

▶ 线程束表决函数(Warp Vote Functions)
● 用于同一线程束内各线程通信和计算规约指标。
1 // device_functions.h,cc < 9.0 2 __DEVICE_FUNCTIONS_STATIC_DECL__ int __all(int a) 3 { 4 int result; 5 asm __volatile__("{ \n\t" 6 ".reg .pred \t%%p1; \n\t" 7 ".reg .pred \t%%p2; \n\t" 8 "setp.ne.u32 \t%%p1, %1, 0; \n\t" 9 "vote.all.pred \t%%p2, %%p1; \n\t" 10 "selp.s32 \t%0, 1, 0, %%p2; \n\t" 11 "}" : "=r"(result) : "r"(a)); 12 return result; 13 } 14 15 __DEVICE_FUNCTIONS_STATIC_DECL__ int __any(int a) 16 { 17 int result; 18 asm __volatile__("{ \n\t" 19 ".reg .pred \t%%p1; \n\t" 20 ".reg .pred \t%%p2; \n\t" 21 "setp.ne.u32 \t%%p1, %1, 0; \n\t" 22 "vote.any.pred \t%%p2, %%p1; \n\t" 23 "selp.s32 \t%0, 1, 0, %%p2; \n\t" 24 "}" : "=r"(result) : "r"(a)); 25 return result; 26 } 27 28 __DEVICE_FUNCTIONS_STATIC_DECL__ 29 #if defined(__CUDACC_RTC__) || defined(__CUDACC_INTEGRATED__) 30 unsigned int __ballot(int a) 31 #else 32 int __ballot(int a) 33 #endif 34 { 35 int result; 36 asm __volatile__("{ \n\t" 37 ".reg .pred \t%%p1; \n\t" 38 "setp.ne.u32 \t%%p1, %1, 0; \n\t" 39 "vote.ballot.b32 \t%0, %%p1; \n\t" 40 "}" : "=r"(result) : "r"(a)); 41 return result; 42 } 43 44 // device_functions.h,cc≥9.0,改进并废弃了原来的三个,增加两个 45 int __all_sync(unsigned int mask, int predicate); 46 int __any_sync(unsigned int mask, int predicate); 47 int __uni_sync(unsigned int mask, int predicate); 48 unsigned int __ballot_sync(unsigned int mask, int predicate); 49 unsigned int __activemask(); 50 51 //sm_30_intrinsics.hpp,cc ≥ 9.0 52 __SM_30_INTRINSICS_DECL__ int __all_sync(unsigned mask, int pred) 53 { 54 extern __device__ __device_builtin__ int __nvvm_vote_all_sync(unsigned int mask, int pred); 55 return __nvvm_vote_all_sync(mask, pred); 56 } 57 58 __SM_30_INTRINSICS_DECL__ int __any_sync(unsigned mask, int pred) 59 { 60 extern __device__ __device_builtin__ int __nvvm_vote_any_sync(unsigned int mask, int pred); 61 return __nvvm_vote_any_sync(mask, pred); 62 } 63 64 __SM_30_INTRINSICS_DECL__ int __uni_sync(unsigned mask, int pred) 65 { 66 extern __device__ __device_builtin__ int __nvvm_vote_uni_sync(unsigned int mask, int pred); 67 return __nvvm_vote_uni_sync(mask, pred); 68 } 69 70 __SM_30_INTRINSICS_DECL__ unsigned __ballot_sync(unsigned mask, int pred) 71 { 72 extern __device__ __device_builtin__ unsigned int __nvvm_vote_ballot_sync(unsigned int mask, int pred); 73 return __nvvm_vote_ballot_sync(mask, pred); 74 } 75 76 __SM_30_INTRINSICS_DECL__unsigned __activemask() 77 { 78 unsigned ret; 79 int predicate = 1; 80 asm volatile ("{ .reg .pred p; setp.ne.u32 p, %1, 0; vote.ballot.b32 %0, p; } " : "=r"(ret) : "r"(predicate)); 81 return ret; 82 }
