
Linux性能分析工具Perf
Linux性能分析工具Perf
介绍
Perf全名是Performance Event,是在Linux 2.6.31以后内建的系统效能分析工具,依靠perf,应用程式可以利用PMU (Performance Monitoring Unit), tracepoint和核心内部的特殊计数器(counter)来进行统计,另外还能同时分析运行中的核心程式码,从而更全面了解应用程式中的效能瓶颈。
perf基本原理是对目标进行取样,纪录特定的条件下所侦测的事件是否发生以及发生的次数。例如根据tick中断进行取样,即在tick中断内触发取样点,在取样点里判断行程(process)当时的context。假如一个行程90%的时间都花费在函式foo()上,那么90%的取样点都应该落在函式foo()的上下文中。
Perf 可取样的事件非常多,可以分析:
- Hardware event,如cpu-cycles、instructions 、cache-misses、branch-misses
- Software event,如page-faults、context-switches
- Tracepoint event
知道了cpu-cycles、instructions 我们可以了解Instruction per cycle 是多少,进而判断程式码有没有好好利用CPU,cache-misses 可以晓得是否有善用Locality of reference ,branch-misses 多了是否导致严重的pipeline hazard ?另外Perf 还可以对函式进行采样,了解效能卡在哪边。
perf的基本原理
Perf 是内置于 Linux 内核源码树中的性能剖析(profiling)工具。它基于事件 采样原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性 能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位。
我们先通过一个例子来看看 perf 究竟能干什么。程序[code1]是一个简单的 计算 pi 的计算密集型程序。很显然,[code1]的热点在函数 do_pi()中
#include <stdio.h>
#include <math.h>
#include <sys/types.h>
#include <linux/unistd.h>
int do_pi(){
double mypi,h,sum,x;
long long n,i;
n = 5000000;
h = 1.0 / n;
sum=0.0;
for (i = 1; i <= n; i+=1 ) { x = h * (i ‐ 0.5); sum += 4.0 / (1.0 + pow(x,2));
}
mypi = h * sum;
return 0;
}
int main()
{
printf("pid: %d\n", getpid());
sleep(8);
do_pi();
return 0;
}
运行[code1]后,根据程序显示的 pid 在命令行中执行:
$perf top ‐p $pid
该命令利用默认的性能事件”cycles”对[code1]进行热点分析。”cycles”是处理 器周期事件。这条命令能够分析出消耗处理器周期最多的代码,在处理器频率稳 定的前提下,我们可以认为 perf 给出热点代码的就是消耗时间最多的代码段。 执行上述命令后,Perf 会给出如下结果:

从图 上可以看到,在[code1]执行期间,函数 do_pi()消耗了 99.54%的 CPU 周期,是消耗处理器周期最多的热点代码。这跟我们预想的一样。
那么 perf 是怎么做到的呢?首先,perf 会通过系统调用 sys_perf_event_open 在内核中注册一个监测“cycles”事件的性能计数器。内核根据 perf 提供的信息在 PMU 上初始化一个硬件性能计数器(PMC: Performance Monitoring Counter)。PMC 随着 CPU 周期的增加而自动累加。在 PMC 溢出时,PMU 触发一个 PMI (Performance Monitoring Interrupt)中断。内核在 PMI 中断的处理函数中保存 PMC 的计数值,触发中断时的指令地址(Register IP:Instruction Pointer),当前 时间戳以及当前进程的 PID,TID,comm 等信息。我们把这些信息统称为一个采 样(sample)。内核会将收集到的 sample 放入用于跟用户空间通信的 Ring Buffer。 用户空间里的 perf 分析程序采用 mmap 机制从 ring buffer 中读入采样,并对其解 析。perf 根据 pid,comm 等信息可以找到对应的进程。根据 IP 与 ELF 文件中的 符号表可以查到触发 PMI 中断的指令所在的函数。为了能够使 perf 读到函数名, 我们的目标程序必须具备符号表。如果读者在 perf 的分析结果中只看到一串地 址,而没有对应的函数名时,通常是由于在编译时利用 strip 删除了 ELF 文件中 的符号表。建议读者在性能分析阶段,保留程序中的 symbol table,debug info 等信息。 根据上述的 perf 采样原理可以得知,perf 假设两次采样之间,即两次相邻 的 PMI 中断之间系统执行的是同一个进程的同一个函数。这种假设会带来一定 的误差,当读者感觉 perf 给出的结果不准时,不妨提高采样频率,perf 会给出更 加精确的结果
perf的功能概述
Perf 是一个包含 22 种子工具的工具集,功能很全面。表 1 给出了各个子 工具的功能描述。
| 1 | annotate | 根据数据文件,注解被采样到的函数,显示指令级别的 热点。 |
|---|---|---|
| 2 | archive | 根据数据文件中记录的 build‐id,将所有被采样到的 ELF 文件打成压缩包。利用此压缩包,可以在任何机器上分 析数据文件中记录的采样数据 |
| 3 | bench | Perf 中内置的 benchmark,目前包括两套针对调度器和 内存管理子系统的 benchmark。 |
| 4 | buildid‐cache | 管理 perf 的 buildid 缓存。每个 ELF 文件都有一个独一 无二的 buildid。Buildid 被 perf 用来关联性能数据与 ELF文件。 |
| 5 | buildid‐list | 列出数据文件中记录的所有 buildid。 |
| 6 | diff | 对比两个数据文件的差异。能够给出每个符号(函数) 在热点分析上的具体差异。 |
| 7 | evlist | 列出数据文件中的所有性能事件。 |
| 8 | inject | 该工具读取 perf record 工具记录的事件流,并将其定向 到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。 |
| 9 | kmem | 针对内存子系统的分析工具。 |
| 10 | kvm | 此工具可以用来追踪、测试运行于 KVM 虚拟机上的 Guest OS。 |
| 11 | list | 列出当前系统支持的所有性能事件。包括硬件性能事 件、软件性能事件以及检查点。 |
| 12 | lock | 分析内核中的加锁信息。包括锁的争用情况,等待延迟 等。 |
| 13 | record | 收集采样信息,并将其记录在数据文件中。随后可通过 其它工具对数据文件进行分析。 |
| 14 | report | 读取 perf record 创建的数据文件,并给出热点分析结果。 |
| 15 | sched | 针对调度器子系统的分析工具。 |
| 16 | script | 执行 perl 或 python 写的功能扩展脚本、生成脚本框架、 读取数据文件中的数据信息等。 |
| 17 | stat | 剖析某个特定进程的性能概况,包括 CPI、Cache 丢失 率等。 |
| 18 | test | Perf 对当前软硬件平台的测试工具。可以用此工具测试 当前的软硬件平台(主要是处理器型号和内部版本)是 否能支持 perf 的所有功能。 |
| 19 | timechart | 生成一幅描述处理器与各进程状态变化的矢量图。 |
| 20 | top | 类似于 Linux 的 top 命令,对系统性能进行实时分析。 |
| 21 | trace | strace inspired tool. |
| 22 | probe | 用于定义动态检查点。 |
某些需要特定内核支持的命令可能无法使用。如果想获得每个子命令的具体选项列表,只需输入命令名紧随其后 - h :
perf stat -h
usage: perf stat [<options>] [<command>]
-e, --event <event> event selector. use 'perf list' to list available events
-i, --no-inherit child tasks do not inherit counters
-p, --pid <n> stat events on existing process id
-t, --tid <n> stat events on existing thread id
-a, --all-cpus system-wide collection from all CPUs
-c, --scale scale/normalize counters
-v, --verbose be more verbose (show counter open errors, etc)
-r, --repeat <n> repeat command and print average + stddev (max: 100)
-n, --null null run - dont start any counters
-B, --big-num print large numbers with thousands' separators
perf list工具和性能事件
Perf工具支持一系列的可测量事件。这个工具和底层内核接口可以测量来自不同来源的事件。 例如,一些事件是纯粹的内核计数,在这种情况下的事件被称为软事件 ,例如:context-switches、minor-faults。
另一个事件来源是处理器本身和它的性能监视单元(PMU)。它提供了一个事件列表来测量微体系结构的事件,如周期数、失效的指令、一级缓存未命中等等。 这些事件被称为PMU硬件事件或简称为硬件事件。 它们因处理器类型和型号而异。
perf_events接口还提供了一组通用的的硬件事件名称。在每个处理器,这些事件被映射到一个CPU的真实事件,如果真实事件不存在则事件不能使用。可能会让人混淆,这些事件也被称为硬件事件或硬件缓存事件 。
最后,还有由内核ftrace基础实现的tracepoint事件。但只有2.6.3x和更新版本的内核才提供这些功能。
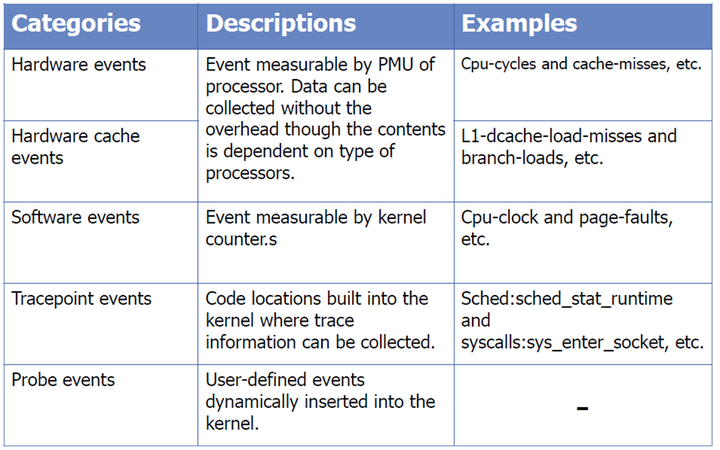
可以通过命令获得可支持的事件列表:
perf list
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
cache-references [Hardware event]
cache-misses [Hardware event]
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cpu-clock [Software event]
task-clock [Software event]
page-faults OR faults [Software event]
minor-faults [Software event]
major-faults [Software event]
context-switches OR cs [Software event]
cpu-migrations OR migrations [Software event]
alignment-faults [Software event]
emulation-faults [Software event]
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
L1-dcache-prefetches [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-icache-loads [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
L1-icache-prefetches [Hardware cache event]
L1-icache-prefetch-misses [Hardware cache event]
LLC-loads [Hardware cache event]
LLC-load-misses [Hardware cache event]
LLC-stores [Hardware cache event]
LLC-store-misses [Hardware cache event]
LLC-prefetch-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-prefetches [Hardware cache event]
dTLB-prefetch-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
iTLB-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
branch-load-misses [Hardware cache event]
rNNN (see 'perf list --help' on how to encode it) [Raw hardware event descriptor]
mem:<addr>[:access] [Hardware breakpoint]
kvmmmu:kvm_mmu_pagetable_walk [Tracepoint event]
[...]
sched:sched_stat_runtime [Tracepoint event]
sched:sched_pi_setprio [Tracepoint event]
syscalls:sys_enter_socket [Tracepoint event]
syscalls:sys_exit_socket [Tracepoint event]
[...]
一个事件可以有子事件(或掩码)。 在某些处理器上的某些事件,可以组合掩码,并在其中一个子事件发生时进行测量。最后,一个事件还可以有修饰符,也就是说,通过过滤器可以改变事件被计数的时间或方式。
软件事件实现方法
- OS为每个软件事件定义一个计数器(可以理解为一个内存变量)
- 这样定义的计数器实际上是无限的(OS可以自己随意定义,只要存储空间足够)
- 每个软件事件和计数器就是一一对应关系
- 每个软件事件发生时OS简单对分配的计数器累加

