

▶ 纹理内存使用
● 纹理内存使用有两套 API,称为 Object API 和 Reference API 。纹理对象(texture object)在运行时被 Object API 创建,同时指定了纹理单元。纹理引用(Tezture Reference)在编译时被 Reference API 创建,但是在运行时才指定纹理单元,并将纹理引用绑定到纹理单元上面去。
● 不同的纹理引用可能绑定到相同或内存上有重叠的的纹理单元上,纹理单元可能是 CUDA 线性内存或CUDA array 的任意部分。
● 可以定义一维到三维的数组作为纹理内存。数组中的元素简称 texel (texture element)。
● 纹理内存的数据类型可以是 char, int, long, long long, float, double,即所有基本的占用1、2、4字节的数据类型。
● 纹理内存的访问模式有 cudaReadModeNormalizedFloat 和 cudaReadModeElementType 两种。前者读取 4 字节整数时会除以 0x8fff(有符号整数)或 0xffff(无符号整数),从而把值线性映射到 [-1.0, 1.0] 区间(有符号整数)或 [0, 1] 区间(无符号整数),读取 2 字节整数时也会发生类似变换,除以 0x8f 或 0xff 。后者则不会发生这种转换。
● 纹理数组使用浮点坐标进行引用。长为 N 的一维数组,默认纹理坐标中,下标范围是 [0.0, N-1] 之间的浮点数;正规化纹理坐标中,下标范围是 [0.0, 1-1/N] 之间的浮点数。二维或三维数组每一维上的坐标也遵循这个原则。
● 寻址模式,可以对数组范围以外的坐标进行访问(越界访问),不同的寻址模式定义了这种操作的效果。默认寻址模式 cudaAddressModeClamp 下,越界访问取各维上的边界值;边界模式 cudaAddressModeBorder 下,越界访问会返回 0 。使用正规化坐标时,可以选用束模式和镜像模式,束模式 cudaAddressModeWrap(想象成左右边界相连)下,越界坐标做变换 x' = x - floor(x) (教程上少了 减号);镜像模式 cudaAddressModeMirror(想象成 左 ~ 右 → 右 ~ 左 → 左 ~ 右)下,越界坐标做变换 x' = x(floor(x) 为偶数)或 x' = 1 - x(floor(x) 为奇数)。
● 滤波模式,决定了如何把整数坐标的数组数据值转化为浮点坐标的引用值。最临近插值 cudaFilterModePoint 使用最接近访问坐标的整数坐标点数据,可以返回整数值(若纹理数组本身是整数型);线性插值 cudaFilterModeLinear 使用每维度上最接近访问坐标的两个整数坐标点数据进行插值,可以单线性(一维,2 点)、双线性(二维,4 点)和三线性(三维,8 点),只能返回浮点数值。
● 使用 Texture Object API 。
■ 涉及的结构定义、接口函数。
1 // texture_types.h 2 struct __device_builtin__ cudaTextureDesc 3 { 4 enum cudaTextureAddressMode addressMode[3]; // 寻址模式,cudaResourceDesc::resType == cudaResourceTypeLinear 时无效 5 enum cudaTextureFilterMode filterMode; // 滤波模式,cudaResourceDesc::resType == cudaResourceTypeLinear 时无效 6 enum cudaTextureReadMode readMode; // 访问模式 7 int sRGB; // ?读取时将sRGB范围正规化 8 float borderColor[4]; // ?文理边界颜色 9 int normalizedCoords; // 是否使用正规化坐标 10 unsigned int maxAnisotropy; // ? 11 enum cudaTextureFilterMode mipmapFilterMode; // ? 12 float mipmapLevelBias; // ? 13 float minMipmapLevelClamp;// ? 14 float maxMipmapLevelClamp;// ? 15 }; 16 17 enum __device_builtin__ cudaTextureAddressMode 18 { 19 cudaAddressModeWrap = 0, 20 cudaAddressModeClamp = 1, 21 cudaAddressModeMirror = 2, 22 cudaAddressModeBorder = 3 23 }; 24 25 enum __device_builtin__ cudaTextureFilterMode 26 { 27 cudaFilterModePoint = 0, 28 cudaFilterModeLinear = 1 29 }; 30 31 enum __device_builtin__ cudaTextureReadMode 32 { 33 cudaReadModeElementType = 0, 34 cudaReadModeNormalizedFloat = 1 35 }; 36 37 typedef __device_builtin__ unsigned long long cudaTextureObject_t; 38 39 // driver_types.h 40 enum __device_builtin__ cudaChannelFormatKind 41 { 42 cudaChannelFormatKindSigned = 0, // 有符号整数模式 43 cudaChannelFormatKindUnsigned = 1, // 无符号整数模式 44 cudaChannelFormatKindFloat = 2, // 浮点模式 45 cudaChannelFormatKindNone = 3 // 无通道模式 46 }; 47 48 struct __device_builtin__ cudaChannelFormatDesc 49 { 50 int x; // 通道 0 数据位深度 51 int y; // 通道 1 数据位深度 52 int z; // 通道 2 数据位深度 53 int w; // ? 