
sed.md
SED
sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
选项
-
-e command,--expression=command直接在指令列模式上进行 sed 的动作编辑;
-
-n,--quiet,--silent:使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-
-f,--filer=script-file:直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作;
-
-r, --regexp-extended:支持使用扩展正则表达式;
-
-i[SUFFIX], --in-place[=SUFFIX]:直接编辑原文件 ;
命令
-
a 在当前行后面加入一行文本。
-
b lable分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
-
c 用新的文本改变本行的文本。
-
d 从模板块(Pattern space)位置删除行。
-
D 删除模板块的第一行。
-
i 在当前行上面插入文本。
-
h 拷贝模板块的内容到内存中的缓冲区。
-
H 追加模板块的内容到内存中的缓冲区
-
g 获得内存缓冲区的内容,并替代当前模板块中的文本。
-
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
-
l 列表不能打印字符的清单。
-
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
-
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
-
p 打印模板块的行。
-
P(大写)打印模板块的第一行。
-
q 退出Sed。
-
r file从file中读行。
-
t labelif分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
-
T label错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
-
w file写并追加模板块到file末尾。
-
W file写并追加模板块的第一行到file末尾。
-
! 表示后面的命令对所有没有被选定的行发生作用。
-
s/re/string/ 查找替换,其分隔符可自行指定,常用的有s@@@, s###等;
-
= 打印当前行号码。
-
# 把注释扩展到下一个换行符以前。
替换标记
-
g 表示行内全面替换。
-
p 表示打印行。
-
w 表示把行写入一个文件。
-
x 表示互换模板块中的文本和缓冲区中的文本。
-
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
-
\1 子串匹配标记
-
& 已匹配字符串标记
元字符
-
^锚定行的开始如:
/^sed/匹配所有以sed开头的行。 -
$锚定行的结束 如:
/sed$/匹配所有以sed结尾的行。 -
.匹配一个非换行符的字符 如:
/s.d/匹配s后接一个任意字符,然后是d。 -
*匹配零或多个字符 如:
/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。 -
[]匹配一个指定范围内的字符,如
/[Ss]ed/匹配sed和Sed。 -
[^]匹配一个不在指定范围内的字符,如:
/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。 -
\(..\)保存匹配的字符,如
s/\(love\)able/\1rs,loveable被替换成lovers。 -
&;保存搜索字符用来替换其他字符,如
s/love/**&**/,love这成**love**。 -
\<;锚定单词的开始,如:
/\<love/匹配包含以love开头的单词的行。 -
\>;锚定单词的结束,如
/love\>/匹配包含以love结尾的单词的行。 -
x\{m\}重复字符x,m次,如:
/0\{5\}/匹配包含5个o的行。 -
x\{m,\}重复字符x,至少m次,如:
/o\{5,\}/匹配至少有5个o的行。 -
x\{m,n\}重复字符x,至少m次,不多于n次,如:
/o\{5,10\}/匹配5--10个o的行。
地址定位
定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。
空地址
空地址就是对全文进行处理。
单地址
单地址可以匹配指定的行,也可以按模式进行匹配。
-
#(数字):匹配指定的行。
-
/pattern/:被此模式所匹配到的每一行。