● 在设备代码的一个线程中调用 _all(predicate),__any(mask, predicate),__ballot(mask, predicate) 时,该线程所在的线程束中所有线程(标号 0 ~ 31,称为 lane ID)求变量 predicate 的值,并按照一定的规律返回一个整形值。
● _all() 当且仅当所有线程的 predicate 非零时返回 1,否则返回 0。
● _any() 当且仅当至少有一个线程的 predicate 非零时返回 1,否则返回 0。
● _ballot() 返回一个无符号整数,代表了该线程束内变量 predicate 的非零值分布情况。线程 predicate 为零的该函数返回值该位为 0,线程 predicate 非零的该函数返回值该位为 1 。
● CUDA9.0 对以上函数进行了改进,变成了 _all_sync(),_any_sync(),_ballot_sync() 。添加了参数 unsigned int mask(注意也是 32 bit),用来指定线程束中的特定位参与 predicate 的计算(而不像 CUDA8.0 中那样全员参与),不参加计算的线程结果按 0 计。函数强制同步了所有被 mask 指定的线程,就算被指定的线程不活跃,也要包含该函数的调用,否则结果未定义。
● _uni_sync() 当且仅当被 mask 指定线程的 predicate 全部非零或全部为零时返回 1,否则返回 0。
● __activemask() 返回一个无符号整数,代表了该线程束内活动线程的分布情况。该线程活动则返回值该位为 1,否则为 0 。该函数没有 mask参数,必须全员参加。
● CUDA8.0 上的测试代码
1 #include <stdio.h> 2 #include <malloc.h> 3 #include <cuda_runtime.h> 4 #include "device_launch_parameters.h" 5 #include "device_functions.h" 6 7 __global__ void vote_all(int *a, int *b, int n) 8 { 9 int tid = threadIdx.x; 10 if (tid > n) 11 return; 12 int temp = a[tid]; 13 b[tid] = __all(temp > 48); 14 } 15 16 __global__ void vote_any(int *a, int *b, int n) 17 { 18 int tid = threadIdx.x; 19 if (tid > n) 20 return; 21 int temp = a[tid]; 22 b[tid] = __any(temp > 48); 23 } 24 25 __global__ void vote_ballot(int *a, int *b, int n) 26 { 27 int tid = threadIdx.x; 28 if (tid > n) 29 return; 30 int temp = a[tid]; 31 b[tid] = __ballot(temp > 42 && temp < 53); 32 } 33 34 int main() 35 { 36 int *h_a, *h_b, *d_a, *d_b; 37 int n = 128, m = 32; 38 int nsize = n * sizeof(int); 39 40 h_a = (int *)malloc(nsize); 41 h_b = (int *)malloc(nsize); 42 for (int i = 0; i < n; ++i) 43 h_a[i] = i; 44 memset(h_b, 0, nsize); 45 cudaMalloc(&d_a, nsize); 46 cudaMalloc(&d_b, nsize); 47 cudaMemcpy(d_a, h_a, nsize, cudaMemcpyHostToDevice); 48 cudaMemset(d_b, 0, nsize); 49 50 vote_all << <1, n >> >(d_a, d_b, n); 51 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 52 printf("vote_all():"); 53 for (int i = 0; i < n; ++i) 54 { 55 if (!(i % m)) 56 printf("\n"); 57 printf("%d ", h_b[i]); 58 } 59 printf("\n"); 60 61 vote_any << <1, n >> >(d_a, d_b, n); 62 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 63 printf("vote_any():"); 64 for (int i = 0; i < n; ++i) 65 { 66 if (!(i % m)) 67 printf("\n"); 68 printf("%d ", h_b[i]); 69 } 70 printf("\n"); 71 72 vote_ballot << <1, n >> >(d_a, d_b, n); 73 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 74 cudaDeviceSynchronize(); 75 printf("vote_ballot():"); 76 for (int i = 0; i < n; ++i) 77 { 78 if (!(i % m)) 79 printf("\n"); 80 printf("%u ", h_b[i]);// 用无符号整数输出 81 } 82 printf("\n"); 83 84 getchar(); 85 return 0; 86 }