54 enum cudaChannelFormatKind f; // 通道模式 55 }; 56 57 typedef struct cudaArray *cudaArray_t; 58 typedef struct cudaMipmappedArray *cudaMipmappedArray_t; 59 60 enum __device_builtin__ cudaResourceType 61 { 62 cudaResourceTypeArray = 0x00, // 数组资源 63 cudaResourceTypeMipmappedArray = 0x01, // 映射数组资源 64 cudaResourceTypeLinear = 0x02, // 线性资源 65 cudaResourceTypePitch2D = 0x03 // 对齐二维资源 66 }; 67 68 struct __device_builtin__ cudaResourceDesc 69 { 70 enum cudaResourceType resType; // 资源类型 71 72 union res 73 { 74 struct array // cuda数组 75 { 76 cudaArray_t array; 77 }; 78 struct mipmap // mipmap 数组 79 { 80 cudaMipmappedArray_t mipmap; 81 }; 82 struct linear // 一维数组 83 { 84 void *devPtr; // 设备指针,符合 cudaDeviceProp::textureAlignment 的对齐要求 85 struct cudaChannelFormatDesc desc; // texel 的属性描述 86 size_t sizeInBytes; // 数组字节数 87 }; 88 struct pitch2D // 二位数组 89 { 90 void *devPtr; // 设备指针,符合 cudaDeviceProp::textureAlignment 的对齐要求 91 struct cudaChannelFormatDesc desc; // texel 的属性描述 92 size_t width; // 数组列数 93 size_t height; // 数组行数 94 size_t pitchInBytes; // 数组行字节数 95 }; 96 }; 97 }; 98 99 // cuda_runtime_api.h 100 101 extern __host__ struct cudaChannelFormatDesc CUDARTAPI cudaCreateChannelDesc(int x, int y, int z, int w, enum cudaChannelFormatKind f); 102 103 extern __host__ cudaError_t CUDARTAPI cudaMallocArray(cudaArray_t *array, const struct cudaChannelFormatDesc *desc, size_t width, size_t height __dv(0), unsigned int flags __dv(0)); 104 105 extern __host__ cudaError_t CUDARTAPI cudaMemcpyToArray(cudaArray_t dst, size_t wOffset, size_t hOffset, const void *src, size_t count, enum cudaMemcpyKind kind); 106 107 extern __host__ cudaError_t CUDARTAPI cudaCreateTextureObject(cudaTextureObject_t *pTexObject, const struct cudaResourceDesc *pResDesc, const struct cudaTextureDesc *pTexDesc, const struct cudaResourceViewDesc *pResViewDesc); 108 109 extern __host__ cudaError_t CUDARTAPI cudaDestroyTextureObject(cudaTextureObject_t texObject);
■ 完整的应用样例代码。初始化一个 32×32 的矩阵,利用纹理对其进行平移和旋转,输出调整之后的矩阵。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <malloc.h> 4 #include <cuda_runtime_api.h> 5 #include "device_launch_parameters.h" 6 7 #define DEGRE_TO_RADIAN(x) ((x) * 3.1416f / 180) 8 #define CEIL(x,y) (((x) + (y) - 1) / (y) + 1) 9 10 // 简单的线性变换 11 __global__ void transformKernel(float* output, cudaTextureObject_t texObj, int width, int height, float theta) 12 { 13 // 计算正规化纹理坐标 14 unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x; 15 unsigned int idy = blockIdx.y * blockDim.y + threadIdx.y; 16 17 // 正规化和平移 18 float u = idx / (float)width - 0.5f; 19 float v = idy / (float)height - 0.5f; 20 21 // 旋转 22 float tu = u * __cosf(theta) - v * __sinf(theta) + 0.5f; 23 float tv = v * __cosf(theta) + u * __sinf(theta) + 0.5f; 24 25 //printf("\n(%2d,%2d,%2d,%2d)->(%f,%f,%f)", 26 // blockIdx.x, blockIdx.y, threadIdx.x, threadIdx.y, tu, tv,tex2D<float>(texObj, tu, tv)); 27 28 // 纹理内存写入全局内存 29 output[idy * width + idx] = tex2D<float>(texObj, tu, tv); 30 } 31 32 int main() 33 { 34 // 基本数据 35 int i; 36 float *h_data, *d_data; 37 int width = 32; 38 int height = 32; 39 float angle = DEGRE_TO_RADIAN(30); 40 41 int size = sizeof(float)*width*height; 42 h_data = (float *)malloc(size); 43 cudaMalloc((void **)&d_data, size); 44 45 for (i = 0; i < width*height; i++) 46 h_data[i] = (float)i; 47 48 printf("\n\n"); 49 for (i = 0; i < width*height; i++) 50 { 51 printf("%6.1f ", h_data[i]); 52 if ((i + 1) % width == 0) 53 printf("\n"); 54 } 55 56 // 申请 cuda 数组并拷贝数据 57 cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc(32, 0, 0, 0,cudaChannelFormatKindFloat); 58 cudaArray* cuArray; 59 cudaMallocArray(&cuArray, &channelDesc, width, height); 60 cudaMemcpyToArray(cuArray, 0, 0, h_data, size, cudaMemcpyHostToDevice); 61 62 // 指定纹理资源 63 struct cudaResourceDesc resDesc; 64 memset(&resDesc, 0, sizeof(resDesc)); 65 resDesc.resType = cudaResourceTypeArray; 66 resDesc.res.array.array = cuArray; 67 68 // 指定纹理对象参数 69 struct cudaTextureDesc texDesc; 70 memset(&texDesc, 0, sizeof(texDesc)); 71 texDesc.addressMode[0] = cudaAddressModeWrap; 72 texDesc.addressMode[1] = cudaAddressModeWrap; 73 texDesc.filterMode = cudaFilterModeLinear; 74 texDesc.readMode = cudaReadModeElementType; 75 texDesc.normalizedCoords = 1; 76 77 // 创建文理对象 78 cudaTextureObject_t texObj = 0; 79 cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL); 80 81 // 运行核函数 82 dim3 dimBlock(16, 16); 83 dim3 dimGrid(CEIL(width, dimBlock.x), CEIL(height, dimBlock.y)); 84 transformKernel << <dimGrid, dimBlock >> > (d_data, texObj, width, height, angle); 85 cudaDeviceSynchronize(); 86 87 // 结果回收和检查结果 88 cudaMemcpy(h_data, d_data, size, cudaMemcpyDeviceToHost); 89 90 printf("\n\n"); 91 for (i = 0; i < width*height; i++) 92 { 93 printf("%6.1f ", h_data[i]); 94 if ((i + 1) % width == 0) 95 printf("\n"); 96 } 97 98 // 回收工作 99 cudaDestroyTextureObject(texObj); 100 cudaFreeArray(cuArray); 101 cudaFree(d_data); 102 103 getchar(); 104 return 0; 105 }
● 使用 Texture Reference API。
■ 纹理引用的一些只读属性需要在声明的时候指定,以便编译时提前确定,只能在全局作用域内静态指定,不能作为参数传递给函数。使用 texture 指定纹理引用属性,Datatype 为 texel 的数据类型,Type 为纹理引用类型,有 7 种,默认 cudaTextureType1D,ReadMode 为访问类型,默认 cudaReadModeElementType ,其他属性可以在主机运行时动态的修改。