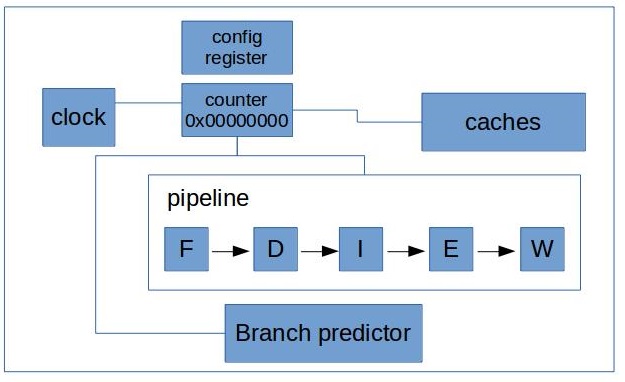
硬件事件实现方法
需要硬件性能计数器(PMC)支持
-
系统时钟和一个计数器(寄存器)构成一个简单cycle计数器
-
计数器和Cache连接计数Cache事件(访问、失效)
-
计数器和分支预测器连接计数分支预测事件
-
计数器一般是有限的通过配置寄存器控制和哪个部件连接计数
引用自:https😕/easyperf.net/blog/2018/06/01/PMU-counters-and-profiling-basics
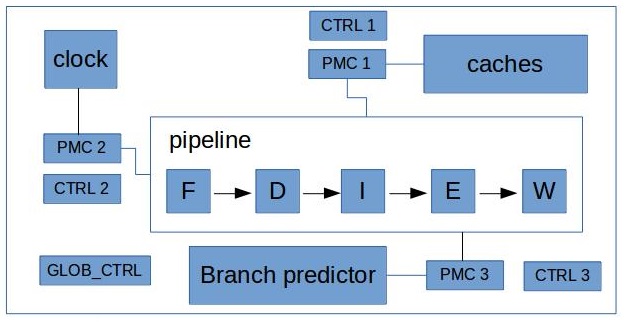
硬件性能事件由处理器中的 PMU 提供支持。如前文所述,perf 会对 PMI 中 断发生时的 PC 寄存器进行采样。由于现代处理器的主频非常高,再加上深度流 水线机制,从性能事件被触发,到处理器响应 PMI 中断,流水线上可能已处理 过数百条指令。那么 PMI 中断采到的指令地址就不再是触发性能事件的那条指 令的地址了,而且可能具有非常严重的偏差。为了解决这个问题,Intel 处理器通 过 PEBS 机制实现了高精度事件采样。PEBS 通过硬件在计数器溢出时将处理器现 场直接保存到内存(而不是在响应中断时才保存寄存器现场),从而使得 perf 能够采到真正触发性能事件的那条指令的地址,提高了采样精度。在默认条件下, perf 不使用 PEBS 机制。用户如果想要使用高精度采样,需要在指定性能事件时, 在事件名后添加后缀”:p”或”:pp”。如:
$perf top ‐e cycles:pp
Perf 在采样精度上定义了 4 个级别,如表 2 所示。
| 0 | 无精度保证 |
|---|---|
| 1 | 采样指令与触发性能事件的指令之间的偏差为常数(:p) |
| 2 | 需要尽量保证采样指令与触发性能事件的指令之间的偏差为 0(:pp) |
| 3 | 保证采样指令与触发性能事件的指令之间的偏差必须为 0(:ppp) |
目前的 X86 处理器,包括 Intel 处理器与 AMD 处理器均仅能实现前 3 个精 度级别。 除了精度级别以外,性能事件还具有其它几个属性,均可以通过”event:X” 的方式予以指定。
性能事件的属性:
| u | 仅统计用户空间程序触发的性能事件。 |
|---|---|
| k | 仅统计内核触发的性能事件。 |
| h | 仅统计 Hypervisor 触发的性能事件。 |
| G | 在 KVM 虚拟机中,仅统计 Guest 系统触发的性能事件。 |
| H | 仅统计 Host 系统触发的性能事件。 |
| p | 精度级别 |
使用perf stat进行统计
在处理性能优化问题时,最好的思路是自顶而下,首先要从整体上了解程序运行时的统计信息,perf stat正是提供概括精简的信息,这些信息被用于分析系统/进程的整体性能概况。对任何支持的事件,perf能够在进程执行阶段对这些事件进行计数 。在计数模式下,出现的事件将会被统计并在进程结束后打印出来。
参数设置
-e:选择性能事件
-i:禁止子任务继承父任务的性能计数器。
-r:重复执行 n 次目标程序,并给出性能指标在n 次执行中的变化范围。
-n:仅输出目标程序的执行时间,而不开启任何性能计数器。
-a:指定全部cpu
-C:指定某个cpu
-A:将给出每个处理器上相应的信息。
-p:指定待分析的进程id
-t:指定待分析的线程id
‘‐e’ or ‘‐‐event’
‘‐‐filter’
‘‐i’ or ‘‐‐no‐inherit’:禁止子任务继承父任务的性能计数器。类似于’perf top’中的’‐i’参数,只是此 处是禁止继承机制。
‘‐c’ or ‘‐‐scale’:要求底层驱动记录计数器的 run 与 enabled 时间。此选项默认打开,且不能关闭。
‘‐r’ or ‘‐‐repeat’
$perf stat ‐r 10 ls > /dev/null