● 输出结果。其中 209510410 = 0000 0000 0001 1111 1111 1000 0000 00002,即第二个线程束(标号 32 ~ 63)的第 11 位(含0,标号43)起连续 10 位为 1,其余为 0 。
vote_all(): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 vote_any(): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 vote_ballot(): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
● CUDA9.0 上的测试代码:
1 #include <stdio.h> 2 #include <malloc.h> 3 #include <cuda_runtime.h> 4 #include "device_launch_parameters.h" 5 #include "device_functions.h" 6 7 __global__ void vote_all(int *a, int *b, int n) 8 { 9 int tid = threadIdx.x; 10 if (tid > n) 11 return; 12 int temp = a[tid]; 13 b[tid] = __all_sync(0xffffffff, temp > 48);// 注意添加了参数 mask 14 } 15 16 __global__ void vote_any(int *a, int *b, int n) 17 { 18 int tid = threadIdx.x; 19 if (tid > n) 20 return; 21 int temp = a[tid]; 22 b[tid] = __any_sync(0xffffffff, temp > 48); 23 } 24 25 __global__ void vote_ballot(int *a, int *b, int n) 26 { 27 int tid = threadIdx.x; 28 if (tid > n) 29 return; 30 int temp = a[tid]; 31 b[tid] = __ballot_sync(0xffffffff, temp > 42 && temp < 53); 32 } 33 34 __global__ void vote_union(int *a, int *b, int n) 35 { 36 int tid = threadIdx.x; 37 if (tid > n) 38 return; 39 int temp = a[tid]; 40 b[tid] = __uni_sync(0xffffffff, temp > 42 && temp < 53); 41 } 42 43 __global__ void vote_active(int *a, int *b, int n) 44 { 45 int tid = threadIdx.x; 46 if (tid > n || tid % 2)// 毙掉了所有偶数号线程 47 return; 48 int temp = a[tid]; 49 b[0] = __activemask(); 50 } 51 52 int main() 53 { 54 int *h_a, *h_b, *d_a, *d_b; 55 int n = 128, m = 32; 56 int nsize = n * sizeof(int); 57 58 h_a = (int *)malloc(nsize); 59 h_b = (int *)malloc(nsize); 60 for (int i = 0; i < n; ++i) 61 h_a[i] = i; 62 memset(h_b, 0, nsize); 63 cudaMalloc(&d_a, nsize); 64 cudaMalloc(&d_b, nsize); 65 cudaMemcpy(d_a, h_a, nsize, cudaMemcpyHostToDevice); 66 cudaMemset(d_b, 0, nsize); 67 68 vote_all << <1, n >> >(d_a, d_b, n); 69 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 70 printf("vote_all():"); 71 for (int i = 0; i < n; ++i) 72 { 73 if (!(i % m)) 74 printf("\n"); 75 printf("%d ", h_b[i]); 76 } 77 printf("\n"); 78 79 vote_any << <1, n >> >(d_a, d_b, n); 80 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 81 printf("vote_any():"); 82 for (int i = 0; i < n; ++i) 83 { 84 if (!(i % m)) 85 printf("\n"); 86 printf("%d ", h_b[i]); 87 } 88 printf("\n"); 89 90 vote_union << <1, n >> >(d_a, d_b, n); 91 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 92 printf("vote_union():"); 93 for (int i = 0; i < n; ++i) 94 { 95 if (!