1 texture<DataType, Type, ReadMode> texRef; 2 3 // cuda_texture_types.h 4 template<class T, int texType = cudaTextureType1D, enum cudaTextureReadMode mode = cudaReadModeElementType> 5 struct __device_builtin_texture_type__ texture : public textureReference 6 { 7 #if !defined(__CUDACC_RTC__) 8 __host__ texture(int norm = 0, enum cudaTextureFilterMode fMode = cudaFilterModePoint, enum cudaTextureAddressMode aMode = cudaAddressModeClamp) 9 { 10 normalized = norm; 11 filterMode = fMode; 12 addressMode[0] = aMode; 13 addressMode[1] = aMode; 14 addressMode[2] = aMode; 15 channelDesc = cudaCreateChannelDesc<T>(); 16 sRGB = 0; 17 } 18 __host__ texture(int norm, enum cudaTextureFilterMode fMode, enum cudaTextureAddressMode aMode, struct cudaChannelFormatDesc desc) 19 { 20 normalized = norm; 21 filterMode = fMode; 22 addressMode[0] = aMode; 23 addressMode[1] = aMode; 24 addressMode[2] = aMode; 25 channelDesc = desc; 26 sRGB = 0; 27 } 28 #endif 29 }; 30 31 //texture_types.h 32 #define cudaTextureType1D 0x01 33 #define cudaTextureType2D 0x02 34 #define cudaTextureType3D 0x03 35 #define cudaTextureTypeCubemap 0x0C 36 #define cudaTextureType1DLayered 0xF1 37 #define cudaTextureType2DLayered 0xF2 38 #define cudaTextureTypeCubemapLayered 0xFC
■ 涉及的结构定义、接口函数。纹理引用必须用函数 cudaBindTexture() 或 cudaBindTexture2D() 或 cudaBindTextureToArray() 绑定到相应维度的数组上才能使用,要求纹理引用的维度、数据类型与该数组匹配,否则操作时未定义的,使用完后还要用函数 cudaUnbindTexture() 解除绑定。
1 // texture_types.h 2 struct __device_builtin__ textureReference 3 { 4 int normalized; // 是否使用正规化坐标 5 enum cudaTextureFilterMode filterMode; // 滤波模式 6 enum cudaTextureAddressMode addressMode[3]; // 寻址模式 7 struct cudaChannelFormatDesc channelDesc; // texel 的格式,其元素数据类型与声明 texture 时的 Datatype 一致 8 int sRGB; // ?读取时将sRGB范围正规化 9 unsigned int maxAnisotropy; // ? 10 enum cudaTextureFilterMode mipmapFilterMode; // ? 11 float mipmapLevelBias; // ? 12 float minMipmapLevelClamp; // ? 13 float maxMipmapLevelClamp; // ? 14 int __cudaReserved[15]; // ? 15 }; 16 17 // cuda_runtime_api.h 18 extern __host__ cudaError_t CUDARTAPI cudaBindTexture(size_t *offset, const struct textureReference *texref, const void *devPtr, const struct cudaChannelFormatDesc *desc, size_t size __dv(UINT_MAX)); 19 20 extern __host__ cudaError_t CUDARTAPI cudaBindTexture2D(size_t *offset, const struct textureReference *texref, const void *devPtr, const struct cudaChannelFormatDesc *desc, size_t width, size_t height, size_t pitch); 21 22 extern __host__ cudaError_t CUDARTAPI cudaBindTextureToArray(const struct textureReference *texref, cudaArray_const_t array, const struct cudaChannelFormatDesc *desc); 23 24 extern __host__ cudaError_t CUDARTAPI cudaUnbindTexture(const struct textureReference *texref); 25 26 extern __host__ cudaError_t CUDARTAPI cudaGetTextureReference(const struct textureReference **texref, const void *symbol);
■ 将 2D 纹理引用绑定到 2D 数组上的范例代码
1 // 准备工作 2 texture<float, cudaTextureType2D, cudaReadModeElementType> texRef; 3 4 ... 5 6 int width, height; 7 size_t pitch; 8 float *d_data; 9 cudaMallocPitch((void **)&d_data, &pitch, sizeof(float)*width, height); 10 11 // 第一种方法,低层 API 12 textureReference* texRefPtr; 13 cudaGetTextureReference(&texRefPtr, &texRef); 14 cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>(); 15 size_t offset; 16 cudaBindTexture2D(&offset, texRefPtr, d_data, &channelDesc, width, height, pitch); 17 18 // 第二种方法,高层 API 19 cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>(); 20 size_t offset; 21 cudaBindTexture2D(&offset, texRef, d_data, channelDesc, width, height, pitch);
