

附录 A,CUDA计算设备
附录 B,C语言扩展
▶ 函数的标识符
● __device__,__global__ 和 __host__

● 宏 __CUDA_ARCH__ 可用于区分代码的运行位置.
1 __host__ __device__ void fun() 2 { 3 # if __CUDA_ARCH__ >=600 4 // 代码运行于计算能力 6.x 设备 5 #elif __CUDA_ARCH__ >= 500 6 // 代码运行于计算能力 5.x 设备 7 #elif __CUDA_ARCH__ >= 300 8 // 代码运行于计算能力 3.x 设备 9 #elif __CUDA_ARCH__ >= 200 10 // 代码运行于计算能力 2.x 设备 11 #elif !defined(__CUDA_ARCH__) 12 // 代码运行于主机 13 #endif 14 }
● __noinline__ 和 __forceinlie__
■ __device__ 函数由便以其判断是否转化为内联函数。
■ __noinline__ 函数要求编译器尽量不转化为内联函数。
■ __forceinline__ 函数要求编译器尽量转化为内联函数。
■ __noline__ 和 __forceinline__ 不能共用,且不能放到 inline 函数的前面(已经内联的函数不能使用该标识符)。
▶ 变量的标识符
● __device__ 表明变量驻留在设备上,可与 __constant__ 或 __shared__ 共用,进一步表明变量的内存空间,若只有其一个标识符,则该变量满足:
■ 驻留在全局内存中。
■ 与创建该变量的 CUDA 上下文有相同的生命周期。
■ 在每台设备上有一个不同的对象。
■ 允许线程格中所有线程访问,也允许主机通过 Runtime API 访问(cudaGetSymbolAddress(),cudaGetSymbolSize(),cudaMemcpyToSymbol(),cudaMemcpyFromSymbol())。
● __constant__ 可选与 __device__ 共用,该变量满足:
■ 驻留在常数内存空间。
■ 与创建该变量的 CUDA 上下文有相同的生命周期。
■ 在每台设备上有一个不同的对象。
■ 允许线程格中所有线程访问,也允许主机通过 Runtime API 访问(cudaGetSymbolAddress(),cudaGetSymbolSize(),cudaMemcpyToSymbol(),cudaMemcpyFromSymbol())。
● __shared__ 可选与 __device__ 共用,该变量满足:
■ 驻留在对应线程块的共享内存空间。
■ 与对应线程块有相同的生命周期。
■ 在每个线程块上有一个不同的对象。
■ 只允许对应线程块中所有线程访问。
■ 外部共享内存数组的数据类型可以在函数内部发生变化,但要求按目标数据类型进行对齐。
1 __device__ void func() 2 { 3 extern __shared__ float array[]; 4 5 short* array0 = (short*)array; 6 int* array1 = (int*)&array0[32]; // 正确,对齐到 array 的 4B × k位置 7 float* array2 = (float*)&array0[64]; // 正确,对齐到 array 的 4B × k位置 8 9 short* array3 = (short*)&array0[127]; // 错误,没有对齐到 array 的 4B × k位置 10 }
● __managed__ 可选与 __device__ 共用,该变量满足:
■ 可被设备和主机访问,能直接被主机或设备函数读写。
■ 具有程序生命周期。
● __restrict__ nvcc 支持的关键字。
■ 在程序员保证输入变量地址不重叠的情况下,可以提示编译器使用优化。减少内存访问次数和计算步数,但有可能增加需要的寄存器数量,造成负优化(CUDA 寄存器压力问题)。
1 __device__ void func(const float* __restrict__ a, const float* __restrict__ b, float* __restrict__ c)
▶ 内建变量与内建变量类型
● 使用分量 x,y,z,w的形式将不超过四个同种类型的短变量放到一个长变量中去。
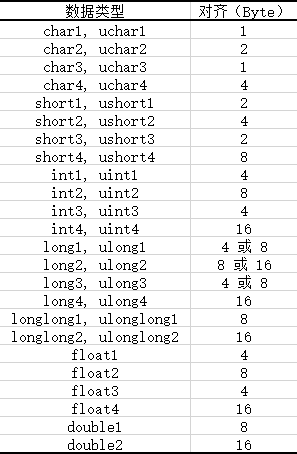
● 各种数据均使用 make_<type name>() 形式的函数来完成转化,压缩版的 vector_functions.h 定义了全部这样的函数。
1 #if !defined(__VECTOR_FUNCTIONS_HPP__) 2 #define __VECTOR_FUNCTIONS_HPP__ 3 4 #include "builtin_types.h" 5 #include "host_defines.h" 6 #include "vector_types.h" 7 8 #if defined(__CUDACC_RTC__) 9 #define __VECTOR_FUNCTIONS_DECL__ __host__ __device__ 10 #else /* !