(i % m)) 96 printf("\n"); 97 printf("%d ", h_b[i]); 98 } 99 printf("\n"); 100 101 vote_ballot << <1, n >> >(d_a, d_b, n); 102 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 103 cudaDeviceSynchronize(); 104 printf("vote_ballot():"); 105 for (int i = 0; i < n; ++i) 106 { 107 if (!(i % m)) 108 printf("\n"); 109 printf("%u ", h_b[i]);// 用无符号整数输出 110 } 111 printf("\n"); 112 113 vote_active << <1, n >> >(d_a, d_b, n); 114 cudaMemcpy(h_b, d_b, sizeof(int), cudaMemcpyDeviceToHost); 115 cudaDeviceSynchronize(); 116 printf("vote_active():\n%u ", h_b[0]);// 用无符号整数输出 117 printf("\n"); 118 119 getchar(); 120 return 0; 121 }
● 输出结果。其中 2095104 同 CUDA8.0 中的情况;143165576510 = 0101 0101 0101 0101 0101 0101 0101 01012,即所有偶数号线程都不活跃(提前 return 掉了)。
vote_all(): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 vote_any(): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 vote_union(): 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 vote_ballot(): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 2095104 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 vote_active():
1431655765
▶ 线程束匹配函数(Warp Match Functions),要求 cc ≥ 7.0 的设备。
● 与线程束表决函数类似,对线程束内指定的线程进行计算,返回满足条件的线程编号构成的无符号整数。T 可以是 int,unsigned int,long,unsigned long,long long,unsigned long long,float,double 。
1 unsigned int __match_any_sync(unsigned mask, T value); 2 unsigned int __match_all_sync(unsigned mask, T value, int *pred);
● __match_any_sync() 比较 mask 指定的所有线程中的变量 value,返回具有相同值的线程编号构成的无符号整数。
● __match_all_sync() 比较 mask 指定的所有线程中的变量 value,当所有被指定的线程具有相同值的时候返回 mask 且 *pred 被置为 true,否则返回 0 且置 *pred 为 false。
▶ 线程束统筹函数(Warp Shuffle Functions)
● 定义在 sm_30_intrinsics.hpp 中,与 Warp Vote Functions 两者构成了整个头文件。T 可以是 int,unsigned int,long,unsigned long,long long,unsigned long long,float,double,__half,__half2 。
1 // sm_30_intrinsics.h,cuda < 9.0 2 T __shfl(int var, int srcLane, int width); 3 T __shfl_up(int var, int srcLane, int width); 4 T __shfl_down(int var, int srcLane, int width); 5 T __shfl_xor(int var, int srcLane, int width); 6 7 // sm_30_intrinsics.h,cuda ≥ 9.0 8 T __shfl_sync(unsigned mask, T var, int srcLane, int width = warpSize); 9 T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width = warpSize); 10 T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width = warpSize); 11 T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width = warpSize);
● 此处说明的图,以及后面的规约计算代码来源:http://blog.csdn.net/bruce_0712/article/details/64926471