与执行一次目标程序相比,重复执行n次目标程序多了一列统计信息。括号里的百分比为 n 个性能数据 的标准差与数学期望的比值。这个值越大,表示各样本与平均值之间的偏差就越 大,也就是说样本的波动幅度就越大。
‘‐v’ or ‘‐‐verbose’:开启此选项后,perf stat 将显示更丰富的信息,比如打开计数器时系统报出的错误信息,各个计数器的计数值、运行时间与使能时间等信息。
‘‐n’ or ‘‐‐null’:开启这个选项后,perf stat 仅仅输出目标程序的执行时间,而不开启任何性 能计数器。
执行命令:
$perf stat ‐n ls > /dev/null
perf stat 将给出如下图所示的信息。

perf stat 通过系统调用 clock_gettime(CLOCK_MONOTONIC, &ts)记录目标程序 的执行时间,而没有利用任何性能计数器。
‘‐d’ or ‘‐‐detailed’:开启该选项后,perf stat 将给出更丰富的性能指标。
执行命令:
$perf stat ‐d ls > /dev/null
perf stat 将给出如下图所示的信息。


与前图相比,开启’‐d’选项后,perf stat 给出了’L1‐dcache‐loads’等 Cache 相关 的性能指标。
‘‐S’ or ‘‐‐sync’:在执行目标程序前,先执行系统调用 sync(),将内存缓冲区中的数据写回磁 盘。从而使得目标程序在执行时能够获得更干净的环境。
‘‐A’ or ‘‐‐no‐aggr’:此选项必须与’‐a’选项一起使用。开启此选项后,perf stat 将给出每个处理器 上相应的信息。
perf stat 给出的信息如下图所示。

‘‐x’ or ‘‐‐field‐separator’:如果希望将 perf stat 的信息导进数据库,或者希望利用某些文本分析工具对 输出信息进行分析,就需要获得格式化的输出结果。’‐x’参数能够满足这项需求。 如果我们希望各项输出信息之间通过‘;’分隔,可以采用如下命令:
$perf stat ‐x ‘;’ ls > /dev/null
perf stat 的输出信息如下图所示。

‘‐o’ or ‘‐‐output’ :可以通过此选项将 perf stat 的结果输出到指定文件。
‘‐‐append’:以追加模式,将输出信息写入输出文件。
‘‐‐pre’
‘‐‐post’
事件分析
默认采集事件:
在没有指定特定事件时,perf stat收集了以下的普通事件:
-
task‐clock:任务真正占用的处理器时间,单位为ms。CPUs utilized = task-clock / time elapsed,CPU的占用率。
CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
-
context-switches:系统发生上下文切换的次数
进程切换次数,记录了程序运行过程中发生了多少次进程切换,一般来说,频繁的进程切换有可能只是CPU正常调度下一个任务,也有可能是一些性能问题的外在表现,导致的原因可能是锁竞争,IO阻塞,硬件中断等。如果可能,频繁的进程切换是应该避免的。 -
CPU-migrations:处理器迁移次数。
Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。
-
page-faults:缺页异常的次数。
当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
-
cycles:是程序消耗的处理器周期数
处理器时钟,一条机器指令可能需要多个 cycles。
-
instructions:是指命令执行期间产生的处理器指令数
IPC为平均每个cpu cycle执行了多少条指令。
-
branches:是指程序在执行期间遇到的分支指令数。
遇到的分支指令数。branch-misses是预测错误的分支指令数。
-
branch‐misses是预测错误的分支指令数。
其中一些是软件事件,例如context-switches,其他一些是硬件事件,例如cycles。而task-clock (msec)表示了该程序对cpu的利用情况。据此可将程序分为IO型和CPU型,所对应的性能优化方案也不同。
-
XXX seconds time elapsed系程序持续时间
-
任务执行时间/任务持续时间大于1,那可以肯定是多核引起的
详细分析
$perf stat ls
上述命令给出的性能概况如下图所示。

