Node:使用puppeteer爬取网页数据
puppeteer?
高级API的node库,能够通过devtool控制headless模式的chrome或者chromium,它可以在headless模式下模拟任何的人为操作。
与cheerio的区别
cherrico本质上只是一个使用类似jquery的语法操作HTML文档的库,使用cherrico爬取数据,只是请求到静态的HTML文档,如果网页内部的数据是通过ajax动态获取的,那么便爬去不到的相应的数据。而Puppeteer能够模拟一个浏览器的运行环境,能够请求网站信息,并运行网站内部的逻辑。然后再通过WS协议动态的获取页面内部的数据,并能够进行任何模拟的操作(点击、滑动、hover等),并且支持跳转页面,多页面管理。甚至能注入node上的脚本到浏览器内部环境运行,总之,你能对一个网页做的操作它都能做,你不能做的它也能做。
例子:
爬取网页的数据,并把数据保存到数据库
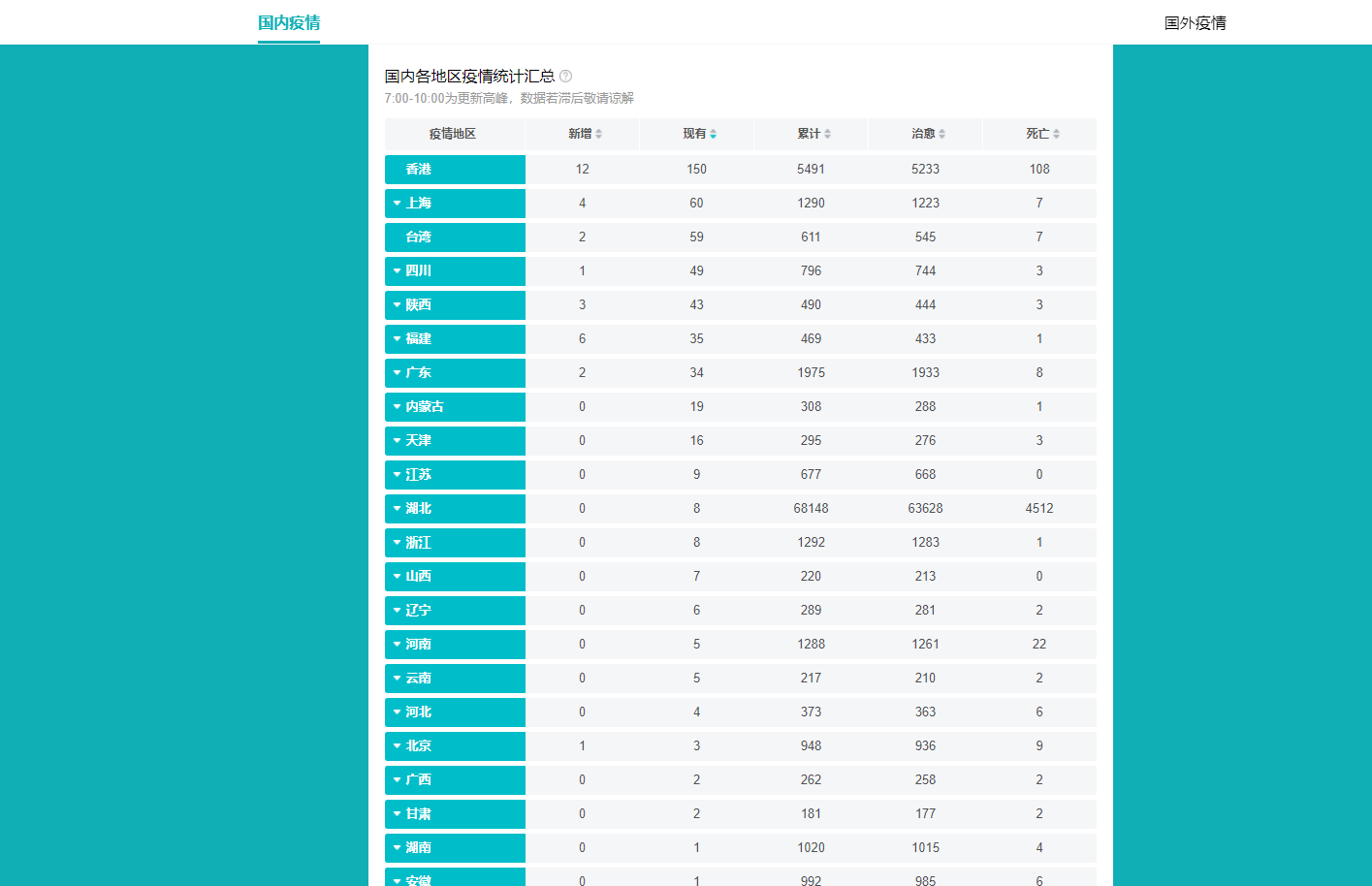
//爬取疫情数据
const chalk = require("chalk")
const fs = require("fs")
const puppeteer = require('puppeteer');
const mysql = require("mysql");
//数据库信息根据自己的情况来配
const sqlInfo = {
host: '***.***.***.***',
user: 'root',
password: 'root',
database: '****',
port: 3306
};
// 创建mysql数据库连接
const con = mysql.createConnection(sqlInfo);
// 连接数据库
con.connect();
puppeteer.launch({
headless: false, //不使用无头模式使用本地可视化
//executablePath: "./Chromium/chrome-win/chrome.exe", //因为是yarn add puppeteer --ignore-scripts没有安装chromium,需要制定本地chromium的chrome.exe路径所在,刚才下载后解压后的全路径
//设置超时时间
timeout: 15000,
//如果是访问https页面 此属性会忽略https错误
ignoreHTTPSErrors: true,
// 打开开发者工具, 当此值为true时, headless总为false
devtools: true,
}).then(async browser => {
const page = await browser.newPage()
await page.goto('https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner', { waitUntil: "networkidle2" })