● __shfl_sync() 被 mask 指定的线程返回标号为 srcLane 的线程中的变量 var 的值,其余线程返回0 。如下图例子中,调用 shfl_sync(mask, x, 2, 16); ,则标号为 2 的线程向标号为 0 ~ 15 的线程广播了其变量 x 的值;标号为 18 的线程向标号为 16 ~ 31 的线程广播了其变量 x 的值。

● __shfl_up_sync() 被 mask 指定的线程返回向前偏移为 delta 的线程中的变量 var 的值,其余线程返回0 。如下图例子中,调用 shfl_up_sync(mask, x, 2, 16); ,则标号为 2 ~15 的线程分别获得标号为 0 ~ 13 的线程中变量 x 的值;标号为 18 ~31 的线程分别获得标号为 16 ~ 29 的线程中变量 x 的值。

● __shfl_down_sync() 被 mask 指定的线程返回向后偏移为 delta 的线程中的变量 var 的值,其余线程返回0 。如下图例子中,调用 shfl_down_sync(mask, x, 2, 16); ,则标号为 0 ~13 的线程分别获得标号为 2 ~ 15 的线程中变量 x 的值;标号为 16 ~29 的线程分别获得标号为 18 ~ 31 的线程中变量 x 的值。
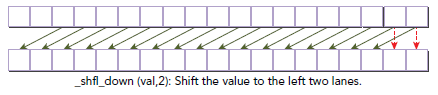
● __shfl_xor_sync() 被 mask 指定的线程返回向后偏移为 delta 的线程中的变量 var 的值,其余线程返回0 。如下图例子中,调用 shfl_down_sync(mask, x, 1, 16); ,则标号为 0 ~13 的线程分别获得标号为 2 ~ 15 的线程中变量 x 的值;标号为 16 ~29 的线程分别获得标号为 18 ~ 31 的线程中变量 x 的值。
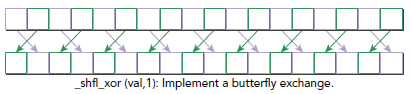
● __shfl_xor_sync() 的参数 laneMask 说明:
■ 当 n = 2k 时,表现为将连续的 n 个元素看做一个整体,与其后方连续的 n 个元素的整体做交换,但是两个整体的内部不做交换。例如 [0, 1, 2, 3, 4, 5, 6, 7] 做 n = 2 的变换得到 [2, 3, 0, 1, 6, 7, 4, 5] 。
■ 当 n ≠ 2k 时,先将 n 拆分成若干 2k 之和,分别做这些层次上的变换。这种操作是良定义的(二元轮换满足交换律和结合律)。例如 [0, 1, 2, 3, 4, 5, 6, 7] 做 n = 3 的变换时,先做 n = 2 的变换,得到 [2, 3, 0, 1, 6, 7, 4, 5],再做 n = 1 的变换,得到 [3, 2, 1, 0, 7, 6, 5, 4] 。
● 测试代码
1 #include <stdio.h> 2 #include <malloc.h> 3 #include <cuda_runtime.h> 4 #include "device_launch_parameters.h" 5 #include "device_functions.h" 6 7 __global__ void shfl(int *a, int *b, int n) 8 { 9 int tid = threadIdx.x; 10 if (tid > n) 11 return; 12 int temp = -a[tid];// 广播的值为线程原值的相反数 13 b[tid] = a[tid]; // 先将值赋成原值 14 15 b[tid] = __shfl_sync(0x00000000, temp, 0, 16); 16 // mask 作用不明,无论是调整为 0xffffffff 还是 0x55555555 还是 0x00000000 结果都没有变化 17 // temp 要广播的变量 18 // 0 广播源线程编号。若参数超出32,则自动取模处理(如输入为 99,则自动变成 99 % 32 = 3) 19 // 16 广播宽度。默认值 32(线程束内广播),可以调整为不超过 32 的 2 的整数次幂,超出 32 操作未定义(实测结果被当成 32 处理) 20 } 21 22 __global__ void shfl_up(int *a, int *b, int n) 23 { 24 int tid = threadIdx.x; 25 if (tid > n) 26 return; 27 int temp = -a[tid]; 28 b[tid] = a[tid]; 29 30 b[tid] = __shfl_up_sync(0x00000000, temp, 1, 16); 31 // 1 偏移量,而不是源线程编号 32 } 33 34 __global__ void shfl_down(int *a, int *b, int n) 35 { 36 int tid = threadIdx.x; 37 if (tid > n) 38 return; 39 int temp = -a[tid];// 广播的值为线程原值的相反数 40 b[tid] = a[tid]; // 先将值赋成原值 41 42 b[tid] = __shfl_down_sync(0x00000000, temp, 1, 16); 43 // 1 偏移量,而不是源线程编号 44 } 45 46 __global__ void shfl_xor(int *a, int *b, int n) 47 { 48 int tid = threadIdx.x; 49 if (tid > n) 50 return; 51 int temp = -a[tid];// 广播的值为线程原值的相反数 52 b[tid] = a[tid]; // 先将值赋成原值 53 54 b[tid] = __shfl_xor_sync(0x00000000, temp, 1, 16); 55 // 1 移动块大小,比较复杂,见前面的函数说明 56 } 57 58 59 int main() 60 { 61 int *h_a, *h_b, *d_a, *d_b; 62 int n = 128, m = 32; 63 int nsize = n * sizeof(int); 64 65 h_a = (int *)malloc(nsize); 66 h_b = (int *)malloc(nsize); 67 for (int i = 0; i < n; ++i) 68 h_a[i] = i; 69 memset(h_b, 0, nsize); 70 cudaMalloc(&d_a, nsize); 71 cudaMalloc(&d_b, nsize); 72 cudaMemcpy(d_a, h_a, nsize, cudaMemcpyHostToDevice); 73 cudaMemset(d_b, 0, nsize); 74 75 printf("Inital Array:"); 76 for (int i = 0; i < n; ++i) 77 { 78 if (!(i % m)) 79 printf("\n"); 80 printf("%4d ", h_a[i]); 81 } 82 printf("\n"); 83 84 shfl << <1, n >> >(d_a, d_b, n); 85 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 86 cudaDeviceSynchronize(); 87 printf("shfl():"); 88 for (int i = 0; i < n; ++i) 89 { 90 if (!(i % m)) 91 printf("\n"); 92 printf("%4d ", h_b[i]); 93 } 94 printf("\n"); 95 96 shfl_up << <1, n >> >(d_a, d_b, n); 97 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 98 cudaDeviceSynchronize(); 99 printf("shfl_up():"); 100 for (int i = 0; i < n; ++i) 101 { 102 if (!(i % m)) 103 printf("\n"); 104 printf("%4d ", h_b[i]); 105 } 106 printf("\n"); 107 108 shfl_down << <1, n >> >(d_a, d_b, n); 109 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 110 cudaDeviceSynchronize(); 111 printf("shfl_down():"); 112 for (int i = 0; i < n; ++i) 113 { 114 if (!(i % m)) 115 printf("\n"); 116 printf("%4d ", h_b[i]); 117 } 118 printf("\n"); 119 120 shfl_xor << <1, n >> >(d_a, d_b, n); 121 cudaMemcpy(h_b, d_b, nsize, cudaMemcpyDeviceToHost); 122 cudaDeviceSynchronize(); 123 printf("shfl_xor():"); 124 for (int i = 0; i < n; ++i) 125 { 126 if (!(i % m)) 127 printf("\n"); 128 printf("%4d ", h_b[i]); 129 } 130 printf("\n"); 131 132 getchar(); 133 return 0; 134 }
● 输出结果
Inital Array: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 shfl(): 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -16 -16 -16 -16 -16 -16 -16 -16 -16 -16 -16 -16 -16 -16 -16 -16 -32 -32 -32 -32 -32 -32 -32 -32 -32 -32 -32 -32 -32 -32 -32 -32 -48 -48 -48 -48 -48 -48 -48 -48 -48 -48 -48 -48 -48 -48 -48 -48 -64 -64 -64 -64 -64 -64 -64 -64 -64 -64 -64 -64 -64 -64 -64 -64 -80 -80 -80 -80 -80 -80 -80 -80 -80 -80 -80 -80 -80 -80 -80 -80 -96 -96 -96 -96 -96 -96 -96 -96 -96 -96 -96 -96 -96 -96 -96 -96 -112 -112 -112 -112 -112 -112 -112 -112 -112 -112 -112 -112 -112 -112 -112 -112 shfl_up(): 0 0 -1 -2 -3 -4 -5 -6 -7 -8 -9 -10 -11 -12 -13 -14 -16 -16 -17 -18 -19 -20 -21 -22 -23 -24 -25 -26 -27 -28 -29 -30 -32 -32 -33 -34 -35 -36 -37 -38 -39 -40 -41 -42 -43 -44 -45 -46 -48 -48 -49 -50 -51 -52 -53 -54 -55 -56 -57 -58 -59 -60 -61 -62 -64 -64 -65 -66 -67 -68 -69 -70 -71 -72 -73 -74 -75 -76 -77 -78 -80 -80 -81 -82 -83 -84 -85 -86 -87 -88 -89 -90 -91 -92 -93 -94 -96 -96 -97 -98 -99 -100 -101 -102 -103 -104 -105 -106 -107 -108 -109 -110 -112 -112 -113 -114 -115 -116 -117 -118 -119 -120 -121 -122 -123 -124 -125 -126 shfl_down(): -1 -2 -3 -4 -5 -6 -7 -8 -9 -10 -11 -12 -13 -14 -15 -15 -17 -18 -19 -20 -21 -22 -23 -24 -25 -26 -27 -28 -29 -30 -31 -31 -33 -34 -35 -36 -37 -38 -39 -40 -41 -42 -43 -44 -45 -46 -47 -47 -49 -50 -51 -52 -53 -54 -55 -56 -57 -58 -59 -60 -61 -62 -63 -63 -65 -66 -67 -68 -69 -70 -71 -72 -73 -74 -75 -76 -77 -78 -79 -79 -81 -82 -83 -84 -85 -86 -87 -88 -89 -90 -91 -92 -93 -94 -95 -95 -97 -98 -99 -100 -101 -102 -103 -104 -105 -106 -107 -108 -109 -110 -111 -111 -113 -114 -115 -116 -117 -118 -119 -120 -121 -122 -123 -124 -125 -126 -127 -127 shfl_xor(): -1 0 -3 -2 -5 -4 -7 -6 -9 -8 -11 -10 -13 -12 -15 -14 -17 -16 -19 -18 -21 -20 -23 -22 -25 -24 -27 -26 -29 -28 -31 -30 -33 -32 -35 -34 -37 -36 -39 -38 -41 -40 -43 -42 -45 -44 -47 -46 -49 -48 -51 -50 -53 -52 -55 -54 -57 -56 -59 -58 -61 -60 -63 -62 -65 -64 -67 -66 -69 -68 -71 -70 -73 -72 -75 -74 -77 -76 -79 -78 -81 -80 -83 -82 -85 -84 -87 -86 -89 -88 -91 -90 -93 -92 -95 -94 -97 -96 -99 -98 -101 -100 -103 -102 -105 -104 -107 -106 -109 -108 -111 -110 -113 -112 -115 -114 -117 -116 -119 -118 -121 -120 -123 -122 -125 -124 -127 -126
● 用 __shfl() 函数进行规约计算的代码(只给出核函数代码):
1 __global__ void reduce1(int *dst, int *src, const int n) 2 { 3 int tidGlobal = threadIdx.x + blockDim.x * blockIdx.x; 4 int tidLocal = threadIdx.x; 5 6 int sum = src[tidGlobal]; 7 8 __syncthreads(); 9 10 for (int offset = WARP_SIZE / 2; offset > 0; offset /= 2) 11 sum += __shfl_down(sum, offset);// 每次把后一半的结果挪到前一半并做加法 12 13 if (tidLocal == 0) 14 dst[blockIdx.x] = sum; 15 }
▶ B.16. Warp matrix functions [PREVIEW FEATURE](略过),要求 cc ≥ 7.0 的设备。
▶ B.17. Profiler Counter Function(略过)
1 //device_functions.h 2 #define __prof_trigger(X) asm __volatile__ ("pmevent \t" #X ";")
● 原文:Each multiprocessor has a set of sixteen hardware counters that an application can increment with a single instruction by calling the __prof_trigger() function. Increments by one per warp the per-multiprocessor hardware counter of index counter. Counters 8 to 15 are reserved and should not be used by applications. The value of counters 0, 1, ..., 7 can be obtained via nvprof by nvprof --events prof_trigger_0x where x is 0, 1, ..., 7. All counters are reset before each kernel launch (note that when collecting counters, kernel launches are synchronous as mentioned in Concurrent Execution between Host and Device).