从图上可以看到,perf stat 工具利用 10 个典型性能事件剖析了应用程序。
task‐clock 事件表示目标任务’ls’真正占用处理器的时间,单位是毫秒。我们将其 称为任务执行时间。如上图所示,’ls’在处理器上执行了近 4 毫秒。“0.256 CPUs utilized”表示目标任务的处理器占用率。处理器占用率表示目标任务的执行时间 与持续时间的比值。持续时间是指从任务提交到执行结束之间的总时间。对操作 系统有过了解的读者应该知道,Linux 这种多任务分时操作系统中,一个任务不 太可能在执行期间始终占据处理器。操作系统会根据调度策略(linux 目前使用 CFS 调度算法)合理安排各个任务轮流使用处理器,每次调度会产生一次上下文 切换。在此期间操作系统还需处理大量中断。因此,一个任务的执行时间可能会 很短,但是它的持续时间会远高于此(除非此任务是优先级最高的实时任务)。以上图中的例子来说,’ls’的执行时间为 3.98 毫秒,而持续为 15.58 毫秒,处理 器占用率为 0.256。在此期间,系统共发生了 45 次上下文切换。平均每秒发生 0.011*106 次。上下文切换次数的均值是上下文切换次数与任务执行时间的比值。
在多(核)处理器系统中,Linux 为了维持各个处理器的负载均衡,会在特 定条件下将某个任务从一个处理器迁往另外一个处理器(cpu-miogrations)。此时,我们便说发生了 一次处理器迁移。从图 16 上看到,ls 在执行期间没有被操作系统迁移过。
Linux 的内存管理子系统采用了分页机制。当应用程序请求的页面尚未建立、 请求的页面不在内存中、或者请求的页面虽然在内存中,但尚未建立物理地址与 虚拟地址的映射关系时,都会触发一次缺页异常(page‐fault)。内核在捕获缺页 异常时,根据异常种类进行相应的处理。另外,TLB 不命中,页面访问权限不匹 配等情况也会触发缺页异常。
内核中对 page faults (PERF_COUNT_SW_PAGE_FAULTS)事件的精确定义是缺页 异常的处理函数 do_page_fault()被执行。程序’ls’在执行期间共触发了 320 次缺页 异常。平均发生率为每秒 0.08*106 次。
‘cycles’为’ls’程序消耗的处理器周期数。如果将被’ls’占据的那部分时间看作一 个抽象处理器,它的主频只需为 0.75GHz 便可以在 3.98 毫秒内完成’ls’命令的处 理。
‘instructions’是指命令’ls’执行期间产生的处理器指令数。IPC(instructions perf cycle)为 0.69。IPC 是评价处理器与应用程序性能的重要指标。在 X86 这种 CSIC 处理器上,很多指令需要多个处理器周期才能执行完毕。另外,有些指令在流水 线上未必能成功引退(retired),从而形成无效指令。长指令与无效执行越多,IPC 就越低,处理器的利用率与程序的执行效率也就越低。因此,IPC 在一定程度下, 让我们对程序的执行效率有一个宏观认识。
‘branches’是指程序在执行期间遇到的分支指令数。’branch‐misses’则是预测 错误的分支指令数。绝大多数现代处理器都具有分支预测与 OOO(Out‐of‐Order) 执行机制,以充分利用 CPU 内部的资源,减少流水线停顿周期。当处理器遇到 分支指令时,正常来说,需要等待分支条件计算完毕才能知道后续指令流该往何 处跳转。这就导致在等待分支条件计算期间,流水线上出现若干周期的停顿(流 水线 Hazard)。体系结构的经典著作《计算机体系结构:量化研究方法》上说, 分支指令产生的性能影响为 10%~30%[2],流水线越长,性能影响就越大。为了减 少分支指令造成的流水线停顿,从 P5 处理器开始引入了分支预测机制。当处理 器无法判断指令的跳转方向时,便通过分支预测单元选择一个最有可能的跳转方 向。但是,既然是预测,就存在预测失败的可能。当分支预测失败时,会对处理 器周期造成较大的浪费。在 5 发射 10 级流水线的处理器中,当分支预测的准确 率为 90%时,处理器带宽会浪费 47%;而如果准确率提高到 96%,带宽浪费可降 低至 26%[3]。Core i7 以及 Xeon 5500 等较新的处理器在分支预测失效时,已经无 需刷新全部流水线,但错误指令加载与计算导致的无效开销依然不可小觑。这就 要求我们在编写代码时,应尽量减少分支预测错误的次数。但在此之前,通过 perf stat,perf top,perf record 等工具查查分支预测失效率,以及导致分支预测 失效过高的热点代码是非常有必要的。’branch misses’一行中的’***% of all branches’即为目标程序执行期间的分支预测失效率。
用例
#指定命令的CPU计数器统计信息:
perf stat command
#指定PID的CPU计数器统计信息,直到Ctrl-C:
perf stat -p PID
#整个系统的CPU计数器统计,持续5秒:
perf stat -a sleep 5
#系统范围内的各种基本CPU统计信息,持续10秒:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles -a sleep 10
#指定命令的各种CPU一级数据缓存统计信息:
perf stat -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores command
#指定命令的各种CPU数据TLB统计信息:
perf stat -e dTLB-loads,dTLB-load-misses,dTLB-prefetch-misses command
#指定命令的各种CPU最后一级缓存统计信息:
perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-prefetches command
#统计系统范围内每秒的系统调用次数:
perf stat -e raw_syscalls:sys_enter -I 1000 -a
#按指定PID的类型统计系统调用,直到Ctrl-C:
perf stat -e'syscalls:sys_Enter_*'-p PID
#按类型统计整个系统的系统调用,持续5秒:
perf stat -e 'syscalls:sys_enter_*' -a sleep 5
#统计指定PID的调度程序事件,直到Ctrl-C:
perf stat -e 'sched:*' -p PID
#统计指定PID的调度程序事件,持续10秒:
perf stat -e 'sched:*' -p PID sleep 10
#统计整个系统的ext4事件,持续10秒:
perf stat -e 'ext4:*' -a sleep 10
#统计整个系统的块设备I/O事件,持续10秒:
perf stat -e 'block:*' -a sleep 10
使用Perf record记录采样
参数
-p:指定待分析进程的 pid(可以是多个,用,分隔列表)
-t:指定待分析线程的 tid(可以是多个,用,分隔列表)
-u:指定收集的用户数据,uid为名称或数字
-a:从所有 CPU 收集系统数据
-g:开启 call-graph (stack chain/backtrace) 记录
-C:只统计指定 CPU 列表的数据,如:0,1,3或1-2
-r :perf 程序以SCHED_FIFO实时优先级RT priority运行;这里填入的数值越大,进程优先级越高(即 nice 值越小)
-c: 事件每发生 count 次采一次样
-F:每秒采样 n 次
-o:指定输出文件output.data,默认输出到perf.data
示例
#采样指定PID的CPU堆栈跟踪(通过帧指针),以99赫兹,持续10秒:
perf record -F 99 -p PID -g -- sleep 10
#采样PID的CPU堆栈跟踪,使用dwarf以99赫兹展开堆栈,持续10秒:
perf record -F 99 -p PID --call-graph dwarf sleep 10
perf record -e cycles -g -o ./perf.data -F 1000 ./xxx
使用perf report分析采样
perf record收集的样本会保存到一个二进制文件中,默认情况下,该文件名为perf.data。perf report命令读取此文件并生成简明的执行概要文件。默认情况下,样本按函数排序,样本数最多的优先。可以自定义排序顺序,从而以不同的方式查看数据。
参数设置:
-i:输入的数据文件
-v:显示每个符号的地址
-d <dos>:只显示指定dos的符号
-C:只显示指定comm的信息(Comm. 触发事件的进程名)
-U:只显示已解析的符号
-c:只显示指定cpu采样信息
-M:以指定汇编指令风格显示
–source:以汇编和source的形式进行显示
-p<regex>:用指定正则表达式过滤调用函数
-n: 显示每个符号对应的事件数
--comms=<comm>: 只显示指定 comm 的信息
-S <symbol name>: 只考虑指定符号
-g [type,min]:按照 [type,min] 指定的方式显示函数调用图
type: flat - 线性展开所有调用链
graph – 显示调用树,并显示每个调用树对应的绝对开销率
fractal – 显示调用树,并显示每个调用树对应的相对开销率
min: 只显示开销率大于 min 的符号
flat:

graph:
fractal:
perf report
# Events: 1K cycles
#
# Overhead Command Shared Object Symbol
# ........ ............... .............................. .....................................
#
28.15% firefox-bin libxul.so [.] 0xd10b45
4.45% swapper [kernel.kallsyms] [k] mwait_idle_with_hints
4.26% swapper [kernel.kallsyms] [k] read_hpet
2.13% firefox-bin firefox-bin [.] 0x1e3d
1.40% unity-panel-ser libglib-2.0.so.0.2800.6 [.] 0x886f1
[...]
“Overhead”列指示在相应函数中收集的总样本的百分比。第二列显示被收集样本的进程。在per-thread/per-process模式下,这始终是受监视命令的名称。但在cpu-wide模式下,命令可能会有所不同。第三列显示了样本来源的ELF镜像的名称。如果程序是动态链接的,则这可能会显示共享库的名称。当样本来自内核时,使用伪ELF镜像名[kernel.kallsyms]。第四列指示样本运行的级别,也就是程序被中断时正在运行的级别,最后一列显示了符号名称。
样本可以使用多种方式进行呈现,即使用排序。例如按共享对象进行排序,使用dso:
perf report --sort=dso
# Events: 1K cycles
#
# Overhead Shared Object
# ........ ..............................
#
38.08% [kernel.kallsyms]
28.23% libxul.so
3.97% libglib-2.0.so.0.2800.6
3.72% libc-2.13.so
3.46% libpthread-2.13.so
2.13% firefox-bin
1.51% libdrm_intel.so.1.0.0
1.38% dbus-daemon
1.36% [drm]
[...]
输出控制选项
为使输出更容易解析,可以修改列分隔符为某一个字符:
perf report -t
内核报告控制选项
Perf工具不知道如何从压缩内核映像(vmlinuz)中提取符号。因此,用户必须将非压缩内核镜像的路径通过 -k 传递给Perf:
perf report -k /tmp/vmlinux
当然,内核镜像只有带debug符号编译的才能工作。
Processor-wide模式
在per-cpu的模式中,会从监控CPU上的所有线程上记录的样本。 这样,我们可以收集来自许多不同进程的样本。例如,如果我们监视所有CPU 5s:
perf record -a sleep 5
perf report
# Events: 354 cycles
#
# Overhead Command Shared Object Symbol
# ........ ............... .......................... ......................................
#
13.20% swapper [kernel.kallsyms] [k] read_hpet
7.53% swapper [kernel.kallsyms] [k] mwait_idle_with_hints
4.40% perf_2.6.38-8 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
4.07% perf_2.6.38-8 perf_2.6.38-8 [.] 0x34e1b
3.88% perf_2.6.38-8 [kernel.kallsyms] [k] format_decode
[...]
当符号打印为十六进制地址时,这是因为ELF镜像没有符号表。当二进制文件被剥离时就会发生这种情况。我们也可以按cpu排序。这可能有助于确定工作负载是否平衡:
perf report --sort=cpu
# Events: 354 cycles
#
# Overhead CPU
# ........ ...
#
65.85% 1
34.15% 0
计算开销
perf收集调用链时,开销可以在两列中显示为“Children”和“Self”。“self”开销只是通过所有入口(通常是一个函数,也就是符号)的所有周期值相加来计算的。这是perf传统显示方式,所有“self”开销值之和应为100%。
children”开销是通过将子函数的所有周期值相加来计算的,这样它就可以显示更高级别函数的总开销,即使它们不直接参与更多的执行。这里的“Children”表示从另一个(父)函数调用的函数。
所有“children”开销值之和超过100%可能会令人困惑,因为它们中的每一个已经是其子函数的“self”开销的累积。但是如果启用了这个功能,用户可以找到哪一个函数的开销最大,即使样本分布在子函数上。
考虑下面的例子,有三个函数如下所示。
void foo(void) {
/* do something */
}
void bar(void) {
/* do something */
foo();
}
int main(void) {
bar()
return 0;
}
在本例中,“foo”是“bar”的子级,“bar”是“main”的直接子级,因此“foo”也是“main”的子级。换句话说,“main”是“foo”和“bar”的父级,“bar”是“foo”的父级。
假设所有样本都只记录在“foo”和“bar”中。当使用调用链记录时,输出将在perf report的常规(仅自开销)输出中显示如下内容:
Overhead Symbol
........ .....................
60.00% foo
|
--- foo
bar
main
__libc_start_main
40.00% bar
|
--- bar
main
__libc_start_main
启用--children选项时,子函数(即'foo'和'bar')的'self'开销值将添加到父函数中,以计算'children'开销。在这种情况下,报告可以显示为:
Children Self Symbol
........ ........ ....................
100.00% 0.00% __libc_start_main
|
--- __libc_start_main
100.00% 0.00% main
|
--- main
__libc_start_main
100.00% 40.00% bar
|
--- bar
main
__libc_start_main
60.00% 60.00% foo
|
--- foo
bar
main
__libc_start_main
在上述输出中,“foo”的“self”开销(60%)被添加到“bar”、“main”和“__libc_start_main”的“children”开销中。同样,“bar”的“self”开销(40%)添加到“main”和“libc”的“children”开销中。
因此,首先显示'__libc_start_main'和'main',因为它们有相同(100%)的“子”开销(即使它们没有“自”开销),并且它们是'foo'和'bar'的父级。
从v3.16开始,默认情况下会显示“children”开销,并按其值对输出进行排序。通过在命令行上指定--no-children选项或在perf配置文件中添加“report.children=false”或“top.children=false”,禁用“children”开销。
使用perf annotate分析源码
可以使用perf annotate深入到指令级分析。为此,需要使用要解析的命令的名称调用perf annotate。所有带样本的函数都将被反汇编,每条指令都将报告其样本的相对百分比:
perf record ./noploop 5
perf annotate -d ./noploop
------------------------------------------------
Percent | Source code & Disassembly of noploop.noggdb
------------------------------------------------
:
:
:
: Disassembly of section .text:
:
: 08048484 <main>:
0.00 : 8048484: 55 push %ebp
0.00 : 8048485: 89 e5 mov %esp,%ebp
[...]
0.00 : 8048530: eb 0b jmp 804853d <main+0xb9>
15.08 : 8048532: 8b 44 24 2c mov 0x2c(%esp),%eax
0.00 : 8048536: 83 c0 01 add $0x1,%eax
14.52 : 8048539: 89 44 24 2c mov %eax,0x2c(%esp)
14.27 : 804853d: 8b 44 24 2c mov 0x2c(%esp),%eax
56.13 : 8048541: 3d ff e0 f5 05 cmp $0x5f5e0ff,%eax
0.00 : 8048546: 76 ea jbe 8048532 <main+0xae>
[...]
第一列报告在该指令在捕获函数noploop()的样本百分比。如前所述,您应该仔细解读这些信息。
如果使用-ggdb编译应用程序,perf annotate可以生成源代码级信息。下面的代码片段显示了在使用此调试信息编译noploop时,同一次执行noploop时的更多信息输出。
------------------------------------------------
Percent | Source code & Disassembly of noploop
------------------------------------------------
:
:
:
: Disassembly of section .text:
:
: 08048484 <main>:
: #include <string.h>
: #include <unistd.h>
: #include <sys/time.h>
:
: int main(int argc, char **argv)
: {
0.00 : 8048484: 55 push %ebp
0.00 : 8048485: 89 e5 mov %esp,%ebp
[...]
0.00 : 8048530: eb 0b jmp 804853d <main+0xb9>
: count++;
14.22 : 8048532: 8b 44 24 2c mov 0x2c(%esp),%eax
0.00 : 8048536: 83 c0 01 add $0x1,%eax
14.78 : 8048539: 89 44 24 2c mov %eax,0x2c(%esp)
: memcpy(&tv_end, &tv_now, sizeof(tv_now));
: tv_end.tv_sec += strtol(argv[1], NULL, 10);
: while (tv_now.tv_sec < tv_end.tv_sec ||
: tv_now.tv_usec < tv_end.tv_usec) {
: count = 0;
: while (count < 100000000UL)
14.78 : 804853d: 8b 44 24 2c mov 0x2c(%esp),%eax
56.23 : 8048541: 3d ff e0 f5 05 cmp $0x5f5e0ff,%eax
0.00 : 8048546: 76 ea jbe 8048532 <main+0xae>
[...]
使用perf annotate分析内核
Perf工具不知道如何从压缩内核镜像(vmlinuz)中提取符号。正如perf report中的示例,用户必须通过-k 传递非压缩内核镜像的路径:
perf annotate -k /tmp/vmlinux -d symbol
在一次说明,这只使用带debug符号编译的内核。
使用perf top进行现场分析
Perf top工具主要用于实时剖析各个函数在某个性能事件上的热度。利用perf top,能够直观地观察到当前的热点函数,并利用工具中内置的annotate功能,进一步查找热点指令。
perf top界面

使用方法
perf top
该命令以默认性能事件“cycles(CPU 周期数)”进行全系统的性能剖析,检测系统中的所有应用程序函数与内核函数的热度。上图为上述命令的执行结果。
输出的结果为一个交互界面,在主界面中包含了四列数据,其含义如下:
- 第一列:为该符号引发的性能事件在整个监测域中占的比例,我们将其称为该符号的热度。监测域是指 perf 监控的所有符号。默认情况下包括系统中所有进程、 内核以及内核模块的函数。
- 第二列:符号所在的DSO(Dynamic Shared Object),可以是应用程序、内核、动态链接库、模块。
- 第三列:DSO的类型。perf 中 DSO 共有 5 种类型,分别是:ELF 可执行文件,动态链接库,内核,内核模块,VDSO 等。[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态链接库)。[k]表述此符号属于内核或模块。
- 第四列:符号名。有些符号不能解析为函数名,只能用地址表示。
在主界面中按下h即可调出键位帮助:

| 键位 | 说明 | 备注 |
|---|---|---|
| ENTER | Zoom into DSO/Threads & Annotate current symbol | 选择当前选项 |
| ESC | Zoom out | 回到上一级 |
| a | Annotate current symbol | 标记当前符号 |
| C | Collapse all callchains | 折叠所有调用链 |
| d | Zoom into current DSO | |
| E | Expand all callchains | 展开所有调用链 |
| F | Toggle percentage of filtered entries | |
| H | Display column headers | 显示列名 |
| L | Change percent limit | 修改百分比限制 |
| m | Display context menu | 显示内容菜单 |
| S | Zoom into current Processor Socket | |
| P | Print histograms to perf.hist.N | 打印perf.hist.N的柱形图 |
| t | Zoom into current Thread | |
| V | Verbose (DSO names in callchains, etc) | |
| z | Toggle zeroing of samples | |
| f | Enable/Disable events | 启用/禁用事件 |
| / | Filter symbol by name | 根据名称过滤符号 |
帮助窗口列出了 perf top 的所有功能。我们首先来看注解(Annotate)功能。 注解功能可以进一步深入分析某个符号。给出对应线程的代码并且为热点代码标 记出它们触发的性能事件在整个测试域中的百分比。下面让我们来看一下如何使 用注解功能。在界面上按上下键,将光标在各个 symbol 间移动。选定某个符号 后,按下 a 键,得到如下图所示的界面。

