

0. APOD过程
● 评估。分析代码运行时间的组成,对瓶颈进行并行化设计。了解需求和约束条件,确定应用程序的加速性能改善的上限。
● 并行化。根据原来的代码,采用一些手段进行并行化,例如使用现有库,或加入一些预处理指令等。同时需要代码重构来暴露它们固有的并行性。
● 优化。并行化完成后,需要通过优化来提高性能。优化可以应用于各个级别,从数据传输到计算到浮点操作序列的微调。分析工具对这一过程非常有用,可以建议开发人员优化工作的下一个策略。
● 部署。将结果与原始期望进行比较。回想一下,初始评估步骤允许开发人员通过加速给定热点来确定潜在加速的上界。
1. 评估应用
2. 异构化编程
● 主机与设备之间的差异
■ 线程资源。主机系统上的执行管道可以支持不超过核心数2倍的并行线程;CUDA设备上最小的可执行单元含32个线程(线程束)。
■ 线程。操作系统必须在CPU执行通道上进行缓慢的上下文切换来交换线程;GPU中多个线程排队工作(按线程束为单位),如果一个线程要进行等待,它就开始执行另一个线程。活动线程分配有独立的寄存器和其他资源,直到执行完为止,所以在GPU线程切换时不需要寄存器或其他状态的交换。总之,CPU内核设计以尽量减少在每个时间的一个或两个线程的延迟,而GPU被设计来处理大量的并发,以轻量级线程的吞吐量最大化。
■ 内存。主机系统和设备都有各自不同的附加物理内存。
● 考虑矩阵加法的计算 - 传输比为 1 : 3 = O(1),没有明显优势,而矩阵乘法为N3 : 3N2 = O(N),矩阵越大性能越好。
3. 流程剖析
● gprof 工具,命令行下使用,如 $ gprof ./a.out > profile.txt
● 强缩放 Amdahl's Law,S = 1 / ( ( 1 - P ) + P / N ) 。考虑相同问题规模下不同并行条件对计算优化的影响,通常程序只有较小的线性伸缩比,我们应该将精力集中在提高 P 上。
● 弱缩放 Gustafson's Law,S = N + ( 1 - P) (1 - N) = N P + ( 1 - P ) 。考虑相同并行条件下不同问题规模下对计算优化的影响。
● 针对不同的问题使用强缩放或者弱缩放来分析秉性可优化的上限。
4. 并行化
● Thrust 库,类似 C++STL,死在诸如扫描、排序、规约等计算。
● 使用 OpenACC 并行编译指令来优化。
5. 开始
● 若代码中相对独立的一部分花费时间较长时,将其重构为并行运算效果最好。
6. 得到正确答案
● 尽量将代码写成多个 __device__ 函数而不是一整个 __global__ 函数,使得每个设备函数都能独立进行测试,然后再组装到一起。
● CUDA 编译器会删除无效的内存访问操作,在调试时如果希望保留这些操作,则需要有相应的后续,例如进行输出。
● 使用 __host__ __device__ 函数,使得代码可以在主机和设备上都能进行测试和调用,减少代码重复。
● Debug工具。CUDA-GDB,Nsight,Allinea DDT,TotalView,CUDA-MEMCHECK。
● CUDA 浮点运算规则,NVIDIA-CUDA-Floating-Point.pdf。注意计算过程中的单、双精度转化,例如使用 float 格式时,所有数值常量都尽量加上 f 结尾,防止计算过程汇总先转化为双精度计算,又转化回单精度,造成计算误差和资源浪费。
● CUDA 遵循 IEEE 754 浮点运算标准。其中一个例外:融合乘加(FMA)指令,其结果往往与两个操作分开得到的结果略有不同。
7. 应用程序优化优化
8. 定量分析程序表现
● 可以使用 CPU 的计时工具来测量 CUDA 的运行时间,但应该配合使用函数 cudaDeviceSynchronize() 来进行,即在开始计时和结束计时前进行设备同步,保证所有设备上的操作已经全部完成。因为在设备上开始计算后,控制权交还CPU,继续执行主机代码,除非有设备阻塞操作,否则不能确认设备完成计算的时间。
● 其他同步函数不适合用于计时同步。例如 cudaStreamSynchronize() (阻塞特定的流,一个设备上可以有多个流)或 cudaEventSynchronize() (阻塞直到某一特定时间被 record() 到,不能保证该事件本身完成)
● 同步函数会使得 CUDA 计算速度下降,在正常运行时尽量少使用。
● CUDA event API 的计时工具,即 cudaEvent_t start, stop; 系列。
● 理论带宽 = 显存频率 × 显存通道数 × 位宽。注意:①显存频率 1 GHz = 1 × 109 Hz ≠ 230 Hz;②显存通道数和显存颗粒代数有关,如 GDDR3 是 2,GDDR5 是 4。
e.g. GTX1070 with GDDR5,显存频率 2002 MHz,位宽256 bits,理论带宽 = 2002 × 106 Hz × 4 × 256 bit / ( 8 bit / Byte ) = 238.66 Byte / s。
