kudu 建表(使用impala操作kudu之创建kudu表)、azkaban 执行工作流和工作流下的节点(并发执行)、azkaban 查看job执行结果和详细运行日志、SQL cast() 函数
kudu 建表(使用impala操作kudu之创建kudu表)
依次启动HDFS、mysql、hive、kudu、impala
登录impala的shell控制端:
Impala-shell
1:使用该impala-shell命令启动Impala Shell 。默认情况下,impala-shell 尝试连接到localhost端口21000 上的Impala守护程序。要连接到其他主机,请使用该-i <host:port>选项。要自动连接到特定的Impala数据库,请使用该-d <database>选项。例如,如果您的所有Kudu表都位于数据库中的Impala中impala_kudu,则-d impala_kudu可以使用此数据库。
2:要退出Impala Shell,请使用以下命令: quit;
使用Impala创建新的Kudu表时,可以将该表创建为内部表或外部表。
内部表
内部表由Impala管理,当您从Impala中删除时,数据和表确实被删除。当您使用Impala创建新表时,它通常是内部表。
使用impala创建内部表:
CREATE TABLE my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'hadoop01:7051,hadoop02:7051,hadoop03:7051',
'kudu.table_name' = 'my_first_table'
);
在 CREATE TABLE 语句中,必须首先列出构成主键的列。
此时创建的表是内部表,从impala删除表的时候,在底层存储的kudu也会删除表
drop table if exists my_first_table;
使用 CREATE TABLE ... AS SELECT 语句查询 Impala 中的任何其他表或表来创建表
准备kudu表和数据,使用java创建kudu表以及插入数据:
创建kudu表:
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Schema;
import org.apache.kudu.Type;
import org.apache.kudu.client.CreateTableOptions;
import org.apache.kudu.client.KuduClient;
import org.apache.kudu.client.KuduException;
import java.util.LinkedList;
import java.util.List;
public class CreateTable {
