetall key
计算value的字符串长度:hstrleng key value
2.3.2内部编码
Ziplist压缩列表:当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个),同时所有值都小于hash-max-ziplist-value配置(默认配置64字节)时,redis会使用ziplist作为内部实现
Hashtable哈希表:当不满足压缩列表时自动升级为哈希表,hashtable的读写时间复杂度O(1)
2.3.3使用场景
可以将关系型数据库表记录的数据(user表)通过userID缓存到redis中。
比如将整个用户的关联信息通过json缓存到field中
需要注意两点哈希类型是稀疏的,而关系型数据库是完全结构化的。
关系型数据库可以做复杂的关系查询,而reids去模拟关系型复杂查询开发难度高维护成本高
2.4列表
列表用力啊存储多个有序的字符串,如图由五个元素组成的列表,列表中的每个字符串成为元素,一个列表最多存2的32次方-1个元素。
再redis中,可以对列表两端进行插入和弹出,还可以获取指定范围的元素列表,获取指定索引下表的元素。列表是一种比较灵活的数据结构,可以充当栈和队列的角色,再实际开发中由很多的应用场景。
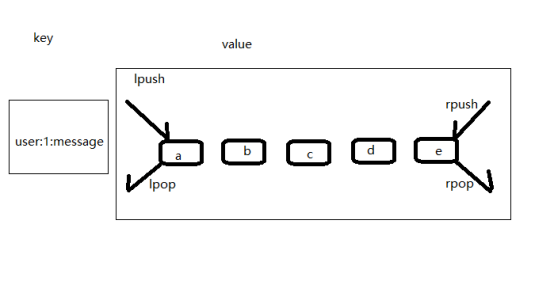
列表有两个特点:一.列表中的元素是有序的;二.列表中的元素可以重复。
2.4.1命令
l 添加命令:lpush,rpush,linsert
l 查看: lrange,lindex,llen
l 删除: lpop,rpop,lrem,ltrim
l 修改: lset
l 阻塞操作:blpop,brpop
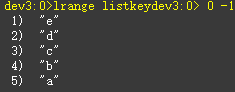
从右边插入元素:rpush key value [value1 value2 value3...]
Rpush listkey a b c d e

从左到右查看元素lrange listkey 0 -1
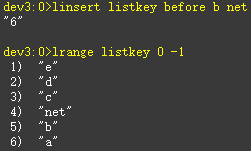
向某个元素前后插入元素:linsert key before|after prvot value
Linsert listkey before b net
查找
获取指定范围内的元素列表
lrange key start end
lrange操作会获取列表指定索引范围所有的元素。索引下标有两个特点:
第一,索引下标从左到右分别是0到N-1,但从右到左分别是-1到-N。
第二,lrange中的end选项包含了自身。Eg:想获取列表的第2到第4个元素
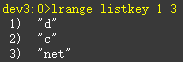
获取列表指定索引下标的元素 lindex key index
Eg:获取当前列表最后一个元素a
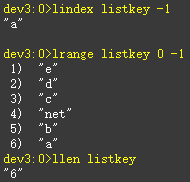
lindex listkey -1
获取当前列表长度llen key
删除
从列表左侧弹出元素
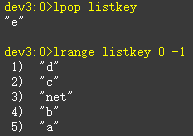
删除指定元素lrem key count value
Lrem命令会从列表中找到等于vlaue元素进行删除,根据count的不同分为三种情况:
Count>0:从左到右,删除最多count个元素
Count<0:从右到左,删除最多count绝对值个元素
Count=0:删除所有。
例如先向列表中插入4个a,然后删除列表a左侧的4个元素
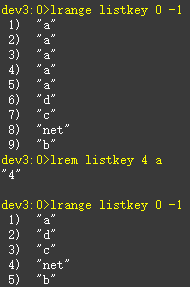
按索引范围修剪列表元素ltrim key start end

修改,修改指定索引下标的元素:lset key index newValue
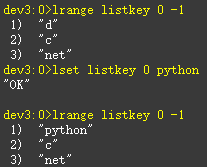
2.4.2内部编码
列表类型的内部编码右两种。
Ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表种每个元素的值都小于list-max-ziplist-value配置时(默认64字节),redis会选用ziplist来作为列表的内部实现来减少内存的使用。
Linkedlist(链表)
2.4.3使用场景
消息队列
文章列表:每个用户右属于自己的文章列表,需要分页展示文章列表。此时可以考虑使用列表。因为列表不但时有序的,而且支持按索引范围获取元素。(文章内容可以使用hash结构来存储)