● 有效带宽 = ( 显存上行字节数 + 显存下行字节数 ) / 耗时。与实际程序有关。
● Visual Profiler 工具查看内存事务状况。
■ Requested Global Load Throughput,Requested Global Store Throughput 。内核请求的显存全局负载、存储吞吐量,用于有效带宽计算。反应计算效率高低。
■ Global Load Throughput,Global Store Throughput 。实际显存全局负载、存储吞吐量。由于内存事务合并,内核需要的实际吞吐量大于请求吞吐量。反应内核与硬件限制的关系。
■ DRAM Read Throughput,DRAM Write Throughput 。 内存读写量。
9. 存储优化
● 主机 - 设备数据转移。最小化数据转移量,设备合并内存访问,使用页锁定内存,异步内存拷贝。
● 串行拷贝执行(Sequential copy and execute)与分阶段拷贝执行(Staged concurrent copy and execute)。需要将一大块内存连续的写入显存时,前者一次性写入,后者将该内存划分为若干块,在不同的流中分块写入,在显存中自然拼合。在GPU含有多个拷贝引擎的情况下,后者效率明显提高。
1 // 串行 2 cudaMemcpy(d_data, h_data, N * sizeof(float), dir); 3 kernel <<< N / nThreads, nThreads >>> (d_data); 4 5 // 分阶段 6 for (int i = 0; i < nStream; i++) 7 { 8 offset = i * N / nStream; 9 cudaMemcpyAsync(d_data + offset, h_data + offset, size, dir, stream[i]); 10 kernel <<< N / (nThreads * nStream), nThread, 0, stream[i] >>> (a_d + offset); 11 }
设串行内存拷贝时间为 tT,执行时间 tE,则串行拷贝执行过程耗时 tT + tE;当 tT > tE 时分阶段拷贝执行耗时 ≈ tT + tE / nStream;当 tT < tE 时分阶段拷贝执行耗时 ≈ tE + tT / nStream 。
● 使用零拷贝内存,需要先 cudaSetDeviceFlags(cudaDeviceMapHost); 再调用 CUDA 其他函数,即在创建 GPU 上下文以前就设立好设备标志。
1 // cuda_runtime_api. 2 extern __host__ cudaError_t CUDARTAPI cudaSetDeviceFlags( unsigned int flags ); 3 // driver_types.h 4 #define cudaDeviceScheduleSpin 0x01 // Spin default scheduling 5 #define cudaDeviceScheduleYield 0x02 // Yield default scheduling 6 #define cudaDeviceScheduleBlockingSync 0x04 // Blocking synchronization 7 #define cudaDeviceBlockingSync 0x04 8 #define cudaDeviceScheduleMask 0x07 // flags mask 9 #define cudaDeviceMapHost 0x08 // Support mapped pinned allocations 10 #define cudaDeviceLmemResizeToMax 0x10 // Keep local memory allocation after launch 11 #define cudaDeviceMask 0x1f // flags mask
● CUDA计算能力2.0以后使用了统一虚拟寻址(Unified Virtual Adressing),使用 cudaHostAlloc(); 申请的内存不再需要用 cudaHostGetDevicePointer(); 来映射设备指针,直接将主机指针未喂给核函数即可。(未经测试)
● cudaHostalloc 和 cudaMallocHost 。可见后者被转化为了前者的接口函数,且使用默认标志 flag = 0 。