private static ColumnSchema newColumn(String name, Type type, boolean iskey) {
ColumnSchema.ColumnSchemaBuilder column = new ColumnSchema.ColumnSchemaBuilder(name, type);
column.key(iskey);
return column.build();
}
public static void main(String[] args) throws KuduException {
// master地址
final String masteraddr = "hadoop01,hadoop02,hadoop03";
// 创建kudu的数据库链接
KuduClient client = new KuduClient.KuduClientBuilder(masteraddr).defaultSocketReadTimeoutMs(6000).build();
// 设置表的schema
List<ColumnSchema> columns = new LinkedList<ColumnSchema>();
columns.add(newColumn("CompanyId", Type.INT32, true));
columns.add(newColumn("WorkId", Type.INT32, false));
columns.add(newColumn("Name", Type.STRING, false));
columns.add(newColumn("Gender", Type.STRING, false));
columns.add(newColumn("Photo", Type.STRING, false));
Schema schema = new Schema(columns);
//创建表时提供的所有选项
CreateTableOptions options = new CreateTableOptions();
// 设置表的replica备份和分区规则
List<String> parcols = new LinkedList<String>();
parcols.add("CompanyId");
//设置表的备份数
options.setNumReplicas(1);
//设置range分区
options.setRangePartitionColumns(parcols);
//设置hash分区和数量
options.addHashPartitions(parcols, 3);
try {
client.createTable("PERSON", schema, options);