2.5集合
集合类型也是用来保存多个字符串元素,但和列表类型不一样的是集合中不可以有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素。Redis除了支持集合内的增删改查,同时还支持多个集合取交集/并集/差集
2.5.1命令
添加元素:sadd key element [ele ele ele]
删除元素:srem key element [ele ele ele]
计算元素个数:scard key 他不会遍历整个集合而是取内部变量
判断元素是否在集合中:siselember key element
随机从集合返回指定个数元素 srandmember key [count]
从集合中随机弹出元素:spop key
获取所有集合元素:smembers key
集合间操作
求多个集合的交集:sinter key [key key...]
求多个集合的并集:sunion key [key key...]
求多个集合的差集:sdiff key [key key...]
将交集,并集,差集的结果保存
sinterstore destination key [key key...]
如上
2.5.2内部编码
Intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,redis会选用intset来作为集合的内部实现,从而减少内存使用。
Hashtable:当集合类型无法满足intset的条件时,使用hashtable作为它的内部实现。
2.5.3使用场景
用户标签,一个用户可能有很多的兴趣爱好。
2.6有序集合
有序集合保留了集合不能有重复成员的特性,但不同的时,有序集合中的元素可以排序。但是它和列表使用索引下标作为排序依据不同的时,它给每个元素设置一个分数作为排序的依据。注意,元素不能重复但是score可以重复
2.6.2内部编码
Ziplist(压缩列表):当有序集合元素个数小于zset-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,redis会用ziplist来作为有序集合的内部实现。
Skiplist(跳跃表)
2.6.3使用场景
排行榜系统。
2.7键管理
2.7.1单个键管理
键重命名: rename key newkey
如果在rename之前,键已经存在,那么它的值也将被覆盖。为了防止被强行rename,redis提供了renamenx命令,确保只有newkey不存在时才被覆盖。注意:
由于重命名键期间会执行del命令删除旧键,如果键对应的值比较大,会存在阻塞的可能性
如果rename和renamenx中的key和newkey如果是相同的,在3.2版本中时可以的,在3.2以前会报错。
随机返回一个键:randomkey
2.7.2遍历键
Keys [pattern]替代pattern是* ? [] \x
Keys * 获取所有的键
* 代表所有
? 代表匹配一个字符
[] 代表匹配部分字符
\x 用来做转义;比如要匹配星号则需要转义
Keys是会造成阻塞所以一般不建议在生产环境上使用
渐进式遍历
从2.8版本后,提供了一个新的命令scan,它通过渐进式遍历的方式解决keys在遍历是带来的阻塞问题。每次scan命令的时间复杂的是O(1)。但要真正实现keys的功能,需要执行多次scan。
每次执行scan,可以想象成扫描了一个字段中的一部分键,直到将字典中的所有键遍历完毕。使用方法:Scan cursor [match pattern] [count number]
Cursor是必须参数,实际上cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0标识遍历结束。
Match pattern是可选参数,它的作用类似与模式匹配,这点和keys的模式匹配很想。
Count number是可选参数,它的作用是表名每次遍历键的个数默认值是10,可以适当增大。
Scan虽然有效的解决了keys命令可能产生的阻塞问题,但scan并非完美 ,如果在scan的过程中如果有键发生了变化(增删改),那么便利的效果可能会碰到新增的键没有被查到,遍历出的键重复了等情况。
也就是说scan并不能完整的遍历出所有的键。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号