1 // cuda_runtime_api.h 2 extern __host__ cudaError_t CUDARTAPI cudaHostAlloc(void **pHost, size_t size, unsigned int flags); 3 // driver_types.h 4 #define cudaHostAllocDefault 0x00 // Default page-locked allocation 5 #define cudaHostAllocPortable 0x01 // Pinned memory accessible by all CUDA contexts 6 #define cudaHostAllocMapped 0x02 // Map allocation into device space 7 #define cudaHostAllocWriteCombined 0x04 // Write-combined memory 8 // cuda_runtime.h 9 template<class T> static __inline__ __host__ cudaError_t cudaMallocHost(T **ptr, size_t size, unsigned int flags = 0) 10 { 11 return cudaMallocHost((void**)(void*)ptr, size, flags); 12 } 13 14 static __inline__ __host__ cudaError_t cudaMallocHost(void **ptr, size_t size, unsigned int flags) 15 { 16 return ::cudaHostAlloc(ptr, size, flags); 17 } 18 19 template<class T> static __inline__ __host__ cudaError_t cudaHostAlloc(T **ptr, size_t size, unsigned int flags) 20 { 21 return ::cudaHostAlloc((void**)(void*)ptr, size, flags); 22 }
● 可以用 cudaHostRegister(); 将已经存在的可分页内存改成页锁定内存。
1 // cuda_runtime_api.h 2 extern __host__ cudaError_t CUDARTAPI cudaHostRegister(void *ptr, size_t size, unsigned int flags); 3 // driver_types.h 4 #define cudaHostRegisterDefault 0x00 // Default host memory registration flag 5 #define cudaHostRegisterPortable 0x01 // Pinned memory accessible by all CUDA contexts 6 #define cudaHostRegisterMapped 0x02 // Map registered memory into device space 7 #define cudaHostRegisterIoMemory 0x04 // Memory-mapped I/O space
四种不同的 flag:( 参考 http://blog.csdn.net/junparadox/article/details/50633641 )
■ cudaHostAllocPortable 和 cudaHostRegisterPortable 。该内存可被系统中的所有设备使用。
■ cudaHostAllocMapped 和 cudaHostRegisterMapped 。把锁页内存地址映射到设备地址空间,这块内存可以同时获得主机地址和设备地址(用 cudaHostGetDevicePointer() 取得)。使用主机和设备使用统一编址的时候不需要指针转换。
内核直接存取主机内存的优势:无需在设备上分配内存,也无需在主机内存和设备内存之间拷贝数据(均隐式进行);无须使用流就可以并发数据传输和内核执行,数据传输和内核执行自动并发执行。
■ 页锁定内存是主机和设备之间共享的,所以在使用cuda stream 或者cuda event 时必须对内存读写同步;避免潜在的写后读,读后写或者写后写等多线程同步问题。
■ 检查设备 canMapHostMemory 属性判断设备是否支持映射锁页主机内存(1 为支持,0 为不支持)。
■ 调用任何 cuda 运行时函数前就要调用 cudaSetDeviceFlags(),传入cudaDeviceMapHost 标签。否则,cudaHostGetDevicePointer() 将会返回错误。 如果设备不支持被映射分页锁定存储,函数 cudaHostGetDevicePointer() 会返回错误。