} catch (KuduException e) {
e.printStackTrace();
}
client.close();
}
}
插入数据到kudu:
import org.apache.kudu.client.*;
import org.apache.kudu.client.SessionConfiguration.FlushMode;
public class InsertRow {
public static void main(String[] args) throws KuduException {
// master地址
final String masteraddr = "hadoop01,hadoop02,hadoop03";
// 创建kudu的数据库链接
KuduClient client = new KuduClient.KuduClientBuilder(masteraddr).build();
// 打开表
KuduTable table = client.openTable("PERSON");
// 创建写session,kudu必须通过session写入
KuduSession session = client.newSession();
// 采取Flush方式 手动刷新
session.setFlushMode(FlushMode.MANUAL_FLUSH);
session.setMutationBufferSpace(3000);
for (int i = 1; i < 10; i++) {
Insert insert = table.newInsert();
// 设置字段内容
insert.getRow().addInt("CompanyId", i);
insert.getRow().addInt("WorkId", i);
insert.getRow().addString("Name", "lisi" + i);
insert.getRow().addString("Gender", "male");
insert.getRow().addString("Photo", "person" + i);
session.flush();
session.apply(insert);
}
session.close();
client.close();
}
}
将kudu中的表映射到impala中:
CREATE EXTERNAL TABLE kudu_PERSON
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'hadoop01:7051,hadoop02:7051,hadoop03:7051',
'kudu.table_name' = 'PERSON'
);
使用CREATE TABLE ... AS SELECT 创建新表