地址范围
-
#,#:从#行到#行匹配。
-
#,+#:从#行到之后的#行匹配。
-
#,/pat1/:从#行开始到之后第一个pat1模式匹配。
-
/pat1/,/pat2/:从pat1模式到pat2模式之间匹配。
-
$:最后一行
步进
-
1~2:所有奇数行
-
2~2:所有偶数行
编辑命令
打印p
命令p用于显示模式空间的内容。默认情况下,sed把输入行打印在屏幕上,选项-n用于取消默认的打印操作。当选项-n和命令p同时出现时,sed可打印选定的内容。
# sed '/root/p' filename
如果某行匹配模式root,p命令将把该行另外打印一遍。
# sed -n '/root/p'
选项-n取消sed默认的打印,p命令把匹配模式root的行打印一遍。
# sed -n '1p' filename
显示第一行。
# sed -n '$p' filename
显示最后一行。
# sed -n '2,5p' filename
显示第二到第五行。
# sed -n '5,$p' filename
显示第五行到最后一行。
删除d
命令d用于删除输入行。sed先将输入行从文件复制到模式空间里,然后对该行执行sed命令,最后将模式空间里的内容显示在屏幕上。如果发出的是命令d,当前模式空间里的输入行会被删除,不被显示。
# sed '1d' filename
删除第一行。
# sed '$d' filename
删除最后一行。
# sed '2,5d' filename
第二行到第五行删除。
# sed '5,$d' filename
第五行之后的行删除。
当前行前插入i
i\ 命令是在当前行的前面插入新的文本。
# sed '1i\test' filename
在第一行钱插入test。
# sed '2,5i\test' filename
在第二行到第五行前插入test。
# sed '2,5i\test\ntest' filename
上面是添加两行test。使用\n换行符。
从当前行后插入a
使用方法和前面的i一样只不过插入的位置的区别。
修改c
在使用c 命令时是将匹配的行替换成指定的内容。
读入文件r
r命令是读命令。sed使用该命令将一个文本文件中的内容通过匹配添加到文件的特定位置上。
# sed '/root/r test.txt' filename
读入的文件需要指定正确的位置,上面的例子中先匹配root行然后在其后的下一行读入test.txt文件的内容。如果匹配的root有多个则添加多次。
写入文件w
w 是写入文件,其是将匹配的内容写入到指定的文件中。
# sed '2,5w aaa' filename
上面的例子是匹配filename的第二到第五行,并将其写入到当前路径的aaa文件中。
查找替换s
# cat test
dota dota dota
df dota dota dota
ta dota
dota sa
ss dota
# sed 's/dota/DOTA/' test
DOTA dota dota
df DOTA dota dota
ta DOTA
DOTA sa
ss DOTA
将文件匹配行的第一个dota替换成DOTA。
# sed 's/dota/DOTA/g' test
DOTA DOTA DOTA
df DOTA DOTA DOTA
ta DOTA
DOTA sa
ss DOTA
这个是全局替换。
# sed 's/dota/DOTA/2g' test
dota DOTA DOTA
df dota DOTA DOTA
ta dota
dota sa
ss dota
将匹配行的第二个dota开始的所有DOTA 替换成ROOT。
# sed 's/dota/DOTA/2' test
dota DOTA dota
df dota DOTA dota
ta dota
dota sa
ss dota
将文件匹配行第二个root替换DOTA。
# sed -n 's/dota/DOTA/2p' test
dota DOTA dota
df dota DOTA dota
将匹配替换的行给打印出来。
# sed 's/^/#/' test
#dota dota dota
#df dota dota dota
#ta dota
# dota sa
#ss dota
给文件每行的前面添加#符。
# sed 's/^..//' test
ta dota dota
dota dota dota
dota
ota sa
dota
删除文件的前两个字符。
# sed 's/.//3' test
doa dota dota
dfdota dota dota
tadota
dta sa
ssdota
删除第三个字符。
标记
已匹配的字符串标记&
正则表达式\w+ 匹配每一个单词,使用[&] 替换它,& 对应于之前所匹配的单词。