上图 显示的是[code1]中 do_pi()函数的注解。从图上可以看到 perf 对 do_pi() 中的 C 代码给出了汇编语言的注解。并且给出了各条指令的采样率。从图上可以 看到耗时较多的指令(如访存指令)比较容易被 perf 采到。
选定某个符号后按下热键’d’,perf 会过滤掉所有不属于此 DSO 的文件。以图 1 中的实验为例,符号 do_pi 归属的 DSO 为 thread。当在符号 do_pi 上按下’d’键 后,perf 过滤掉了所有不属于 thread 的符号。如下图所示。

类似于热键’d’,热键’t’能够过滤所有不属于当前符号所属线程的符号。
热键’P’可以将 perf top 的当前显示的信息输出到文件’perf.hist.XXX’中。
右方向键也是热键,它可以打开 perf top 的功能菜单。菜单上列出的各项功 能分别对应上述各个热键的功能。
参数设置
-e:指定性能事件
-a:显示在所有CPU上的性能统计信息
-C:显示在指定CPU上的性能统计信息
-p:指定进程PID
-t:指定线程TID
-K:隐藏内核统计信息
-U:隐藏用户空间的统计信息
-s:指定待解析的符号信息
‘‐G’ or‘‐‐call‐graph’ <output_type,min_percent,call_order>
graph: 使用调用树,将每条调用路径进一步折叠。这种显示方式更加直观。
每条调用路径的采样率为绝对值。也就是该条路径占整个采样域的比率。
fractal
默认选项。类似与 graph,但是每条路径前的采样率为相对值。
flat
不折叠各条调用
选项 call_order 用以设定调用图谱的显示顺序,该选项有 2个取值,分别是
callee 与caller。
将该选项设为callee 时,perf按照被调用的顺序显示调用图谱,上层函数被下层函数所调用。
该选项被设为caller 时,按照调用顺序显示调用图谱,即上层函数调用了下层函数路径,也不显示每条调用路径的采样率
注: Perf top需要root权限
‘‐e’ or ‘‐‐event’
‘‐c’ or ‘‐‐count’
‘‐p’ or ‘‐‐pid’
‘‐t’ or ‘‐‐tid’
‘‐a’ or ‘‐‐all‐cpus’:采集系统中所有 CPU 产生的性能事件。这也是 perf top 的默认情况。
‘‐C’ or ‘‐‐cpu’ $perf top ‐C 0,3
‘‐k’ or ‘‐‐vmlinux’
- /proc/kallsyms
- 用户通过’‐k’参数指定的路径。
- 当前路径下的“vmlinux”文件
- /boot/vmlinux
- /boot/vmlinux‐$(uts.release)
- /lib/modules/$(uts.release)/build/vmlinux
- /usr/lib/debug/lib/modules/$(uts.release)/build/vmlinux
‘‐K’ or ‘‐‐hide_kernel_symbols’:不显示属于内核的符号。对于只想分析应用程序的用户而言,使用此参数后, perf top 的界面会清爽很多。
‘‐m’ or ‘‐‐mmap‐pages’
默认情况下,mmap 的页面数量为 128,此时 mmap 内存区域的大小为 512KB。 perf top 默认每隔 2s 读取一次性能数据,当内核生成性能数据的速度过快时,就 可能因为缓冲区满而导致数据丢失,从而影响到分析结果。在此情况下,用户可 以通过’‐m’参数扩大缓冲区,以避免性能数据的大量丢失。
‘‐r’, ‘‐‐realtime’ $perf top ‐r 0
上述命令中,0 即为指定给分析程序的实时优先级。顺便说一句,Linux 中实时优先级的范围是[0,99],其中优先级 0 最高。不要与范围是[‐20,19]的 nice 值搞混。
‘‐d’ or ‘‐‐delay’ :指定 perf top 界面的刷新周期,的单位为秒。默认值为 2s。
‘‐D’ or ‘‐‐dump‐symtab’
perf top ‐‐stdio –D

上图给出了 perf top 输出的符号表的片段,这些符号来自于 ELF 文件’thread’ 的 symtable section。符号表的第一列为该符号的地址范围。第二列表示该符号的 属性,如’g’表示全局符号,’l’表示局部符号等。
‘‐f’ or ‘‐‐count‐filter’
‘‐g’ or ‘‐‐group’:将计数器组合成计数器组。Perf 在默认情况下会为每个计数器创建一个独立 的 ring buffer。如果将计数器组合成计数器组,perf 则会将所有 counter 的数据输 出到 group leader 的 ring buffer 中。当内核生成采样数据不多并且内存较为紧张 时,可采用此参数以节省内存。
‘‐i’ or ‘‐‐inherit’:采用此参数后,子进程将自动继承父进程的性能事件。从而使得 perf 能够采 集到动态创建的进程的性能数据。但是,当采用’‐p’参数仅分析特定进程的性能 数据时,继承机制会被禁用。这主要是出于性能的考虑。
‘‐‐sym‐annotate’
‘‐z’ or ‘‐‐zero’:更新界面的数据后,清除历史信息。
‘‐F’ or ‘‐‐freq’
‘‐E’ or ‘‐‐entries’
‘‐U’ or ‘‐‐hide_user_symbols’:仅显示属于内核的符号,隐藏属于用户程序的符号,即类型为[.]的符号。
‘‐v’ or ‘‐‐verbose’:显示冗余信息,如符号地址、符号类型(全局、局部、用户、内核等)。
‘‐s’ or ‘‐‐sort’ <key[,key2…>:指定界面显示的信息,以及这些信息的排序。Perf 提供的备选信息有:
| Comm | 触发事件的进程名 |
|---|---|
| PID | 触发事件的进程号 |
| DSO | 符号所属的 DSO 的名称 |
| Symbol | 符号名 |
| Parent | 调用路径的入口 |
当采用如下命令时,perf top 会给出更加丰富的信息。
$perf top ‐s comm,pid,dso,parent,symbol

从上图可以查看更丰富的信息,各行信息的意义与上述命令中个字段的排 序相对应。
‘‐n’ or ‘‐‐show‐nr‐samples’:显示每个符号对应的采样数量。
$perf top –n

图上的第二列为本行的符号在本轮分析中对应的采样数量。
‘‐‐show‐total‐period’:在界面上显示符号对应的性能事件总数。如第二节所述,性能事件计数器在 溢出时才会触发一次采样。两次采样之间的计数值即为这段时间内发生的事件总 数,perf 将其称之为周期(period)。
使用方法为:
$perf top ‐‐show‐total‐period
执行上述命令后,将得到如图所示的结果。