CREATE TABLE new_table
PRIMARY KEY (companyid)
PARTITION BY HASH(companyid) PARTITIONS 8
STORED AS KUDU
AS SELECT companyid, workid, name ,gender,photo FROM kudu_PERSON;
结果:
[angel1:21000] > CREATE TABLE new_table
> PRIMARY KEY (companyid)
> PARTITION BY HASH(companyid) PARTITIONS 8
> STORED AS KUDU
> AS SELECT companyid, workid, name ,gender,photo FROM kudu_PERSON;
Query: create TABLE new_table
PRIMARY KEY (companyid)
PARTITION BY HASH(companyid) PARTITIONS 8
STORED AS KUDU
AS SELECT companyid, workid, name ,gender,photo FROM kudu_PERSON
+-------------------+
| summary |
+-------------------+
| Inserted 9 row(s) |
+-------------------+
Fetched 1 row(s) in 1.05s
外部表
外部表(创建者CREATE EXTERNAL TABLE)不受Impala管理,并且删除此表不会将表从其源位置(此处为Kudu)丢弃。相反,它只会去除Impala和Kudu之间的映射。这是Kudu提供的用于将现有表映射到Impala的语法。
使用java创建一个kudu表:
public class CreateTable {
private static ColumnSchema newColumn(String name, Type type, boolean iskey) {
ColumnSchema.ColumnSchemaBuilder column = new ColumnSchema.ColumnSchemaBuilder(name, type);
column.key(iskey);
return column.build();
}
public static void main(String[] args) throws KuduException {
// master地址
final String masteraddr = "hadoop01,hadoop02,hadoop03";
// 创建kudu的数据库链接