# sed 's/\w\+/[&]/' test
[dota] dota dota
[df] dota dota dota
[ta] dota
[dota] sa
[ss] dota
将每行的第一个单词加上[]符号。如果想全部都加速使用g 进行替换标记。
# sed 's/\<dota\>/cn_&/' test
cn_dota dota dota
df cn_dota dota dota
ta cn_dota
cn_dota sa
ss cn_dota
将每行第一个的dota字符串加上cn_。
子字串标记\1
# sed -r 's/(^.*)(:.*:)(.*$)/\3\2\1/' /etc/passwd
将/etc/passwd 文件中以:为分隔符把第一个字串后最后一个字串互换。
# echo dota |sed -r 's/([a-z]+)/\1er/'
dotaer
将匹配的字串后面添加指定的字符。
多个匹配
# sed -r '1,2s/dota/DOTA/g; 3,$s/(dota)/\1er/g' test
DOTA DOTA DOTA
df DOTA DOTA DOTA
ta dotaer
dotaer sa
ss dotaer
将前两行的dota 改成DOTA,把第三行开始到最后的所有dota 后添加er。
# sed -r -e '1,2s/dota/DOTA/g' -e '3,$s/(dota)/\1er/g' test
DOTA DOTA DOTA
df DOTA DOTA DOTA
ta dotaer
dotaer sa
ss dotaer
上面两个的效果相同。
# sed '1,2s/dota/DOTA/g' test |sed -r '3,$s/(dota)/\1er/g'
DOTA DOTA DOTA
df DOTA DOTA DOTA
ta dotaer
dotaer sa
ss dotaer
也可以通过管道的方式实现。
练习题
删除/boot/grub2/grub.cfg文件中所有以空白字符开头的行的行首的所有空白字符;
# sed -r 's/(^[[:space:]]+)(.*)/\2/' /boot/grub2/grub.cfg
# sed 's@^[[:space:]]\+@@' /boot/grub2/grub.cfg
删除/etc/fstab文件中所有以#开头的行的行首的#号及#后面的所有空白字符;
# sed 's/^#[[:space:]]*//' /etc/fstab
输出一个绝对路径给sed命令,取出其目录,其行为类似于dirname;
# echo "/var/log/messages/" | sed 's@[^/]\+/\?$@@'
# echo "/var/log/messages" | sed -r 's@[^/]+/?$@@'
高级用法
h;G
将第一行的内容放到打三行后面
# cat bbb
11111
22222
33333
44444
55555
# sed '1h;3G' bbb
11111
22222
33333
11111
44444
55555
在每行的后面添加1个空行
注:1.保留空间里默认有一个空白行。2,‘G’默认处理全局
# sed '1,$G' bbb
11111
22222
33333
44444
55555
# sed 'G' bbb
11111
22222
33333
44444
55555
把第1行到第4行的数据复制到第5行后面
注:1h是为了覆盖保留空间里的空白行
# sed '1h;2,4H;5G' bbb
11111
22222
33333
44444
55555
11111
22222
33333
44444
把第1行到第4行的数据剪切到第5行后面
# sed '1h;2,4H;1,4d;5G' bbb
55555
11111
22222
33333
44444
对匹配行的下一行进行处理n
# sed -n '1n;p' bbb
22222
33333
44444
55555
交换模式空间和保留空间的内容x
# sed '1h;3x' bbb
11111
22222
11111
44444
55555
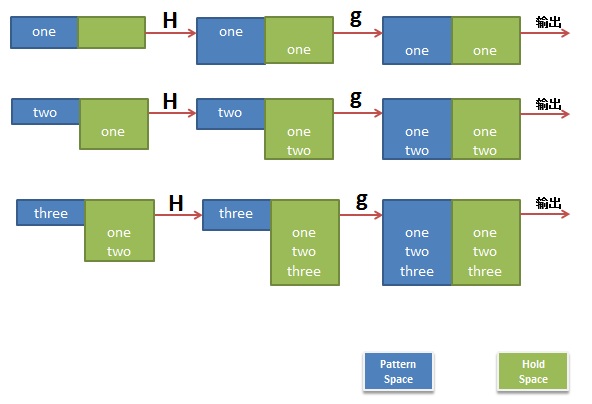
图片连接:http://coolshell.cn/articles/9104.html
参考与扩展:
http://sed.sourceforge.net/sed1line_zh-CN.html
http://tanxin.blog.51cto.com/6114226/1208944
http://coolshell.cn/articles/9104.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号