__CUDACC_RTC__ */ 11 #define __VECTOR_FUNCTIONS_DECL__ static __inline__ __host__ __device__ 12 #endif /* __CUDACC_RTC__ */ 13 14 __VECTOR_FUNCTIONS_DECL__ char1 make_char1(signed char x) 15 { 16 char1 t; t.x = x; return t; 17 } 18 19 __VECTOR_FUNCTIONS_DECL__ uchar1 make_uchar1(unsigned char x) 20 { 21 uchar1 t; t.x = x; return t; 22 } 23 24 __VECTOR_FUNCTIONS_DECL__ char2 make_char2(signed char x, signed char y) 25 { 26 char2 t; t.x = x; t.y = y; return t; 27 } 28 29 __VECTOR_FUNCTIONS_DECL__ uchar2 make_uchar2(unsigned char x, unsigned char y) 30 { 31 uchar2 t; t.x = x; t.y = y; return t; 32 } 33 34 __VECTOR_FUNCTIONS_DECL__ char3 make_char3(signed char x, signed char y, signed char z) 35 { 36 char3 t; t.x = x; t.y = y; t.z = z; return t; 37 } 38 39 __VECTOR_FUNCTIONS_DECL__ uchar3 make_uchar3(unsigned char x, unsigned char y, unsigned char z) 40 { 41 uchar3 t; t.x = x; t.y = y; t.z = z; return t; 42 } 43 44 __VECTOR_FUNCTIONS_DECL__ char4 make_char4(signed char x, signed char y, signed char z, signed char w) 45 { 46 char4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 47 } 48 49 __VECTOR_FUNCTIONS_DECL__ uchar4 make_uchar4(unsigned char x, unsigned char y, unsigned char z, unsigned char w) 50 { 51 uchar4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 52 } 53 54 __VECTOR_FUNCTIONS_DECL__ short1 make_short1(short x) 55 { 56 short1 t; t.x = x; return t; 57 } 58 59 __VECTOR_FUNCTIONS_DECL__ ushort1 make_ushort1(unsigned short x) 60 { 61 ushort1 t; t.x = x; return t; 62 } 63 64 __VECTOR_FUNCTIONS_DECL__ short2 make_short2(short x, short y) 65 { 66 short2 t; t.x = x; t.y = y; return t; 67 } 68 69 __VECTOR_FUNCTIONS_DECL__ ushort2 make_ushort2(unsigned short x, unsigned short y) 70 { 71 ushort2 t; t.x = x; t.y = y; return t; 72 } 73 74 __VECTOR_FUNCTIONS_DECL__ short3 make_short3(short x, short y, short z) 75 { 76 short3 t; t.x = x; t.y = y; t.z = z; return t; 77 } 78 79 __VECTOR_FUNCTIONS_DECL__ ushort3 make_ushort3(unsigned short x, unsigned short y, unsigned short z) 80 { 81 ushort3 t; t.x = x; t.y = y; t.z = z; return t; 82 } 83 84 __VECTOR_FUNCTIONS_DECL__ short4 make_short4(short x, short y, short z, short w) 85 { 86 short4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 87 } 88 89 __VECTOR_FUNCTIONS_DECL__ ushort4 make_ushort4(unsigned short x, unsigned short y, unsigned short z, unsigned short w) 90 { 91 ushort4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 92 } 93 94 __VECTOR_FUNCTIONS_DECL__ int1 make_int1(int x) 95 { 96 int1 t; t.x = x; return t; 97 } 98 99 __VECTOR_FUNCTIONS_DECL__ uint1 make_uint1(unsigned int x) 100 { 101 uint1 t; t.x = x; return t; 102 } 103 104 __VECTOR_FUNCTIONS_DECL__ int2 make_int2(int x, int