

SQL学习--Select(一)TOP、派生表、连接、谓词
TOP关键字


1 select top 4 WITH TIES t.title,sum(s.qty)as totalSales from sales s 2 left join titles t on s.title_id=t.title_id 3 group by t.title 4 order by totalSales
这里的top 4 WITH TIES 是获取前4条数据且需要重复值,但是请注意这个重复值是会影响返回数据的行
比如,重复值在第4行出现那么可能就会返回5行数据(2个值的重复)
如果重复值在第二行或者第三行出现则只返回4条数据
另外需要注意的TOP N WITH TIES...需要与order by一同使用否则会报错。
TOP N的缺点
无法返回与查询的GroupBy子句中的被分组的结果集的前几条,
这就标明TOP N指向的是整个查询的结果集,而不是指向源表中或已被分类的组中的行。
TOP N的运算顺序在整个sql关键字的后边。实例:
1 select t.state,t.stor_name,sum(s.qty)as totalSales 2 from sales s join stores as t on s.stor_id=t.stor_id 3 group by t.state,t.stor_name 4 order by totalSales desc 5 6 select top 1 t.state,t.stor_name,sum(s.qty)as totalSales 7 from sales s join stores as t on s.stor_id=t.stor_id 8 group by t.state,t.stor_name 9 order by totalSales desc

派生表
select除了直接引用表或试图外还可以使用派生表(子查询),也叫逻辑表。它可以像表或视图一样查询和链接
select au_lname,au_fname from (select * from authors) as a
这个派生表是由select * from authors语法创建的,此处可以插入任何一个有效的查询,
但需要注意这里使用别名且必须使用别名。因为T-SQL支持非列表的Select语句。
1 select * from ( 2 select 'Blotchet-Halls' as weightClass ,0 as lowBound ,112 as highBound 3 union all 4 select 'DeFrance' as weightClass ,112 as lowBound ,118 as highBound 5 union all 6 select 'Green' as weightClass ,127 as lowBound ,135 as highBound 7 )as w 8 order by w.lowBound
例子中这个表不存在只是通过union all链接形成了一张逻辑表,逻辑表同时可以与表或试图相连接
连接
在内连接中,从句顺序s不会影响到结果集。如果A等于B,那么B就等于A。
而在外连接中则不然,表中的顺序直接影响结果集中包含的哪些行及值
1 select sum(d.UnitPrice*d.Quantity) as totalOrders from Orders o 2 left join [Order Details] d on o.OrderID+10=d.OrderID 3 left join Products p on d.ProductID=p.ProductID 4 5 select sum(d.UnitPrice*d.Quantity) as totalOrders from [Order Details] d 6 left join Products p on d.ProductID=p.ProductID 7 left join [Orders] o on o.OrderID+10=d.OrderID 8 --连接部分的先后顺序改变了
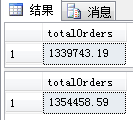
在例子中故意把OrderID+10造成不匹配,观察两次查询的运算结果,并不相同。
因为第一个查询中引起的表Orders和Order Details的不匹配是在对列UnitPrice*Quantity汇总前,
而第二个查询的不匹配是发生在汇总后。第二个查询的情况下,会得到所有Details中的所有项的总和,
无论他与Orders是否匹配,而在第一个查询中就不是这样了。
看一下在2个查询中不匹配的数据有哪些
1 select o.OrderDate,d.UnitPrice,d.Quantity from Orders o 2 left join [Order Details] d on o.OrderID+10=d.OrderID 3 left join Products p on d.ProductID=p.ProductID 4 where o.OrderDate is null or d.UnitPrice is null
执行语句后,会发现正是我通过OrderID+10的那10条数据。
所以在使用外部链接存在不匹配链接的可能,所以一定要小心。
谓词
BETWEEN
他的作用是判断一个给定值是否落在了两个值之间的内部
1 select au_lname,au_fname from authors 2 where au_lname between 's' and 'zz' 3 order by au_lname
带有子集、变量和表达式的语句
1 Declare @au_id id 2 select @au_id=(select max(au_id) from titleauthor) 3 4 select au_lname,au_fname from authors 5 where au_id between (select min(au_id) from titleauthor) and (ISNULL(@au_id,'zzzzzzzzzzzzz')) 6 order by au_lname
尽管BetWEEN...AND很方便,但有时候很难界定多个区间的范围。此时不如用逆向思维排除法,扣去必定发生的,就能得到不会发生的
LIKE
检测一个值对字符串的模式匹配
%:表示匹配任意字符
_:表示只匹配一个字符
[ab]:表示匹配a、b、ab
EXISTS
把子查询作为单独参数返回的判断函数。在EXISTS前边加NOT表示否定
EXISTS在指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中
如果成立则返回true不成立则返回false。如果返回的是true的话,则该行结果保留,如果返回的是false的话,则删除该行,最后将得到的结果返回。
在EXISTS中NULL值的处理
1 select title from titles t 2 where EXISTS(--此时为true 3 select * from( 4 select *from sales 5 union all 6 select null,null,null,90,null,null 7 ) s--通过union all插入了一条为null,qty为90的数据 8 where t.title_id=s.title_id and s.qty>75)
这个查询结果最后还是空。为什么呢?最后插入的null的那条数据是满足where qty>75的为什么没有返回?
答案是即便是返回了但是连接条件是titleid=titleid,而插入的数据titleID=null,null怎么可能等于null呢?null谁都不等于,也不等于自己
EXISTS和IN
把EXISTS换成IN有一些特殊性。
1 select Count(title) from titles t 2 where t.title_id in(select title_id from sales)--16条 3 4 select Count(title) from titles t 5 where t.title_id not in(select title_id from sales)--2条 6 7 select Count(title) from titles t 8 where t.title_id not in(select title_id from sales union all select null)--0条
IN在比较一个值与NULL是否相等的表达式总是返回NULL,所以不符合检测,原因是其他行与null在同一列表所以返回null。这是IN和EXISTS的区别
另外如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。
同时不管使用哪种子查询的方式都是比表连接要慢很多的,所以建议使用连接的方式。
结果集为空
EXISTS的另外一种用法是检测结果集的多行。
if exists(select * from sales)肯定要比if(select count(*) from sales )>0快的多,而且提供了一种不检查系统对象来确定表是否为空的快速方法
where和having以外的EXISTS
EXISTS还可以做很多其他的工作,不仅仅是查询返回的行。通过派生表还可以在case表达式和from子句中
select case when EXISTS(Select * from titleauthor where au_id=a.au_id) then 'true' else 'false' end from authors a
IN
1 select * from titles where title_id in 2 ( 3 select title_id from ( 4 select top 99999 title_id,count(*) as numberOrder from sales group by title_id order by numberOrder desc 5 )s 6 )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号