■ 将 2D 纹理引用绑定到 cuda 数组上的范例代码
1 // 准备工作 2 texture<float, cudaTextureType2D, cudaReadModeElementType> texRef; 3 4 //... 5 6 cudaArray* cuArray; 7 cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat); 8 cudaMallocArray(&cuArray, &channelDesc, width, height); 9 10 // 第一种方法,低层 API 11 textureReference* texRefPtr; 12 cudaGetTextureReference(&texRefPtr, &texRef); 13 memset(&channelDesc, 0, sizeof(cudaChannelFormatDesc)); 14 cudaChannelFormatDesc channelDesc; 15 cudaGetChannelDesc(&channelDesc, cuArray); 16 cudaBindTextureToArray(texRef, cuArray, &channelDesc); 17 18 // 第二种方法,高层 API 19 cudaBindTextureToArray(texRef, cuArray);
■ 完整的应用样例代码。与前面纹理对象代码的功能相同。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <malloc.h> 4 #include <cuda_runtime_api.h> 5 #include "device_launch_parameters.h" 6 7 #define DEGRE_TO_RADIAN(x) ((x) * 3.1416f / 180) 8 #define CEIL(x,y) (((x) + (y) - 1) / (y) + 1) 9 10 // 声明纹理引用 11 texture<float, cudaTextureType2D, cudaReadModeElementType> texRef; 12 13 // 简单的线性变换 14 __global__ void transformKernel(float* output, int width, int height, float theta) 15 { 16 // 计算正规化纹理坐标 17 unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x; 18 unsigned int idy = blockIdx.y * blockDim.y + threadIdx.y; 19 20 // 正规化和平移 21 float u = idx / (float)width; 22 float v = idy / (float)height; 23 24 // 旋转 25 float tu = u * __cosf(theta) - v * __sinf(theta) + 0.5f; 26 float tv = v * __cosf(theta) + u * __sinf(theta) + 0.5f; 27 28 //printf("\n(%2d,%2d,%2d,%2d)->(%f,%f,%f)", 29 // blockIdx.x, blockIdx.y, threadIdx.x, threadIdx.y, tu, tv,tex2D<float>(texObj, tu, tv)); 30 31 // 纹理内存写入全局内存 32 output[idy * width + idx] = tex2D(texRef, tu, tv); 33 } 34 35 int main() 36 { 37 // 基本数据 38 int i; 39 float *h_data, *d_data; 40 int width = 32; 41 int height = 32; 42 float angle = DEGRE_TO_RADIAN(30); 43 44 int size = sizeof(float)*width*height; 45 h_data = (float *)malloc(size); 46 cudaMalloc((void **)&d_data, size); 47 48 for (i = 0; i < width*height; i++) 49 h_data[i] = (float)i; 50 51 printf("\n\n"); 52 for (i = 0; i < width*height; i++) 53 { 54 printf("%6.1f ", h_data[i]); 55 if ((i + 1) % width == 0) 56 printf("\n"); 57 } 58 59 // 申请 cuda 数组并拷贝数据 60 cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc(32, 0, 0, 0, cudaChannelFormatKindFloat); 61 cudaArray* cuArray; 62 cudaMallocArray(&cuArray, &channelDesc, width, height); 63 cudaMemcpyToArray(cuArray, 0, 0, h_data, size, cudaMemcpyHostToDevice); 64 65 // 指定纹理引用参数,注意与纹理对象的使用不一样 66 