KuduClient client = new KuduClient.KuduClientBuilder(masteraddr).defaultSocketReadTimeoutMs(6000).build();
// 设置表的schema
List<ColumnSchema> columns = new LinkedList<ColumnSchema>();
columns.add(newColumn("CompanyId", Type.INT32, true));
columns.add(newColumn("WorkId", Type.INT32, false));
columns.add(newColumn("Name", Type.STRING, false));
columns.add(newColumn("Gender", Type.STRING, false));
columns.add(newColumn("Photo", Type.STRING, false));
Schema schema = new Schema(columns);
//创建表时提供的所有选项
CreateTableOptions options = new CreateTableOptions();
// 设置表的replica备份和分区规则
List<String> parcols = new LinkedList<String>();
parcols.add("CompanyId");
//设置表的备份数
options.setNumReplicas(1);
//设置range分区
options.setRangePartitionColumns(parcols);
//设置hash分区和数量
options.addHashPartitions(parcols, 3);
try {
client.createTable("PERSON", schema, options);
} catch (KuduException e) {
e.printStackTrace();
}
client.close();
}
}
使用impala创建外部表 , 将kudu的表映射到impala上:
CREATE EXTERNAL TABLE my_mapping_table
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'hadoop01:7051,hadoop02:7051,hadoop03:7051',
'kudu.table_name' = 'PERSON'
);
注意:
CREATE TABLE fin_dw.app_api_ent_bond_cash_dd (
sec_inner_code STRING NOT NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