y) 105 { 106 int2 t; t.x = x; t.y = y; return t; 107 } 108 109 __VECTOR_FUNCTIONS_DECL__ uint2 make_uint2(unsigned int x, unsigned int y) 110 { 111 uint2 t; t.x = x; t.y = y; return t; 112 } 113 114 __VECTOR_FUNCTIONS_DECL__ int3 make_int3(int x, int y, int z) 115 { 116 int3 t; t.x = x; t.y = y; t.z = z; return t; 117 } 118 119 __VECTOR_FUNCTIONS_DECL__ uint3 make_uint3(unsigned int x, unsigned int y, unsigned int z) 120 { 121 uint3 t; t.x = x; t.y = y; t.z = z; return t; 122 } 123 124 __VECTOR_FUNCTIONS_DECL__ int4 make_int4(int x, int y, int z, int w) 125 { 126 int4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 127 } 128 129 __VECTOR_FUNCTIONS_DECL__ uint4 make_uint4(unsigned int x, unsigned int y, unsigned int z, unsigned int w) 130 { 131 uint4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 132 } 133 134 __VECTOR_FUNCTIONS_DECL__ long1 make_long1(long int x) 135 { 136 long1 t; t.x = x; return t; 137 } 138 139 __VECTOR_FUNCTIONS_DECL__ ulong1 make_ulong1(unsigned long int x) 140 { 141 ulong1 t; t.x = x; return t; 142 } 143 144 __VECTOR_FUNCTIONS_DECL__ long2 make_long2(long int x, long int y) 145 { 146 long2 t; t.x = x; t.y = y; return t; 147 } 148 149 __VECTOR_FUNCTIONS_DECL__ ulong2 make_ulong2(unsigned long int x, unsigned long int y) 150 { 151 ulong2 t; t.x = x; t.y = y; return t; 152 } 153 154 __VECTOR_FUNCTIONS_DECL__ long3 make_long3(long int x, long int y, long int z) 155 { 156 long3 t; t.x = x; t.y = y; t.z = z; return t; 157 } 158 159 __VECTOR_FUNCTIONS_DECL__ ulong3 make_ulong3(unsigned long int x, unsigned long int y, unsigned long int z) 160 { 161 ulong3 t; t.x = x; t.y = y; t.z = z; return t; 162 } 163 164 __VECTOR_FUNCTIONS_DECL__ long4 make_long4(long int x, long int y, long int z, long int w) 165 { 166 long4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 167 } 168 169 __VECTOR_FUNCTIONS_DECL__ ulong4 make_ulong4(unsigned long int x, unsigned long int y, unsigned long int z, unsigned long int w) 170 { 171 ulong4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 172 } 173 174 __VECTOR_FUNCTIONS_DECL__ float1 make_float1(float x) 175 { 176 float1 t; t.x = x; return t; 177 } 178 179 __VECTOR_FUNCTIONS_DECL__ float2 make_float2(float x, float y) 180 { 181 float2 t; t.x = x; t.y = y; return t; 182 } 183 184 __VECTOR_FUNCTIONS_DECL__ float3 make_float3(float x, float y, float z) 185 { 186 float3 t; t.x = x; t.y = y; t.z = z; return t; 187 } 188 189 __VECTOR_FUNCTIONS_DECL__ float4 make_float4(float x, float y, float z, float