texRef.addressMode[0] = cudaAddressModeWrap; 67 texRef.addressMode[1] = cudaAddressModeWrap; 68 texRef.filterMode = cudaFilterModeLinear; 69 texRef.normalized = 1; 70 71 // 绑定纹理引用 72 cudaBindTextureToArray(texRef, cuArray, channelDesc); 73 74 // 运行核函数 75 dim3 dimBlock(16, 16); 76 dim3 dimGrid(CEIL(width, dimBlock.x), CEIL(height, dimBlock.y)); 77 transformKernel << <dimGrid, dimBlock >> > (d_data, width, height, angle); 78 cudaDeviceSynchronize(); 79 80 // 结果回收和检查结果 81 cudaMemcpy(h_data, d_data, size, cudaMemcpyDeviceToHost); 82 83 printf("\n\n"); 84 for (i = 0; i < width*height; i++) 85 { 86 printf("%6.1f ", h_data[i]); 87 if ((i + 1) % width == 0) 88 printf("\n"); 89 } 90 91 // 回收工作 92 cudaFreeArray(cuArray); 93 cudaFree(d_data); 94 95 getchar(); 96 return 0; 97 }
▶ 半精度浮点数。
■ CUDA 没有原生支持半精度浮点数据类型,可以把半精度数据存储在 short 数据类型中,在需要计算的时候用内建函数将其与浮点类型进行转换。
■ 这些函数只能在设备代码中使用,可以在 OpenEXR 库中找到其等价的函数。
■ 在纹理计算过程中,半精度浮点数默认转化为单精度浮点数。
1 // cuda_fp16.h 2 __CUDA_FP16_DECL__ float __half2float(const __half h) 3 { 4 float val; 5 asm volatile("{ cvt.f32.f16 %0, %1;}\n" : "=f"(val) : "h"(h.x)); 6 return val; 7 } 8 __CUDA_FP16_DECL__ __half2 __float2half2_rn(const float f) 9 { 10 __half2 val; 11 asm("{.reg .f16 low;\n" 12 " cvt.rn.f16.f32 low, %1;\n" 13 " mov.b32 %0, {low,low};}\n" : "=r"(val.x) : "f"(f)); 14 return val; 15 }
▶ 分层纹理 Layered Texture
● 在 Direct3D 中叫 texture array,在 OpenGL 中叫 array texture 。
● 一组分层纹理是由若干相同维度、尺寸和数据类型的的纹理内存构成的,相当于多了一个整数下标的维度。支持一维分层纹理和二维分层纹理。
● 一维分层纹理使用一个整数和一个浮点数作为坐标进行访问;二维分层纹理使用一个整数和两个浮点数作为坐标进行访问。
● 分层纹理只能使用函数 cudaMalloc3DArray() 加上 cudaArrayLayered 标志来声明,使用函数 tex1DLayered() 和 tex2DLayered() 来进行访问。滤波只在同一层内部进行,不会跨层执行。
● 分层纹理在书《CUDA专家手册》中讲的稍微详细一点,看完再来填坑。
▶ 立方体贴图纹理 Cubemap Textures
● 一种特殊的二维分层纹理,共六个尺寸相同的、宽度等于高度的二维纹理构成,代表了正方体的六个面。
● 使用三个浮点数的有序组 (x, y, z) 来定义立方体贴图纹理的层号和表面坐标,按照以下表格分情况讨论。各表面坐标按照((s / m + 1) / 2, (t / m + 1) / 2)计算。
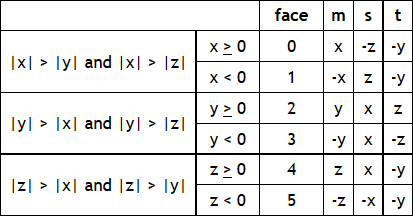
● 立方体贴图纹理只能使用函数 cudaMalloc3DArray() 加上 cudaArrayCubemap 标志来声明,使用函数 texCubemap() 来访问。
▶ 分层立方体贴图纹理 Cubemap Layered Textures
● 一种分层纹理内存,由若干尺寸相同的立方体贴图纹理构成。使用一个整数下标和三个浮点数有序组来定义层号和面号、表面坐标。
● 分层立方体贴图纹理只能使用函数 cudaMAlloc3DArray() 加上 cudaArrayLayered 和 cudaArrayCubemap 标志来声明,使用函数 texCubemapLayered() 来进行访问滤波只在同一层内部进行,不会跨层执行。
▶ 纹理汇集。
● 使用函数 tex2Dgather() 来抽取二维纹理内存的特定内容,没看懂。
1 // texture_fetch_functions.h 2 template <typename T> 3 static __device__ typename __nv_tex2dgather_ret<T>::type tex2Dgather(texture<T, cudaTextureType2D, cudaReadModeElementType>, float, float, int = 0) { }
▶ 压缩版的 texture_types.h。所有内容在本文中都有体现。