■ cudaHostAllocWriteCombined 和 cudaHostRegisterIoMemory 。读写结合存储不使用 L1 和 L2 缓存,所以程序的其它部分就有更多的缓存可用。此外,写结合内存通过PCI-E 传输数据时不会被监视(snoop),这能够获得高达40%的传输加速。 从主机读取写结合存储非常慢(因为没有使用L1、L2cache),所以写结合存储应当只用于那些主机只写的存储。
■ 使用映射锁页主机内存看,原子操作将不再保证原子性。cudaHostRegisterIoMemory 是cudaHostRegister() 特有的选项,可以把主机内存映射到IO 地址空间。
● 通过使用 cudaPointerGetAttributes() 来判断指针是主机指针还是设备指针。
1 // cuda_runtime_api.h 2 extern __host__ cudaError_t CUDARTAPI cudaPointerGetAttributes(struct cudaPointerAttributes *attributes, const void *ptr); 3 // driver_typrs.h 4 struct __device_builtin__ cudaPointerAttributes 5 { 6 enum cudaMemoryType memoryType;// 指针指向的内存种类,主机 / 设备 7 int device; // 设备编号 8 void *devicePointer; // 设备指针值 9 void *hostPointer; // 主机指针值 10 int isManaged; // 知否指向管理内存 11 }; 12 // driver_types.h 13 enum __device_builtin__ cudaMemoryType 14 { 15 cudaMemoryTypeHost = 1, // 主机内存 16 cudaMemoryTypeDevice = 2 // 设备内存 17 };
例如,当 float *dev_a 和 float *host_a 分别为为设备指针和主机指针时:
1 struct cudaPointerAttributes attr_dev_a; 2 cudaPointerGetAttributes(&attr_dev_a, dev_a); 3 struct cudaPointerAttributes attr_host_a; 4 cudaPointerGetAttributes(&attr_host_a, host_a); 5 6 attr_dev_a.memoryType == 1; 7 attr_dev_a.device == 0; 8 attr_dev_a.devicePointer == 0x0000000204800000; 9 attr_dev_a.hostPointer == 0x000002662f5b0000; 10 attr_dev_a.isManaged == 0; 11 12 attr_host_a.memoryType == 0; 13 attr_host_a.device == -1; // 主机设备号 -1 14 attr_host_a.devicePointer == 0x0000000000000000;// 获取不到相关信息 15 attr_host_a.hostPointer == 0x0000000000000000; 16 attr_host_a.isManaged == 0;
● 各种内存的读取和缓存特性
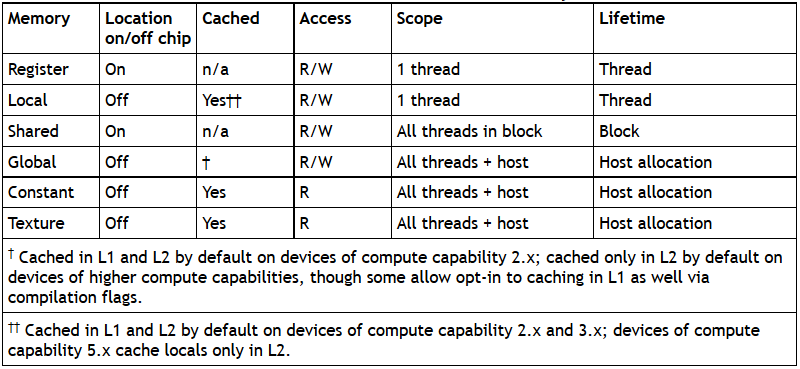
注意 local memory 是非芯片的,所以访问局部内存和访问全局内存一样费时。局部内存只是用来保存自动变量的,若自动变量大小不超过寄存器能容纳的空间,则可以缓存;超出了寄存器能容纳的空间,编译器会将自动变量放到局部内存中,动态地进行索引。
纹理内存和常量内存是可缓存的,所以一次访问只花费一个缓存读取的时间,除非缓存未命中,这时需要花费一个设备内存读取的时间。
● 合并内存访问,有几个要点。
■ L1 缓存量 128 byte ,可容纳一个线程束(32 条线程)数量的整形或浮点数值(每个 4 byte);L2 缓存量 32 Byte。
■ 一次访问内存的地址起点按其尺寸对齐,即只能从内存中数组起点的第 0、128、256……位置进行访问。
■ cudaMalloc() 保证申请到的数组内存按照 256 byte 对齐。
■ 在内存访问的时候,可能发生的情况如下图,后两种情况访问效率较低,降低了有效带宽。特别地,当线程束访问不能利用其邻居线程束的访问结果(空间)或是上一次访问结果(时间)时,效率下降更为明显。
(1) 简单合并内存访问。访问地址起点为 128 * k 的形式,且访问大小不超过L1缓存量,这时一次 L1 缓存即可完成任务。

(2) 串列化但非对齐的访问。访问地址起点不满足 128 * k 的形式,访问大小不超过L1缓存量,这时需要用两次 L1 缓存来访问。

(3) 过大尺寸的内存访问。访问大小超过了 L1 缓存量,这时只能使用多个 L2 缓存来进行访问。