w) 190 { 191 float4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 192 } 193 194 __VECTOR_FUNCTIONS_DECL__ longlong1 make_longlong1(long long int x) 195 { 196 longlong1 t; t.x = x; return t; 197 } 198 199 __VECTOR_FUNCTIONS_DECL__ ulonglong1 make_ulonglong1(unsigned long long int x) 200 { 201 ulonglong1 t; t.x = x; return t; 202 } 203 204 __VECTOR_FUNCTIONS_DECL__ longlong2 make_longlong2(long long int x, long long int y) 205 { 206 longlong2 t; t.x = x; t.y = y; return t; 207 } 208 209 __VECTOR_FUNCTIONS_DECL__ ulonglong2 make_ulonglong2(unsigned long long int x, unsigned long long int y) 210 { 211 ulonglong2 t; t.x = x; t.y = y; return t; 212 } 213 214 __VECTOR_FUNCTIONS_DECL__ longlong3 make_longlong3(long long int x, long long int y, long long int z) 215 { 216 longlong3 t; t.x = x; t.y = y; t.z = z; return t; 217 } 218 219 __VECTOR_FUNCTIONS_DECL__ ulonglong3 make_ulonglong3(unsigned long long int x, unsigned long long int y, unsigned long long int z) 220 { 221 ulonglong3 t; t.x = x; t.y = y; t.z = z; return t; 222 } 223 224 __VECTOR_FUNCTIONS_DECL__ longlong4 make_longlong4(long long int x, long long int y, long long int z, long long int w) 225 { 226 longlong4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 227 } 228 229 __VECTOR_FUNCTIONS_DECL__ ulonglong4 make_ulonglong4(unsigned long long int x, unsigned long long int y, unsigned long long int z, unsigned long long int w) 230 { 231 ulonglong4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 232 } 233 234 __VECTOR_FUNCTIONS_DECL__ double1 make_double1(double x) 235 { 236 double1 t; t.x = x; return t; 237 } 238 239 __VECTOR_FUNCTIONS_DECL__ double2 make_double2(double x, double y) 240 { 241 double2 t; t.x = x; t.y = y; return t; 242 } 243 244 __VECTOR_FUNCTIONS_DECL__ double3 make_double3(double x, double y, double z) 245 { 246 double3 t; t.x = x; t.y = y; t.z = z; return t; 247 } 248 249 __VECTOR_FUNCTIONS_DECL__ double4 make_double4(double x, double y, double z, double w) 250 { 251 double4 t; t.x = x; t.y = y; t.z = z; t.w = w; return t; 252 } 253 254 #undef __VECTOR_FUNCTIONS_DECL__ 255 256 #endif /* !__VECTOR_FUNCTIONS_HPP__ */
● dim3 类型,定义于 vector_types.h,用于声明线程格和线程块尺寸。基于 uint3 类型,加入了一个初始化函数。
1 struct __device_builtin__ dim3 2 { 3 unsigned int x, y, z; 4 #if defined(__cplusplus) 5 __host__ __device__ dim3(unsigned int vx = 1, unsigned int vy = 1, unsigned int vz = 1) : x(vx), y(vy), z(vz) {} 6 __host__ __device__ dim3(uint3 v) : x(v.x), y(v.y), z(v.z) {} 7 __host__ __device__ operator uint3(void) { uint3 t; t.x = x; t.y = y; t.z = z; return t; } 8 #endif /* __cplusplus */ 9 };