1 #if !defined(__TEXTURE_TYPES_H__) 2 #define __TEXTURE_TYPES_H__ 3 4 #include "driver_types.h" 5 6 #define cudaTextureType1D 0x01 7 #define cudaTextureType2D 0x02 8 #define cudaTextureType3D 0x03 9 #define cudaTextureTypeCubemap 0x0C 10 #define cudaTextureType1DLayered 0xF1 11 #define cudaTextureType2DLayered 0xF2 12 #define cudaTextureTypeCubemapLayered 0xFC 13 14 // CUDA texture address modes 15 enum __device_builtin__ cudaTextureAddressMode 16 { 17 cudaAddressModeWrap = 0, // Wrapping address mode 18 cudaAddressModeClamp = 1, // Clamp to edge address mode 19 cudaAddressModeMirror = 2, // Mirror address mode 20 cudaAddressModeBorder = 3 // Border address mode 21 }; 22 23 // CUDA texture filter modes 24 enum __device_builtin__ cudaTextureFilterMode 25 { 26 cudaFilterModePoint = 0, // Point filter mode 27 cudaFilterModeLinear = 1 // Linear filter mode 28 }; 29 30 // CUDA texture read modes 31 enum __device_builtin__ cudaTextureReadMode 32 { 33 cudaReadModeElementType = 0, // Read texture as specified element type 34 cudaReadModeNormalizedFloat = 1 // Read texture as normalized float 35 }; 36 37 // CUDA texture reference 38 struct __device_builtin__ textureReference 39 { 40 // Indicates whether texture reads are normalized or not 41 int normalized; 42 // Texture filter mode 43 enum cudaTextureFilterMode filterMode; 44 // Texture address mode for up to 3 dimensions 45 enum cudaTextureAddressMode addressMode[3]; 46 // Channel descriptor for the texture reference 47 struct cudaChannelFormatDesc channelDesc; 48 // Perform sRGB->linear conversion during texture read 49 int sRGB; 50 // Limit to the anisotropy ratio 51 unsigned int maxAnisotropy; 52 // Mipmap filter mode 53 enum cudaTextureFilterMode mipmapFilterMode; 54 // Offset applied to the supplied mipmap level 55 float mipmapLevelBias; 56 // Lower end of the mipmap level range to clamp access to 57 float minMipmapLevelClamp; 58 // Upper end of the mipmap level range to clamp access to 59 float maxMipmapLevelClamp; 60 int __cudaReserved[15]; 61 }; 62 63 // CUDA texture descriptor 64 struct __device_builtin__ cudaTextureDesc 65 { 66 // Texture address mode for up to 3 dimensions 67 enum cudaTextureAddressMode addressMode[3]; 68 // Texture filter mode 69 enum cudaTextureFilterMode filterMode; 70 // Texture read mode 71 enum cudaTextureReadMode readMode; 72 // Perform sRGB->linear conversion during texture read 73 int sRGB; 74 // Texture Border Color 75 float borderColor[4]; 76 // Indicates whether texture reads are normalized or not 77 int normalizedCoords; 78 // Limit to the anisotropy ratio 79 unsigned int maxAnisotropy; 80 // Mipmap filter mode 81 enum cudaTextureFilterMode mipmapFilterMode; 82 // Offset applied to the supplied mipmap level 83 float mipmapLevelBias; 84 // Lower end of the mipmap level range to clamp access to 85 float minMipmapLevelClamp; 86 // Upper end of the mipmap level range to clamp access to 87 float maxMipmapLevelClamp; 88 }; 89 90 // An opaque value that represents a CUDA texture object 91 typedef __device_builtin__ unsigned long long cudaTextureObject_t; 92 93 #endif

