

▶ 图形互操作性,OpenGL 与 Direct3D 相关。(没学过,等待填坑)
▶ 版本号与计算能力
● 计算能力(Compute Capability)表征了硬件规格,CUDA版本号表征了驱动接口和运行时接口的(软件)规格。
● Driver API 的版本号定义在在驱动头文件中的宏 CUDA_VERSION 中。
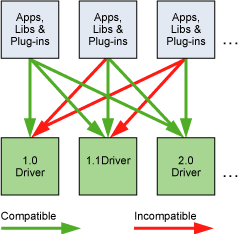
● 原文,理解 Driver API 向后兼容以及非向前兼容。This is important, because the driver API is backward compatible, meaning that applications, plug-ins, and libraries (including the C runtime) compiled against a particular version of the driver API will continue to work on subsequent device driver releases as illustrated in Figure 11. The driver API is not forward compatible, which means that applications, plug-ins, and libraries (including the C runtime) compiled against a particular version of the driver API will not work on previous versions of the device driver.
● 计算模式。可以在 NVIDIA 系统管理界面 nvidia-smi(驱动内含)中改变计算模式。
■ 默认模式:多条主机线程可以同时使用一台设备(Runtime API 中使用函数 cudaSetDevice(),或 Driver API 中把当前上下文绑定到设备上)。
■ 独占进程计算模式:一台设备只能有一个主机进程创建一个 CUDA 上下文,
■ 独占进程和线程计算模式:一台设备只能有一个主机进程创建 CUDA 上下文,且该进程内可以有多条线程分别创建该设备的上下文。
■ 禁止计算模式:一台设备只能有一个主机进程创建 CUDA 上下文,且该进程内同一时刻只能由一条线程创建该设备的上下文。
■ 主机线程使用 Runtime API 时没有显式调用 cudaSetDevice() 来规定设备号,有可能使用到非默认的设备(非 0 号设备)。例如 0 号设备正被其他进程占用为使用独占进程模式,或整备其他进程的线程占用为独占进程和线程模式,或主语禁止计算模式。这时可以使用函数 cudaSetValidDevices() 来找到当前可利用的设备。
■ Pascal 构架(CC 6.X)以上支持计算优先级,提供指令粒度的优先,而不仅是线程块粒度的优先,上下文交换有效减少长时间占用资源的计算。可以使用函数 cudaDeviceGetAttribute() 查询属性 cudaDevAttrComputePreemptionSupported 的值来确认设备是否支持计算优先级。使用进程独占计算模式可以避免发生上下文交换而降低效率。
1 // cuda_runtime_api.h 2 __device__ __attribute__((nv_weak)) cudaError_t cudaDeviceGetAttribute(int *value, enum cudaDeviceAttr attr, int device) 3 { 4 return cudaErrorUnknown; 5 } 6 7 // driver_types.h 8 enum __device_builtin__ cudaDeviceAttr 9 { 10 cudaDevAttrMaxThreadsPerBlock = 1, /**< Maximum number of threads per block */ 11 cudaDevAttrMaxBlockDimX = 2, /**< Maximum block dimension X */ 12 cudaDevAttrMaxBlockDimY = 3, /**< Maximum block dimension Y */ 13 cudaDevAttrMaxBlockDimZ = 4, /**< Maximum block dimension Z */ 14 cudaDevAttrMaxGridDimX = 5, /**< Maximum grid dimension X */ 15 cudaDevAttrMaxGridDimY = 6, /**< Maximum grid dimension Y */ 16 cudaDevAttrMaxGridDimZ = 7, /**< Maximum grid dimension Z */ 17 cudaDevAttrMaxSharedMemoryPerBlock = 8, /**< Maximum shared memory available per block in bytes */ 18 cudaDevAttrTotalConstantMemory = 9, /**< Memory available on device for __constant__ variables in a CUDA C kernel in bytes */ 19 cudaDevAttrWarpSize = 10, /**< Warp size in threads */ 20 cudaDevAttrMaxPitch = 11, /**< Maximum pitch in bytes allowed by memory copies */ 21 cudaDevAttrMaxRegistersPerBlock = 12, /**< Maximum number of 32-bit registers available per block */ 22 cudaDevAttrClockRate = 13, /**< Peak clock frequency in kilohertz */ 23 cudaDevAttrTextureAlignment = 14, /**< Alignment requirement for textures */ 24 cudaDevAttrGpuOverlap = 15, /**< Device can possibly copy memory and execute a kernel concurrently */ 25 cudaDevAttrMultiProcessorCount = 16, /**< Number of multiprocessors on device */ 26 cudaDevAttrKernelExecTimeout = 17, /**< Specifies whether there is a run time limit on kernels */ 27 cudaDevAttrIntegrated = 18, /**< Device is integrated with host memory */ 28 cudaDevAttrCanMapHostMemory = 19, /**< Device can map host memory into CUDA address space */ 29 cudaDevAttrComputeMode = 20, /**< Compute mode (See ::cudaComputeMode for details) */ 30 cudaDevAttrMaxTexture1DWidth = 21, /**< Maximum 1D texture width */ 31 cudaDevAttrMaxTexture2DWidth = 22, /**< Maximum 2D texture width */ 32 cudaDevAttrMaxTexture2DHeight = 23, /**< Maximum 2D texture height */ 33 cudaDevAttrMaxTexture3DWidth = 24, /**< Maximum 3D texture width */ 34 cudaDevAttrMaxTexture3DHeight = 25, /**< Maximum 3D texture height */ 35 cudaDevAttrMaxTexture3DDepth = 26, /**< Maximum 3D texture depth */ 36 cudaDevAttrMaxTexture2DLayeredWidth = 27, /**< Maximum 2D layered texture width */ 37 cudaDevAttrMaxTexture2DLayeredHeight = 28, /**< Maximum 2D layered texture height */ 38 cudaDevAttrMaxTexture2DLayeredLayers = 29, /**< Maximum layers in a 2D layered texture */ 39 cudaDevAttrSurfaceAlignment = 30, /**< Alignment requirement for surfaces */ 40 cudaDevAttrConcurrentKernels = 31, /**< Device can possibly execute multiple kernels concurrently */ 41 cudaDevAttrEccEnabled = 32, /**< Device has ECC support enabled */ 42 cudaDevAttrPciBusId = 33, /**< PCI bus ID of the device */ 43 cudaDevAttrPciDeviceId = 34, /**< PCI device ID of the device */ 44 cudaDevAttrTccDriver = 35, /**< Device is using TCC driver model */ 45 cudaDevAttrMemoryClockRate = 36, /**< Peak memory clock frequency in kilohertz */ 46 cudaDevAttrGlobalMemoryBusWidth = 37, /**< Global memory bus width in bits */ 47 cudaDevAttrL2CacheSize = 38, /**< Size of L2 cache in bytes */ 48 cudaDevAttrMaxThreadsPerMultiProcessor = 39, /**< Maximum resident threads per multiprocessor */ 49 cudaDevAttrAsyncEngineCount = 40, /**< Number of asynchronous engines */ 50 cudaDevAttrUnifiedAddressing = 41, /**< Device shares a unified address space with the host */ 51 cudaDevAttrMaxTexture1DLayeredWidth = 42, /**< Maximum 