● gridDim 和 blockDim,基于 dim3 类型,指明线程格和线程块尺寸。
● blockIdx 和 threadIdx,基于uint3 类型,指明线程块和线程编号。
● warpSize,int 类型,指明一个线程束中的线程数量。
▶ 内存栅栏函数
● CUDA 编程默认为弱有序模式,也就是说 CUDA 中的线程往共享内存、全局内存、页锁定内存或另一台设备的内存中的写入并不完全按照 CUDA 设备或主机代码的顺序进行。举例下面的代码,先初始化两个全局变量 X 和 Y,分别使用线程 1 和 2 运行两个设备函数,观察结果。在强有序模式下,线程 2 结果可能为:① A == 1,B == 2(完全抢先),② A == 10,B == 2(部分抢先),③ A ==10,B ==20(完全落后)。但是在弱有序模式中,还有可能是 ④ A == 1,B == 20(看起来 B 初始化在 A 之前),需要使用内存栅栏函数来迫使内存读写按照顺序进行。
1 __device__ volatile int X = 1, Y = 2; 2 3 __device__ void writeXY() 4 { 5 X = 10; 6 Y = 20; 7 } 8 9 __device__ void readXY() 10 { 11 int A = X; 12 int B = Y; 13 }
● __threadfence_block() 。
■ 在调用该函数以前,主调线程的所有内存写入操作都要被它所在线程块内所有线程确认,接着主调线程才能调用该函数,然后主调线程继续之后的所有内存写入操作。原文:All writes to all memory made by the calling thread before the call to __threadfence_block() are observed by all threads in the block of the calling thread as occurring before all writes to all memory made by the calling thread after the call to __threadfence_block().
■ 在调用该函数以前,主调线程的所有内存读取操作都是有序的,接着主调线程才能调用该函数,然后主调线程继续之后的所有内存读取操作。原文:All reads from all memory made by the calling thread before the call to __threadfence_block() are ordered before all reads from all memory made by the calling thread after the call to __threadfence_block().
● __threadfence() 。与 __threadfence_block 类似,注意内存栅栏函数只对一个线程的读写操作有效,为了保证其他线程对被操作数据的可视性(防止由于缓存而没有来的及更新的内存中的被操作数据),应该对被操作数据加上关键字 volatile 。原文:acts as __threadfence_block() for all threads in the block of the calling thread and also ensures that no writes to all memory made by the calling thread after the call to __threadfence() are observed by any thread in the device as occurring before any write to all memory made by the calling thread before the call to __threadfence(). Note that for this ordering guarantee to be true, the observing threads must truly observe the memory and not cached versions of it; this is ensured by using the volatile keyword as detailed in Volatile Qualifier.
● __threadfence_system() 。与 __threadfence_block 类似,但是确认的主体加上主机线程和其它设备上的所有线程。原文:acts as __threadfence_block() for all threads in the block of the calling thread and also ensures that all writes to all memory made by the calling thread before the call to __threadfence_system() are observed by all threads in the device, host threads, and all threads in peer devices as occurring before all writes to all memory made by the calling thread after the call to __threadfence_system().