图上的第二列即为该行符号在本轮分析中对应的事件总数。
‘‐G’ or ‘‐‐call‐graph’ <output_type,min_percent,call_order> :在界面中显示函数的调用图谱。用户还可以指定显示类型,采样率的最小阈值,以及调用顺序。下面通过一个简单的程序观察一下 perf top 如何显示调用图谱。
code2:
$$
include <stdio.h>
include <math.h>
include <sys/types.h>
include <linux/unistd.h>
int do_pi(int p){
double mypi,h,sum,x;
long long n,i;
n = 500000000000;
h = 1.0/n;
sum=0.0;
for (i = 1; i <= n; i+=1 ) {
x = h * ( i ‐ 0.5 );
sum += 4.0 / (1.0 + pow(x,2));
}
mypi = h * sum;
return 0;
}
int bk()
{
do_pi(0);
}
int ak()
{
double mypi,h,sum,x;
long long n,i;
n = 500000;
h = 1.0/n;
sum=0.0;
for (i = 1; i <= n; i+=1 ) {
x = h * ( i ‐ 0.5 );
sum += 4.0 / (1.0 + pow(x,2));
}
mypi = h * sum;
bk();
}
int b()
{
do_pi(1);
}
int a()
{
b();
}
int main()
{
pid_t pid;
printf("pid: %d\n", getpid());
pid = fork();
if (pid == 0) {
ak();
}
a();
return 0;
}
$$
Code2 是一个多进程程序,主进程通过 main()‐>a()‐>b()‐>do_pi()这条路径最 终调用了 do_pi(),子进程则通过 main()‐>ak()‐>bk()‐>do_pi()这条路径最终调用了 do_pi()。在系统中运行 code2 后,执行下述命令:
$perf top –G
将得到如图*所示的界面。

从上图可以看到,与普通的 perf top 界面相比,每行的最左面多了一 个’+’号,表示此符号可以展开函数调用图谱。将焦点定位在符号 do_pi 后,通过 回车键,即可展开 do_pi()的调用图谱。展开以后,perf top 会在每条调用路径前 显示相应的采样率,表示有多少采样是由该条路径触发的。在图中,共有 2 条路径调用了 do_pi(),分别是 main()‐>a()‐>b()‐>do_pi()与main()‐>ak()‐>bk()‐>do_pi()。这两条路径的采样率分别是 50.18%与 49.82%。对于 复杂的软件而言,函数调用图谱为更加深入的性能分析提供了途径。我们不仅能 够直观地查找热点函数,还能够进一步直观地查找到使得该函数成为热点的代码路径。
参数‐G 具有 3 个配置选项 output_type,min_percent 与 call_order。选项 output_type 允许用户指定调用图谱的显示方式。Perf 提供了 3 种显示方式:
- graph: 使用调用树,将每条调用路径进一步折叠。这种显示方式更加直观。 每条调用路径的采样率为绝对值。也就是该条路径占整个采样域的比率。使 用方法为:
$perf top ‐G graph
输出结果如下图所示。

-
fractal 默认选项。类似与 graph,但是每条路径前的采样率为相对值。
-
flat 不折叠各条调用路径,也不显示每条调用路径的采样率。如下图所示。

我们还可以通过 min_percent 选项过滤采样率低于 min_percent 的调用路径。 min_percent 的默认值为 0.5。
选项 call_order 用以设定调用图谱的显示顺序,该选项有 2 个取值,分别是 callee 与 caller。将该选项设为 callee 时,perf 按照被调用的顺序显示调用图谱, 上层函数被下层函数所调用,如图*所示。该选项被设为 caller 时,按照调用顺 序显示调用图谱,即上层函数调用了下层函数。执行如下命令后,可以得到 caller 风格的调用图谱,如下图所示。
$perf top ‐G graph,0.5,caller

‘‐‐dsos’ <dso_name[,dso_name…]>:仅显示 dso 名为 dso_name 的符号。可以同时指定多个 dso,各个 dso 名 字之间通过逗号隔开。
‘‐‐comms’ <comm[,comm…]>:仅显示属于进程“comm”的符号。
‘‐‐symbols<symbol[,symbol…>:仅显示指定的符号。
‘‐M’ or ‘‐‐disassembler‐style’:显示符号注解时,可以通过此参数指定汇编语言的风格。
用例
# perf top -e cycles:k #显示内核和模块中,消耗最多CPU周期的函数
# perf top -e kmem:kmem_cache_alloc #显示分配高速缓存最多的函数
# perf top
Samples: 1M of event 'cycles', Event count (approx.): 73891391490
5.44% perf [.] 0x0000000000023256
4.86% [kernel] [k] _spin_lock
2.43% [kernel] [k] _spin_lock_bh
2.29% [kernel] [k] _spin_lock_irqsave
1.77% [kernel] [k] __d_lookup
1.55% libc-2.12.so [.] __strcmp_sse42
1.43% nginx [.] ngx_vslprintf
1.37% [kernel] [k] tcp_poll
# perf top -g #得到调用关系图
# perf top -e cycles #指定性能事件
# perf top -p 23015,32476 #查看这两个进程的cpu cycles使用情况
# perf top -s comm,pid,symbol #显示调用symbol的进程名和进程号
# perf top --comms nginx,top #仅显示属于指定进程的符号
# perf top --symbols kfree #仅显示指定的符号
内核tracepoint的使用
Tracepoint
- 在内核的 tracepoint 中可以插入 hook function ,以追踪内核的执行流。
- Taobao 2.6.32 内核中共有 801 个 tracepoint
- Upstream 内核中共有 906 个 tracepoint
- Perf 将 tracepoint 作为性能事件
module:function
使用方法
- 使用 perf list 查看当前系统支持的 tracepoint
- perf top [record] –e module:function
用例
统计程序使用的系统调用数:
perf stat -e raw_syscalls:sys_enter ls
---------------------------------------------------------------
Performance counter stats for 'ls‘:
128 raw_syscalls:sys_enter
0.002457299 seconds time elapsed
----------------------------------------------------------------------------
ls 在执行期间共调用了 128 次系统调用
使用perf timechart观察事件图谱
将系统的运行状态以 SVG 图的形式输出。
1. 各处理器状态 (run, idle)
2. 各进程的时间图谱( run, sleep, blocked … )
使用方法
记录系统状态
# perf timechart record
l 绘制系统状态图
# perf timechart
输出: output.svg