1D layered texture width */ 52 cudaDevAttrMaxTexture1DLayeredLayers = 43, /**< Maximum layers in a 1D layered texture */ 53 cudaDevAttrMaxTexture2DGatherWidth = 45, /**< Maximum 2D texture width if cudaArrayTextureGather is set */ 54 cudaDevAttrMaxTexture2DGatherHeight = 46, /**< Maximum 2D texture height if cudaArrayTextureGather is set */ 55 cudaDevAttrMaxTexture3DWidthAlt = 47, /**< Alternate maximum 3D texture width */ 56 cudaDevAttrMaxTexture3DHeightAlt = 48, /**< Alternate maximum 3D texture height */ 57 cudaDevAttrMaxTexture3DDepthAlt = 49, /**< Alternate maximum 3D texture depth */ 58 cudaDevAttrPciDomainId = 50, /**< PCI domain ID of the device */ 59 cudaDevAttrTexturePitchAlignment = 51, /**< Pitch alignment requirement for textures */ 60 cudaDevAttrMaxTextureCubemapWidth = 52, /**< Maximum cubemap texture width/height */ 61 cudaDevAttrMaxTextureCubemapLayeredWidth = 53, /**< Maximum cubemap layered texture width/height */ 62 cudaDevAttrMaxTextureCubemapLayeredLayers = 54, /**< Maximum layers in a cubemap layered texture */ 63 cudaDevAttrMaxSurface1DWidth = 55, /**< Maximum 1D surface width */ 64 cudaDevAttrMaxSurface2DWidth = 56, /**< Maximum 2D surface width */ 65 cudaDevAttrMaxSurface2DHeight = 57, /**< Maximum 2D surface height */ 66 cudaDevAttrMaxSurface3DWidth = 58, /**< Maximum 3D surface width */ 67 cudaDevAttrMaxSurface3DHeight = 59, /**< Maximum 3D surface height */ 68 cudaDevAttrMaxSurface3DDepth = 60, /**< Maximum 3D surface depth */ 69 cudaDevAttrMaxSurface1DLayeredWidth = 61, /**< Maximum 1D layered surface width */ 70 cudaDevAttrMaxSurface1DLayeredLayers = 62, /**< Maximum layers in a 1D layered surface */ 71 cudaDevAttrMaxSurface2DLayeredWidth = 63, /**< Maximum 2D layered surface width */ 72 cudaDevAttrMaxSurface2DLayeredHeight = 64, /**< Maximum 2D layered surface height */ 73 cudaDevAttrMaxSurface2DLayeredLayers = 65, /**< Maximum layers in a 2D layered surface */ 74 cudaDevAttrMaxSurfaceCubemapWidth = 66, /**< Maximum cubemap surface width */ 75 cudaDevAttrMaxSurfaceCubemapLayeredWidth = 67, /**< Maximum cubemap layered surface width */ 76 cudaDevAttrMaxSurfaceCubemapLayeredLayers = 68, /**< Maximum layers in a cubemap layered surface */ 77 cudaDevAttrMaxTexture1DLinearWidth = 69, /**< Maximum 1D linear texture width */ 78 cudaDevAttrMaxTexture2DLinearWidth = 70, /**< Maximum 2D linear texture width */ 79 cudaDevAttrMaxTexture2DLinearHeight = 71, /**< Maximum 2D linear texture height */ 80 cudaDevAttrMaxTexture2DLinearPitch = 72, /**< Maximum 