const moreBtn = await page.$(".Common_1-1-287_3lDRV2");
await moreBtn.click();
await page.waitForSelector('.VirusTable_1-1-287_3m6Ybq');
const data = await page.$$eval('.VirusTable_1-1-287_3m6Ybq', data => {
return data.map(a => {
return {
'area_name': a.children[0].children[0].children[1].innerText,
'newAdd': a.children[1].innerText,
'nowHas': a.children[2].innerText,
'total': a.children[3].innerText,
'cure': a.children[4].innerText,
'death': a.children[5].innerText,
}
});
});
let json = JSON.stringify(data,null,2)
console.log(chalk.green("所有数据抓取完毕:\n", json))
fs.writeFile('YQ.json', json, 'utf8', function(error){
if(error){
console.log(chalk.green(error));
return false;
}
console.log(chalk.blue('数据写入文件成功!'));
})
await browser.close()
// 开始插入数据库了
for(let i = 0;i<data.length;i++){
con.query("insert into yiqing(area, newAdd, nowHas, total, cure, death) values(?,?,?,?,?,?)",
[
data[i].area_name,
data[i].newAdd,
data[i].nowHas,
data[i].total,
data[i].cure,
data[i].death
],function(err) {
//这里呢,插入很可能出错,所以还是要走个形式判断一下嘛(虽然可能性基本为0只要数据库能连接上)
if (err) {
//输出错误
console.log(err);
} else {
//到这里,一条数据就插入成功了
console.log(chalk.blue('第'+(i+1)+'条数据成功插入数据库'));
}
});
}
}).catch(err => console.log(err))
爬到的数据:
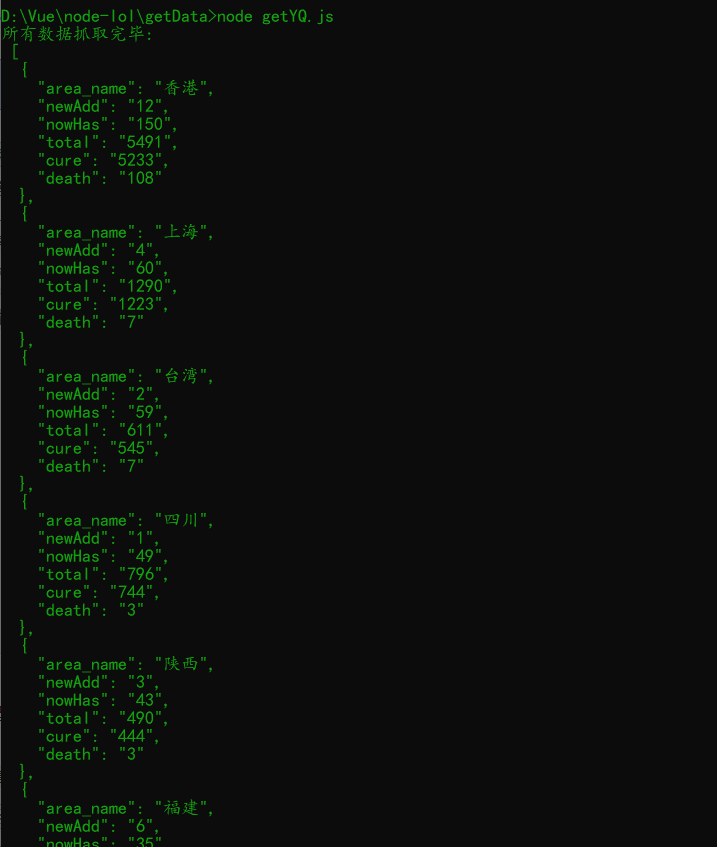
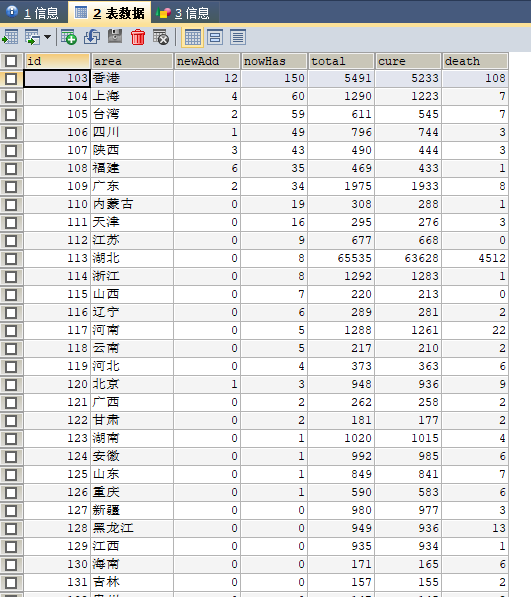
写入到数据库中的数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号