● 在上面的例子中,通过分别在两个函数的两个语句中间加上内存栅栏函数,就能消灭情况 ④ 的发生。区别在于,如果线程 1 和线程 2 在同一个线程块中,则函数 __threadfence_block() 就可以了;如果线程 1 和线程 2 在同一台设备的不同线程块中,则需要使用函数 __threadfence();如果线程 1 和线程 2 在不同的设备中,则只能使用函数 __threadfence_system() 。
1 // device_functions.hpp 2 __DEVICE_FUNCTIONS_STATIC_DECL__ void __threadfence_block() 3 { 4 __nvvm_membar_cta(); 5 } 6 7 __DEVICE_FUNCTIONS_STATIC_DECL__ void __threadfence() 8 { 9 __nvvm_membar_gl(); 10 } 11 12 __DEVICE_FUNCTIONS_STATIC_DECL__ void __threadfence_system() 13 { 14 __nvvm_membar_sys(); 15 }
● 教程中举了一个使用内存栅栏函数的例子。使用多线程块对一维数组作规约求和,首先将数组分段到各线程块中作分段求和,然后把各线程块计算的结果用原子操作加到全局内存的输出变量上,同时维护一个整形计数变量来记录已经完成任务的线程块数目,最后一个完成的线程块读取计数发现其等于 gridDim - 1,从而完成最后的加法,然后输出结果。问题在于,如果不在原子加法和维护计数变量之间插入内存栅栏函数,则有可能计数变量已经等于 gridDim - 1 但输出变量还没有将前 gridDim - 1个线程的结果加到一起,此时下一个(可能不是最后一个)线程直接读取输出变量就进行加法和输出,导致错误。
1 __device__ unsigned int count = 0; 2 __shared__ bool isLastBlockDone; 3 4 __global__ void sum(const float* array, unsigned int N, volatile float* result) 5 { 6 // Each block sums a subset of the input array. 7 float partialSum = calculatePartialSum(array, N); 8 9 if (threadIdx.x == 0) 10 { 11 // 每个线程块的 0 号线程将部分和输出到数组 result 中 12 // 使用了关键字 volatile, 不使用 L1 缓存来处理 result,保证内存操作可见性 13 14 // 写结果,栅栏,维护计数变量 15 result[blockIdx.x] = partialSum; 16 17 __threadfence(); 18 19 unsigned int value = atomicInc(&count, gridDim.x); 20 21 // 满足 value == gridDim.x - 1 的线程块是最后一个 22 isLastBlockDone = (value == (gridDim.x - 1)); 23 } 24 25 // 线程同步,保证所有的线程都得到了 value 值 26 __syncthreads(); 27 28 // 最后一个线程块的 0 号线程输出总和,重置 count 29 if (isLastBlockDone) 30 { 31 float totalSum = calculateTotalSum(result); 32 if (threadIdx.x == 0) 33 { 34 35 result[0] = totalSum; 36 count = 0; 37 } 38 } 39 }
▶ 同步函数
● __syncthreads() 等待同一线程块内所有线程都达到该函数位置,且所有全局和共享内存对该线程块内所有线程都可见(缓存与内存已经同步)。以下三个扩展函数都具有这两项同步功能,并且附加了求值统计的功能。
●__syncthreads_count(int predicate) 同步,且返回参与同步的线程中,变量 predicate 非零的线程个数。
●__syncthreads_and(int predicate) 同步,且返回参与同步的线程中,所有变量 predicate 的逻辑且。
●__syncthreads_or(int predicate) 同步,且返回参与同步的线程中,所有变量 predicate 的逻辑或。
●__syncwarp(unsigned mask=0xffffffff) 正在执行的线程等待,直到有相同掩码的线程束通道都执行了该函数,然后各线程再继续往下执行。 所有在掩码中标明的非活跃的线程,也都必须使用相同的掩码执行相应的 __syncwarp(),否则结果是未定义的。执行 __syncwarp() 保证了参与栅栏同步的的线程之间的顺序。因此,同一线程束内所有希望通过内存进行通信的线程,可以先写入到内存,再执行 __syncwarp(),然后读取线程束中中其他线程写入的值。(?) 对于 .target sm_6x 或更低的目标版本,掩码中的所有线程必须执行 __syncwarp(),且掩码中所有值的并集必须与活动掩码相等。否则,行为是未定义的。
1 // device_functions.h 2 __DEVICE_FUNCTIONS_DECL__ __device_builtin__ void __syncthreads(void); 3 // device_functions.hpp 4 __DEVICE_FUNCTIONS_STATIC_DECL__ int __syncthreads_count(int predicate) 5 { 6 return __nvvm_bar0_popc(predicate); 7 } 8 9 __DEVICE_FUNCTIONS_STATIC_DECL__ int __syncthreads_and(int predicate) 10 { 11 return __nvvm_bar0_and(predicate); 12 } 13 14 __DEVICE_FUNCTIONS_STATIC_DECL__ int __syncthreads_or(int predicate) 15 { 16 return __nvvm_bar0_or(predicate); 17 }