2D linear texture pitch in bytes */ 81 cudaDevAttrMaxTexture2DMipmappedWidth = 73, /**< Maximum mipmapped 2D texture width */ 82 cudaDevAttrMaxTexture2DMipmappedHeight = 74, /**< Maximum mipmapped 2D texture height */ 83 cudaDevAttrComputeCapabilityMajor = 75, /**< Major compute capability version number */ 84 cudaDevAttrComputeCapabilityMinor = 76, /**< Minor compute capability version number */ 85 cudaDevAttrMaxTexture1DMipmappedWidth = 77, /**< Maximum mipmapped 1D texture width */ 86 cudaDevAttrStreamPrioritiesSupported = 78, /**< Device supports stream priorities */ 87 cudaDevAttrGlobalL1CacheSupported = 79, /**< Device supports caching globals in L1 */ 88 cudaDevAttrLocalL1CacheSupported = 80, /**< Device supports caching locals in L1 */ 89 cudaDevAttrMaxSharedMemoryPerMultiprocessor = 81, /**< Maximum shared memory available per multiprocessor in bytes */ 90 cudaDevAttrMaxRegistersPerMultiprocessor = 82, /**< Maximum number of 32-bit registers available per multiprocessor */ 91 cudaDevAttrManagedMemory = 83, /**< Device can allocate managed memory on this system */ 92 cudaDevAttrIsMultiGpuBoard = 84, /**< Device is on a multi-GPU board */ 93 cudaDevAttrMultiGpuBoardGroupID = 85, /**< Unique identifier for a group of devices on the same multi-GPU board */ 94 cudaDevAttrHostNativeAtomicSupported = 86, /**< Link between the device and the host supports native atomic operations */ 95 cudaDevAttrSingleToDoublePrecisionPerfRatio = 87, /**< Ratio of single precision performance (in floating-point operations per second) to double precision performance */ 96 cudaDevAttrPageableMemoryAccess = 88, /**< Device supports coherently accessing pageable memory without calling cudaHostRegister on it */ 97 cudaDevAttrConcurrentManagedAccess = 89, /**< Device can coherently access managed memory concurrently with the CPU */ 98 cudaDevAttrComputePreemptionSupported = 90, /**< Device supports Compute Preemption */ 99 cudaDevAttrCanUseHostPointerForRegisteredMem = 91 /**< Device can access host registered memory at the same virtual address as the CPU */ 100 };
▶ 模式开关。GPU有一部分保留显存专用于刷新屏幕显示,称为初级表面(primary surface),当用户通过控制面板改变屏幕的分辨率或者色彩深度时,这部分内存大小会发生变化。抗锯齿效果,某些全屏运行的 DirectX 程序,或是 Windows 自带特效(Alt + Tab,Ctrl + Alt + Del)等都会影响。这部分内存会与 CUDA 应用竞争显存,导致 Runtime 和上下文错误。
▶ Windows 集群模式。Teslia 和 Quadro 独享,允许非集显的显卡集群(非 NIVIDIA 也可);允许 GPU 供远程桌面使用;允许GPU作为 Windows 服务进行运作。
4. 硬件实现
▶ 流处理器的单指令多线程架构(Single-Instruction Multiple-Thread,SIMT)。
▶ 同一线程束中的所有线程共享相同的程序地址,但各自独享指令地址计数器和寄存器。还有半线程束和四分之一线程束的概念。