使用perf bench进行基准测试
perf bench命令包含多个多线程微内核基准测试,用于在Linux内核和系统调用中执行不同的子系统。这使得黑客可以轻松地测量更改的影响,从而帮助缓解性能衰退。
它还充当一个通用的基准框架,使开发人员能够轻松地创建测试用例、透明进行整合和使用富性能工具子系统。
sched:调度器基准测试
测量多个任务之间的pipe(2)和socketpair(2)操作。允许测量线程与进程上下文切换的性能。
$perf bench sched messaging -g 64
# Running 'sched/messaging' benchmark:
# 20 sender and receiver processes per group
# 64 groups == 2560 processes run
Total time: 1.549 [sec]
mem:内存访问基准测试
numa: numa调度和MM基准测试
futex: futex压力基准测试
处理futex内核实现的细粒度方面。它对于内核黑客非常有用。它目前支持唤醒和重新排队/等待操作,并强调私有和共享futexes的哈希方案。下面时nCPU线程运行的一个示例,每个线程处理1024个futex来测量哈希逻辑:
$ perf bench futex hash
# Running 'futex/hash' benchmark:
Run summary [PID 17428]: 4 threads, each operating on 1024 [private] futexes for 10 secs.
[thread 0] futexes: 0x2775700 ... 0x27766fc [ 3343462 ops/sec ]
[thread 1] futexes: 0x2776920 ... 0x277791c [ 3679539 ops/sec ]
[thread 2] futexes: 0x2777ab0 ... 0x2778aac [ 3589836 ops/sec ]
[thread 3] futexes: 0x2778c40 ... 0x2779c3c [ 3563827 ops/sec ]
Averaged 3544166 operations/sec (+- 2.01%), total secs = 10
故障诊断和建议
本节列出了很多建议来避免使用Perf时常见的陷阱。
打开文件的限制
Perf工具所使用的perf_event内核接口的设计是这样的:它为per-thread或per-cpu的每个事件使用一个文件描述符。
在16-way系统上,当您这样做时:
perf stat -e cycles sleep 1
您实际上创建了16个事件,从而消耗了16个文件描述符。
在per-thread模式下,当您在同一16-way系统上对具有100个线程的进程进行采样时:
perf record -e cycles my_hundred_thread_process
然后,一旦创建了所有的线程,您将得到100*1(event)*16(cpus)=1600个文件描述符。Perf在每个CPU上创建一个事件实例。只有当线程在该CPU上执行时,事件才能有效地度量。这种方法加强了采样缓冲区的局部性,从而减少了采样开销。在运行结束时,该工具将所有样本合计到一个输出文件中。
如果Perf因“打开的文件太多”错误而中止,有以下几种解决方案:
- 使用ulimit-n增加每个进程打开的文件数。注意:您必须是root
- 限制一次运行中测量的事件数
- 限制正在测量的CPU数量
增加打开文件限制
超级用户可以更改进程打开的文件限制,使用 ulimit shell内置命令:
ulimit -a
[...]
open files (-n) 1024
[...]
ulimit -n 2048
ulimit -a
[...]
open files (-n) 2048
[...]
使用build-id表示二进制文件
perf record命令在perf.data中保存着与测量相关的所有ELF镜像的唯一标识符。在per-thread模式下,这包括被监视进程的所有ELF镜像。在cpu-wide模式下,它包括系统上运行的所有进程。如果使用-Wl,--build-id选项,则链接器将生成这些唯一标识符。因此,它们被称为build-id。当将指令地址与ELF映像关联时,build id是一个非常有用的工具。要提取perf.data文件中使用的所有生成id项,请发出:
perf buildid-list -i perf.data
06cb68e95cceef1ff4e80a3663ad339d9d6f0e43 [kernel.kallsyms]
e445a2c74bc98ac0c355180a8d770cd35deb7674 /lib/modules/2.6.38-8-generic/kernel/drivers/gpu/drm/i915/i915.ko
83c362c95642c3013196739902b0360d5cbb13c6 /lib/modules/2.6.38-8-generic/kernel/drivers/net/wireless/iwlwifi/iwlcore.ko
1b71b1dd65a7734e7aa960efbde449c430bc4478 /lib/modules/2.6.38-8-generic/kernel/net/mac80211/mac80211.ko
ae4d6ec2977472f40b6871fb641e45efd408fa85 /lib/modules/2.6.38-8-generic/kernel/drivers/gpu/drm/drm.ko
fafad827c43e34b538aea792cc98ecfd8d387e2f /lib/i386-linux-gnu/ld-2.13.so
0776add23cf3b95b4681e4e875ba17d62d30c7ae /lib/i386-linux-gnu/libdbus-1.so.3.5.4
f22f8e683907b95384c5799b40daa455e44e4076 /lib/i386-linux-gnu/libc-2.13.so
[...]
build-id缓存
每次运行结束时,perf record命令都会更新一个build id缓存,其中包含带有样本的ELF镜像的新条目。缓存包含:
- 带样本的ELF镜像的
build-id - 带有样本的ELF镜像的副本
给定的build-id是不可变的,它们唯一地标识二进制文件。如果重新编译二进制文件,将生成新的build-id,并在缓存中保存ELF图像的新副本。缓存保存在磁盘上的默认目录$HOME/.debug中。系统管理员可以使用全局配置文件/etc/perfconfig为缓存指定备用全局目录:
$ cat /etc/perfconfig
[buildid]
dir = /var/tmp/.debug
在某些情况下,关掉 build-id 缓存更新可能时有益的。为此,你需要使用perf record的 -n选项 性能记录
perf record -N dd if=/dev/zero of=/dev/null count=100000
访问控制
对于某些事件,必须是root才能调用perf工具。本文档假定用户具有root权限。如果您试图在权限不足的情况下运行perf,它将报告
No permission to collect system-wide stats.
其他场景
分析睡眠时间
perf lock
# perf lock record ls #记录
# perf lock report #报告
Name acquired contended total wait (ns) max wait (ns) min wait (ns)
&mm->page_table_... 382 0 0 0 0
&mm->page_table_... 72 0 0 0 0
&fs->lock 64 0 0 0 0
dcache_lock 62 0 0 0 0
vfsmount_lock 43 0 0 0 0
&newf->file_lock... 41 0 0 0 0
Name:内核锁的名字。
aquired:该锁被直接获得的次数,因为没有其它内核路径占用该锁,此时不用等待。
contended:该锁等待后获得的次数,此时被其它内核路径占用,需要等待。
total wait:为了获得该锁,总共的等待时间。
max wait:为了获得该锁,最大的等待时间。
min wait:为了获得该锁,最小的等待时间。
perf kmem
# perf kmem record ls #记录
# perf kmem stat --caller --alloc -l 20 #报告
------------------------------------------------------------------------------------------------------
Callsite | Total_alloc/Per | Total_req/Per | Hit | Ping-pong | Frag
------------------------------------------------------------------------------------------------------
perf_event_mmap+ec | 311296/8192 | 155952/4104 | 38 | 0 | 49.902%
proc_reg_open+41 | 64/64 | 40/40 | 1 | 0 | 37.500%
__kmalloc_node+4d | 1024/1024 | 664/664 | 1 | 0 | 35.156%
ext3_readdir+5bd | 64/64 | 48/48 | 1 | 0 | 25.000%
load_elf_binary+8ec | 512/512 | 392/392 | 1 | 0 | 23.438%
Callsite:内核代码中调用kmalloc和kfree的地方。
Total_alloc/Per:总共分配的内存大小,平均每次分配的内存大小。
Total_req/Per:总共请求的内存大小,平均每次请求的内存大小。
Hit:调用的次数。
Ping-pong:kmalloc和kfree不被同一个CPU执行时的次数,这会导致cache效率降低。
Frag:碎片所占的百分比,碎片 = 分配的内存 - 请求的内存,这部分是浪费的。
有使用--alloc选项,还会看到Alloc Ptr,即所分配内存的地址。
perf sched
# perf sched record sleep 10
# perf report latency --sort max
---------------------------------------------------------------------------------------------------------------
Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | Maximum delay at |
---------------------------------------------------------------------------------------------------------------
events/10:61 | 0.655 ms | 10 | avg: 0.045 ms | max: 0.161 ms | max at: 9804.958730 s
sleep:11156 | 2.263 ms | 4 | avg: 0.052 ms | max: 0.118 ms | max at: 9804.865552 s
edac-poller:1125 | 0.598 ms | 10 | avg: 0.042 ms | max: 0.113 ms | max at: 9804.958698 s
events/2:53 | 0.676 ms | 10 | avg: 0.037 ms | max: 0.102 ms | max at: 9814.751605 s
perf:11155 | 2.109 ms | 1 | avg: 0.068 ms | max: 0.068 ms | max at: 9814.867918 s
TASK:进程名和pid。
Runtime:实际的运行时间。
Switches:进程切换的次数。
Average delay:平均的调度延迟。
Maximum delay:最大的调度延迟。
Maximum delay at:最大调度延迟发生的时刻。
perf probe
# perf probe --line schedule #前面有行号的可以探测,没有行号的就不行了
# perf report latency --sort max #在schedule函数的12处增加一个探测点
全局
局性概况:
perf list查看当前系统支持的性能事件; perf bench对系统性能进行摸底; perf test对系统进行健全性测试; perf stat对全局性能进行统计;
全局细节:
perf top可以实时查看当前系统进程函数占用率情况; perf probe可以自定义动态事件;
特定功能分析:
perf kmem针对slab子系统性能分析; perf kvm针对kvm虚拟化分析; perf lock分析锁性能; perf mem分析内存slab性能; perf sched分析内核调度器性能; perf trace记录系统调用轨迹;
最常用功能perf record,可以系统全局,也可以具体到某个进程,更甚具体到某一进程某一事件;可宏观,也可以很微观。
pref record记录信息到perf.data; perf report生成报告; perf diff对两个记录进行diff; perf evlist列出记录的性能事件; perf annotate显示perf.data函数代码; perf archive将相关符号打包,方便在其它机器进行分析; perf script将perf.data输出可读性文本;
可视化工具perf timechart
perf timechart record记录事件; perf timechart生成output.svg文档;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号