■ 当存在跨步内存访问时,有效带宽和跨步长度成反比。这是由于一次连续内存访问得到的数据中,有效数据量与跨步成反比。
● 共享内存相关。共享内存被分为若干个等大的模块,称为 bank。对 n 个不同地址的 bank 上的数据进行读写可以同时进行,表现为有效带宽变成原来的 n 倍。多个线程要读取同一个 bank 时可以利用线程广播来并行化,但是多个线程同时写入同一个 bank 时依然是串行的。
● (?) Each bank has a bandwidth of 64 bits every clock cycle. There are two different banking modes: either successive 32-bit words (in 32-bit mode) or successive 64-bit words (64-bit mode) are assigned to successive banks. The warp size is 32 threads and the number of banks is also 32, so bank conflicts can occur between any threads in the warp.
● 优化矩阵乘法 C = A × B 和 C = A × AT 的案例(重写)。
● (?) Inspection of the PTX assembly code (obtained by compiling with -ptx or -keep command-line options to nvcc) reveals whether a variable has been placed in local memory during the first compilation phases. If it has, it will be declared using the .local mnemonic and accessed using the ld.local and st.local mnemonics. If it has not, subsequent compilation phases might still decide otherwise, if they find the variable consumes too much register space for the targeted architecture. There is no way to check this for a specific variable, but the compiler reports total local memory usage per kernel (lmem) when run with the --ptxas-options=-v option.
● 纹理内存可以绑定到全局内存上,并且核函数可以对该部分的全局内存进行写入操作,但是由于纹理内存是缓存的,其内容不会随全局内存的写入而发生变化。在同一个核函数中先写入一段全局内存,再读取绑定了同一段地址的纹理内存,结果是未定义的,应该避免这种操作,可以先退出该核函数,再重新启动另一个核函数进行相关纹理运算。
(? 调整了顺序,本来应该在那张表的下面) Texture references that are bound to CUDA arrays can be written to via surface-write operations by binding a surface to the same underlying CUDA array storage).
(?)函数 tex1D(); tex2D(); tex3D(); 相较于 tex1Dfetch(); tex2Dfetch(); tex3Dfetch(); 的新特性。
● 常量内存。一个线程束对常量内存访问时,访问不同地址之间是串行的,总的消耗时间与该线程束请求的地址数量成正比。也就是说,如果线程束内 32 个线程都访问常量内存中的同一个地址,则由于线程广播的作用,只需要 1 个单位的时间(可以转化为 1 次寄存器读取的速度);但若访问常量内存中 32 个不同的地址,则至少需要 32 个单位的时间。
● 寄存器变量不消耗指令调用以外的任何时钟周期,但在发生原子操作或者寄存器 bank 冲突的时候发生延迟。原子操作会造成 24 个时钟周期的延迟,但是会隐藏在 SM 上众多的线程中(1 个 SM 接受 24 个线程束)。编译器会优化寄存器 bank 冲突的问题,特别地,当每个 block 汇总线程的数量为 64 的倍数时没有 bank 冲突,效果最佳。
(?)将数据包装成 float4 或者 int4 类型不会对寄存器依赖造成影响。
● 设备内存申请 cudaMalloc(); 和释放 cudaFree(); 非常耗时,应该尽量少申请内存,并且尽可能重复利用。