▶ Volta 架构开始有独立线程调度,允许单线程粒度的完全并行,所有线程各自独享程序计数器和堆栈。调度优化器优化了有数据依赖的线程关系,并且整合活跃线程到 SIMT 单元中,使得可以在亚线程束的水平上运行线程分支和合并。但是线程执行顺序和同步性进一步打乱,在编程时要慎重考虑。
5. 性能准则
▶ 总体优化准则。最大化并行执行来实现最大利用率;优化内存利用来实现最大内存带宽;优化指令来实现最大指令带宽。
▶ 一个线程束准备执行下一个指令所需要的时钟周期数称为潜伏期(延迟)。若 SM 的线程束调度过程中,在每个时钟周期总有可以执行下一条指令的线程束,则认为延迟被“隐藏”了。各指令的带宽影响其可隐藏的时钟周期数。计算能力 3.X 以上的设备完全隐藏延迟的条件下,一个 SM 在一个时钟周期内可以同时处理四个线程束中的各一对指令,总共 8 条指令。
▶ 流处理器中,给定线程束的下一条指令不能立即执行的重要原因是,该指令的输入还没有准备好。有可能是寄存器读取延迟(片外存储延迟有200 ~ 400时钟周期),或寄存器依赖于上一条指令的运行结果(依赖于上一条指令的执行时间),或等待同步(依赖于最慢的线程后线程块的运行)。
▶ 编译时使用选项 -ptxas-options=-v 可以查看寄存器和共享内存的占用情况,使用选项 maxrregcount 来规定线程使用的寄存器数量。
▶ 每个 double 和 long long 类型占用两个寄存器。
▶计算占用率的函数。cudaOccupancyMaxActiveBlocksPerMultiprocessor(),cudaOccupancyMaxPotentialBlockSize (),cudaOccupancyMaxPotentialBlockSizeVariableSMem().。没看懂 minGridSize的作用。
1 #include <stdio.h> 2 #include <malloc.h> 3 #include <cuda_runtime.h> 4 #include "device_launch_parameters.h" 5 6 #define N 2024*12+117 7 #define CEIL(x,y) (1 + ((x) - 1) / (y)) 8 9 __global__ void myKernel(float *a, int length) 10 { 11 int idx = threadIdx.x + blockIdx.x * blockDim.x; 12 if (idx < length) 13 a[idx] += 1.0f; 14 } 15 16 // Host code 17 int main() 18 { 19 // 准备工作 20 printf("\n\tStart."); 21 22 int device; 23 cudaDeviceProp prop; 24 cudaGetDevice(&device); 25 cudaGetDeviceProperties(&prop, device); 26 27 int i, size; 28 float *h_data, *d_data; 29 30 size = sizeof(float) * N; 31 h_data = (float *)malloc(size); 32 cudaMalloc((void **)&d_data, size); 33 for (i = 0; i < N; i++) 34 h_data[i] = (float)i; 35 cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice); 36 37 // 设计最优线程格尺寸和线程块尺寸 38 int mingGridSize; // ?最小线程格尺寸,有可能比计算出来的 gridSize还要大? 39 int blockSize; // 线程块尺寸 40 int gridSize; // 实际线程格尺寸 41 42 cudaOccupancyMaxPotentialBlockSize(&mingGridSize, &blockSize, (void*)myKernel, 0, N); 43 printf("\n\tminGridSize = %d, blockSize = %d", mingGridSize, blockSize); 44 45 // 按给出的 blockSize 计算 46 gridSize = CEIL(N, blockSize); 47 myKernel << <gridSize, blockSize >> > (d_data, N); 48 cudaDeviceSynchronize(); 49 printf("\n\tgridSize = %d", gridSize); 50 51 // 计算占用率 52 int nBlock; // 实际每个SM中的线程块数量 53 int activeWarp; // 活动线程束数量 54 int maxWarp; // 最大线程数数量 55 cudaOccupancyMaxActiveBlocksPerMultiprocessor(&nBlock, myKernel, blockSize, 0); 56 activeWarp = nBlock * blockSize / prop.warpSize; 57 maxWarp = prop.maxThreadsPerMultiProcessor / prop.warpSize; 58 printf("\n\tnBlock = %d, occupancy = %3.1f %%", nBlock, (double)activeWarp / maxWarp * 100); 59 60 getchar(); 61 return 0; 62 }
■ 相关接口函数。
1 // cuda_runtime.h 2 emplate<class T> 3 static __inline__ __host__ CUDART_DEVICE cudaError_t cudaOccupancyMaxPotentialBlockSize 4 ( 5 int *minGridSize, // 输出最小线程格尺寸 6 int *blockSize, // 输出线程格尺寸 7 T func, // 核函数指针 8 size_t dynamicSMemSize = 0, // 共享内存字节数 9 int blockSizeLimit = 0 // 数组元素数量 10 ) 11 { 12 return cudaOccupancyMaxPotentialBlockSizeVariableSMemWithFlags(minGridSize, blockSize, func, __cudaOccupancyB2DHelper(dynamicSMemSize), blockSizeLimit, cudaOccupancyDefault); 13 } 14 15 // cuda_device_runtime.h 16 __device__ __attribute__((nv_weak)) cudaError_t cudaOccupancyMaxActiveBlocksPerMultiprocessor 17 ( 18 int *numBlocks, // 输出线程块数 19 const void *func, // 核函数指针 20 int blockSize, // 线程块尺寸 21 size_t dynamicSmemSize // 共享内存字节数 22 ) 23 { 24 return cudaErrorUnknown; 25 } 26 27 template<typename UnaryFunction, class T> 28 static __inline__ __host__ CUDART_DEVICE cudaError_t cudaOccupancyMaxPotentialBlockSizeVariableSMem 29 ( 30 int *minGridSize, 31 int *blockSize, 32 T func, 33 UnaryFunction blockSizeToDynamicSMemSize, 34 int blockSizeLimit = 0 35 ) 36 { 37 return cudaOccupancyMaxPotentialBlockSizeVariableSMemWithFlags(minGridSize, blockSize, func, blockSizeToDynamicSMemSize, blockSizeLimit, cudaOccupancyDefault); 38 }
▶ 优化存储的手段:减少主机和设备之间的数据传输,使用片上存储来加速数据使用(如共享内存和 L1 缓存用的是相同的片上存储,速度相近),合并内存访问和数据传输,使用页锁定内存等特殊存储方式。
▶ 设备全局内存访问事务有 4B,8B,16B 三种方式,一次全局内存读写是地址对齐到这三个值上进行的。当线程数执行一条全局内存访问指令时,它首先根据每条线程访问内存的字长及其地址分布,把各线程合并为一个或若干次访问,访问地址越发散或次数越多,延迟越高。
▶ 优化全局内存带宽的方法:使用最优的内存访问方式,使用满足内存对齐要求的的数据类型,存储数据时进行对齐。
▶ 尺寸和对齐要求。全局内存访问支持的字长有 1B,2B,4B,8B,16B。当且仅当数据类型的大小为这五种,且数据自然对齐时,对其访问会编译为一个单独的全局内存访问指令。否则对其访问会编译为多个指令,可能存在交叉访问,且不能进行合并内存访问优化。因此,建议使用满足对齐要求的数据类型。
▶ 驻留在全局内存中的变量,或是由内存申请函数返回的存储器,都至少对齐到256B。建议合并多个自定义的存储器为一个较大的存储器,以便统一对齐管理。
▶ 驻留在局地内存的自动变量类型:不能确定是否由常量索引引用的数组,占用大量寄存器空间的大型结构或数组,使用多于可用寄存器的变量(寄存器溢出)。
▶ PTX汇编代码检查。使用编译选项 -ptx 或 -keep检查变量在第一次编译阶段是否被放置在本地内存中(用记号 .local 声明,并用记号 ld.local 和 st.local 访问),即使该变量在第一编译阶段没有放在局部内存中,后续编译阶段内也有可能放进来(如后续过程中寄存器溢出);使用编译选项 --ptxas-options=-v 可以报告每个核函数的局部内存使用量(lmem),注意某些数学函数的实现也需要访问局部内存。
局部记忆使用ld.local和st.local记忆与访问。即使没有,后续的编译阶段可能还另有决定如果他们发现它消耗为目标的建筑太多的登记空间:检查古巴对象使用cuobjdump会告诉如果是这样的话。另外,编译器报告总使用本地内存每内核(LMEM)编译时,ptxas选项= -v选项。注意,一些数学函数有可能访问本地内存的实现路径。
▶ 局部内存访问是 4B 合并的,恰当调整线程访问方式可以提高访问效率。
▶ 计算能力 6.X 的设备总是将局部内存缓存在 L2 中。
▶ 纹理内存和表面内存是为流访问优化的,存在固定延迟,缓存命中时有效降低内存访问延迟,单并不会减少固定延迟。坐标计算由核外的专用计算单元完成,可以进行数据压缩和线程广播。
▶ 举例不同计算能力的设备,运行各种代数指令的速度差别

▶ 命令 cuobjdump 可用于反汇编 cubin 文件,查看代码中特殊实现的优化结果,可用于学习代码优化。
▶ __fdividef(a,b) 快速单精度浮点除法。
▶ CC6.1的设备中,函数 _syncthreads() 每时钟周期进行 64 次操作(?至多同步64条线程),CC7.0设备中每时钟周期进行 32 次操作。