cash_date TIMESTAMP NOT NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
ent_name STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
formatted_ent_name STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
ent_code STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
sec_code STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
sec_shortname STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
cash_vol DOUBLE NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
curr_term_repay_cap_tot_amt DOUBLE NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
curr_term_pay_tot_amt DOUBLE NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
cal_int_start_date TIMESTAMP NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
cal_int_end_date TIMESTAMP NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
bond_name STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
issue_date TIMESTAMP NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
issue_vol DOUBLE NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
face_int_rate DOUBLE NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
cal_int_mthd STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
pay_int_mthd STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
dw_ins_date TIMESTAMP NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
data_status STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
cash_year STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION,
bond_compre_code STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION, -- 新增
pay_each_100_cap_int STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION, -- 新增
pay_each_100_cap STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION, -- 新增
pay_each_100_int_tax STRING NULL ENCODING AUTO_ENCODING COMPRESSION DEFAULT_COMPRESSION, -- 新增
PRIMARY KEY (sec_inner_code, cash_date)
)
COMMENT '债券兑付kudu全量表'
STORED AS KUDU
TBLPROPERTIES ('kudu.master_addresses'='cloudera12,cloudera13,cloudera14');
-- kudu 表
-- 主键必须在首行且非空
-- 主键只能在表创建时指定。主键值不支持修改。
--('kudu.master_addresses'='cloudera12,cloudera13,cloudera14'); 生产环境才有,测试环境要去掉
主键只能在表创建时指定。主键值不支持修改。
不支持二级索引。
支持hash和partition分区,但只针对主键字段。

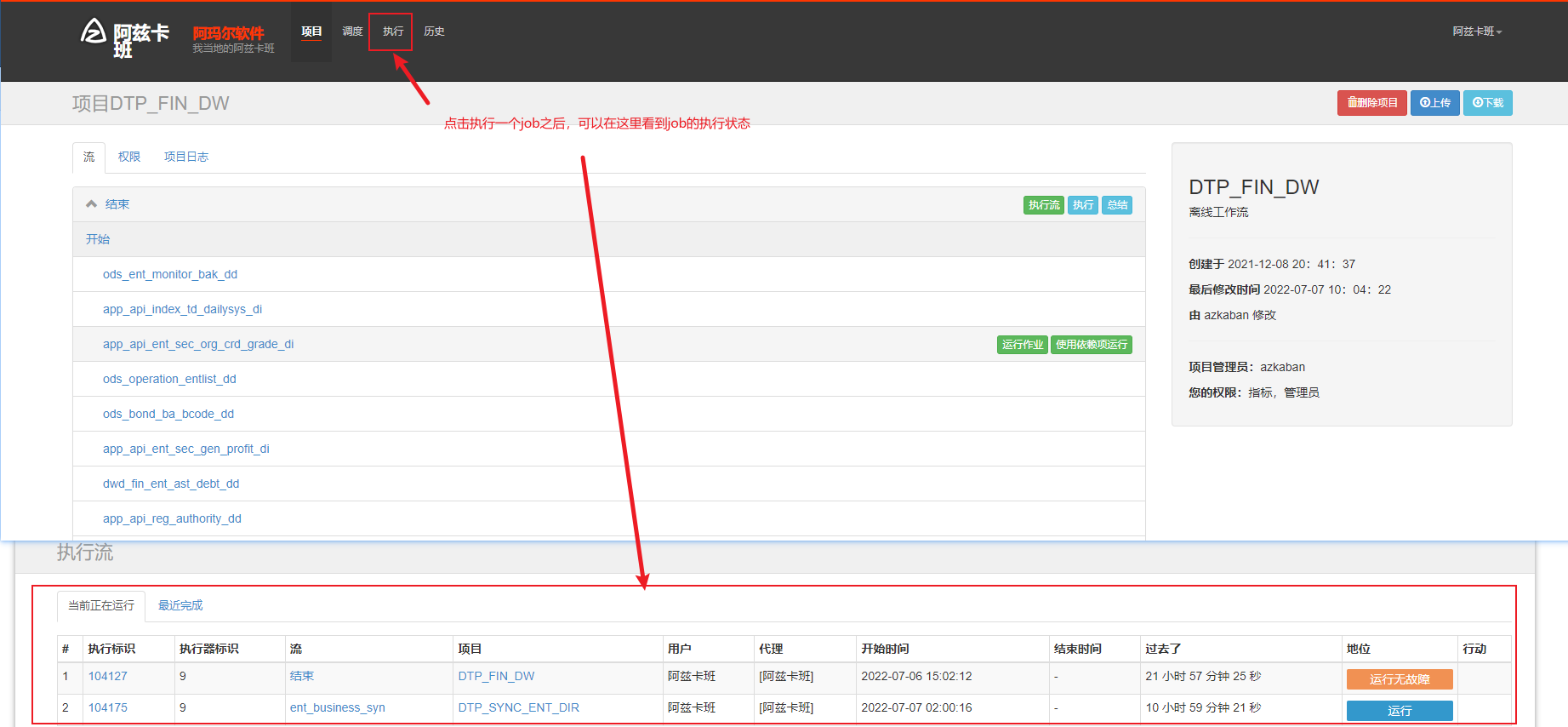
azkaban 执行工作流和工作流下的节点(并发执行)
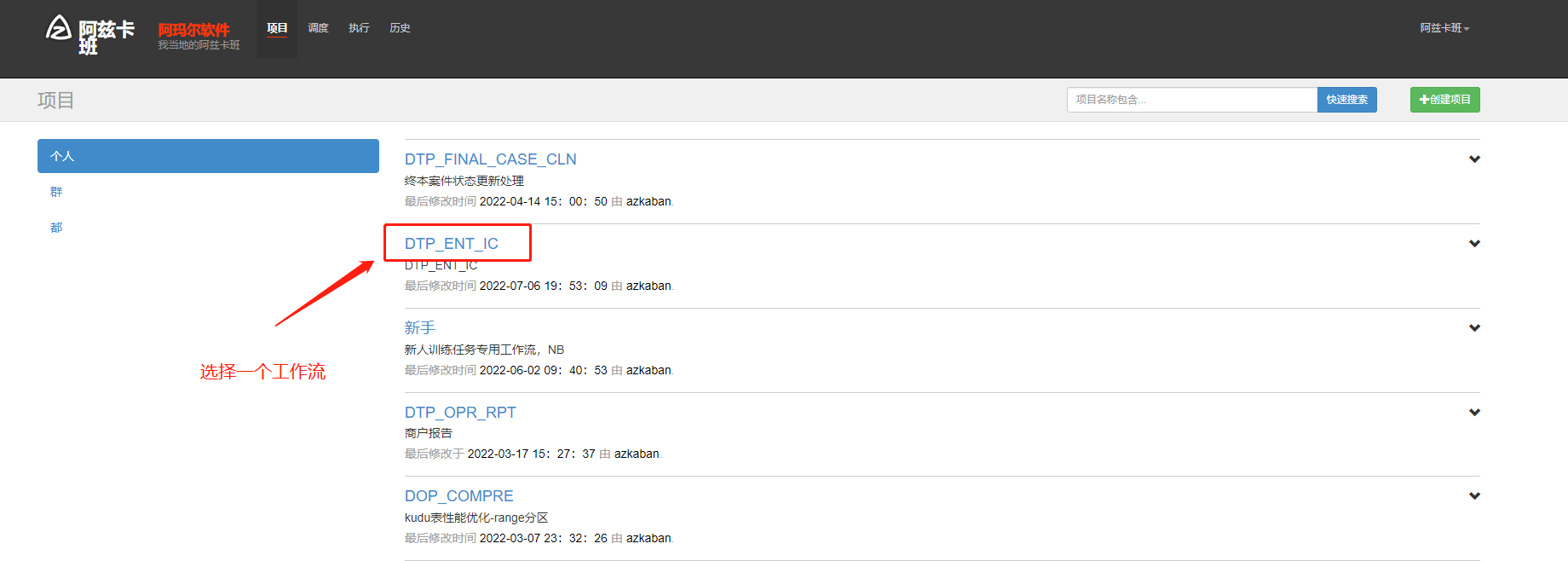
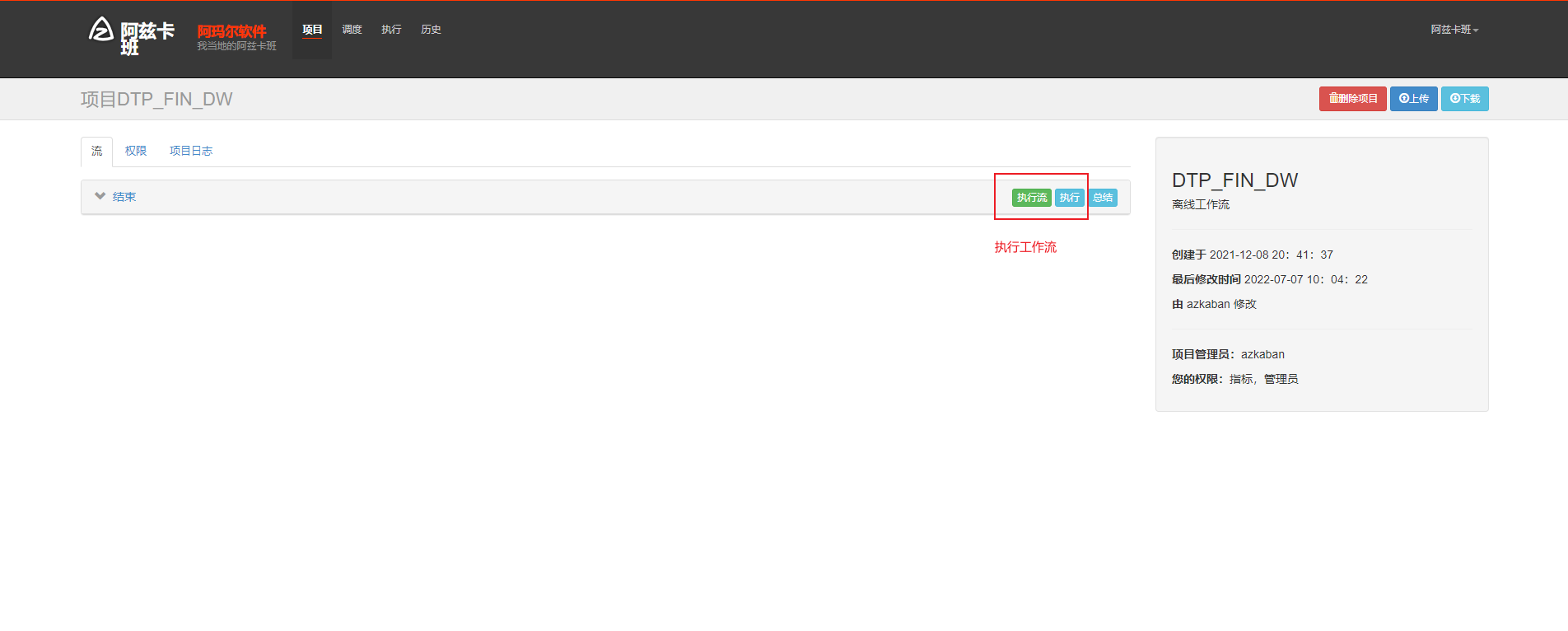
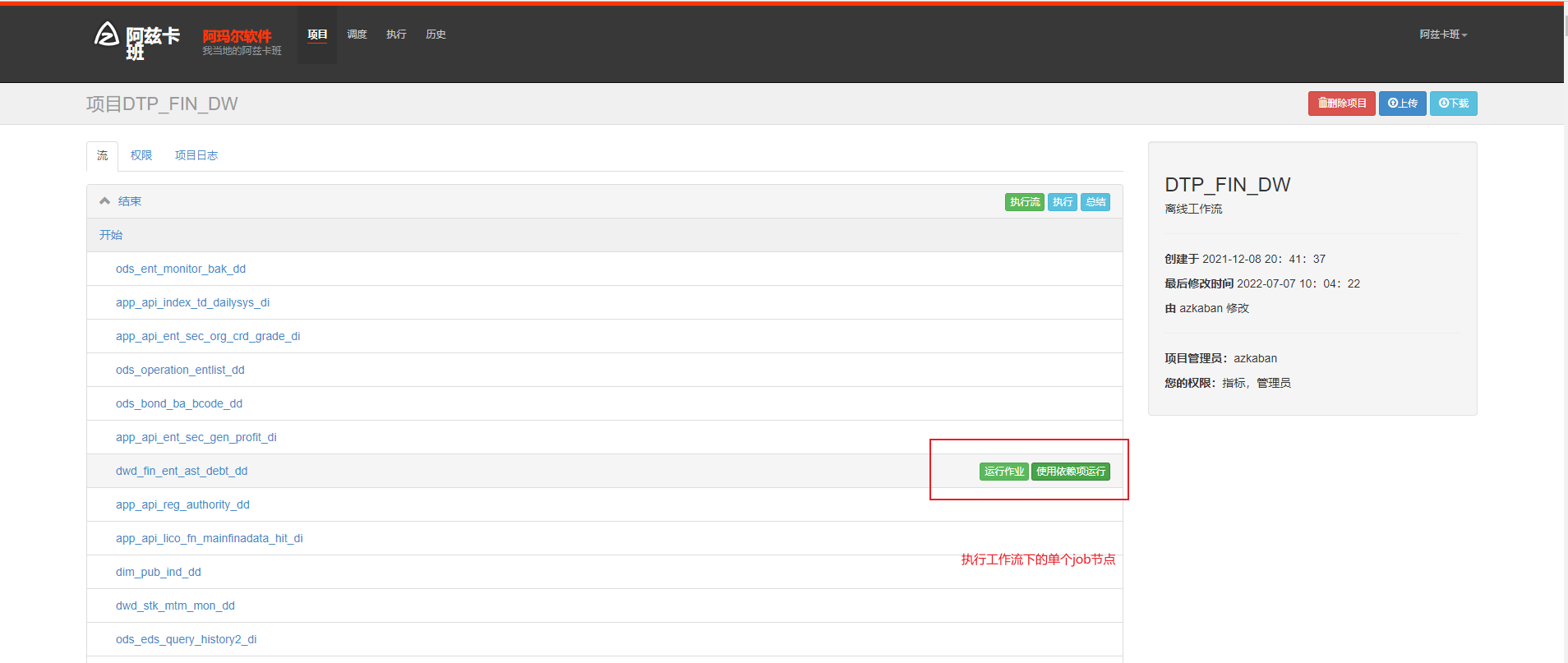


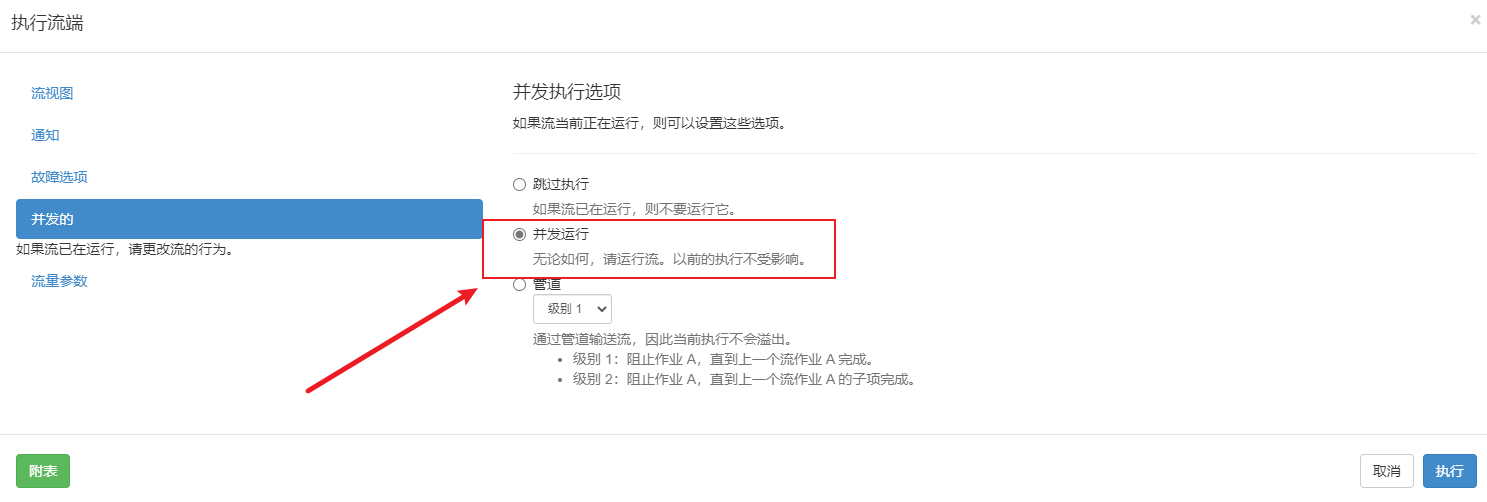
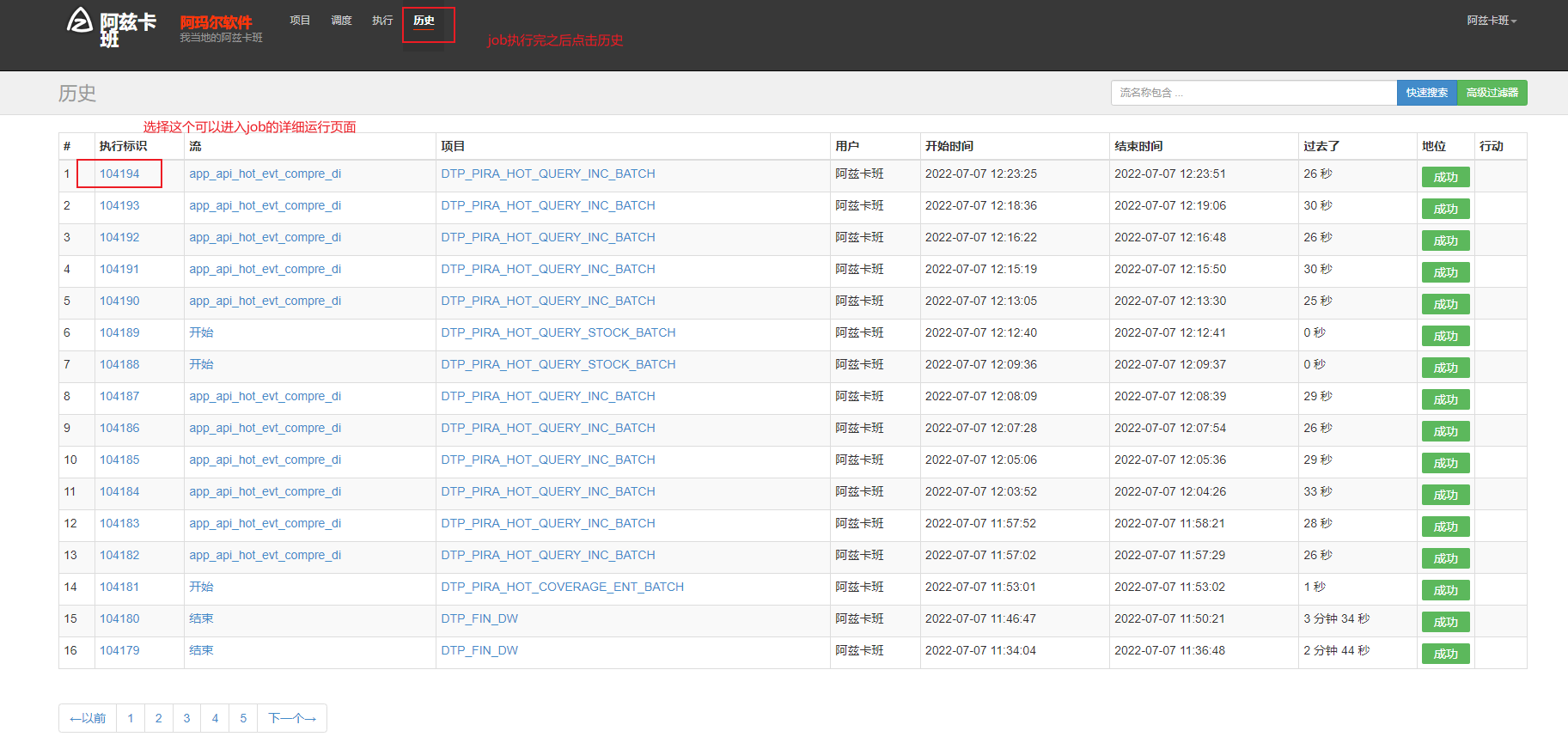
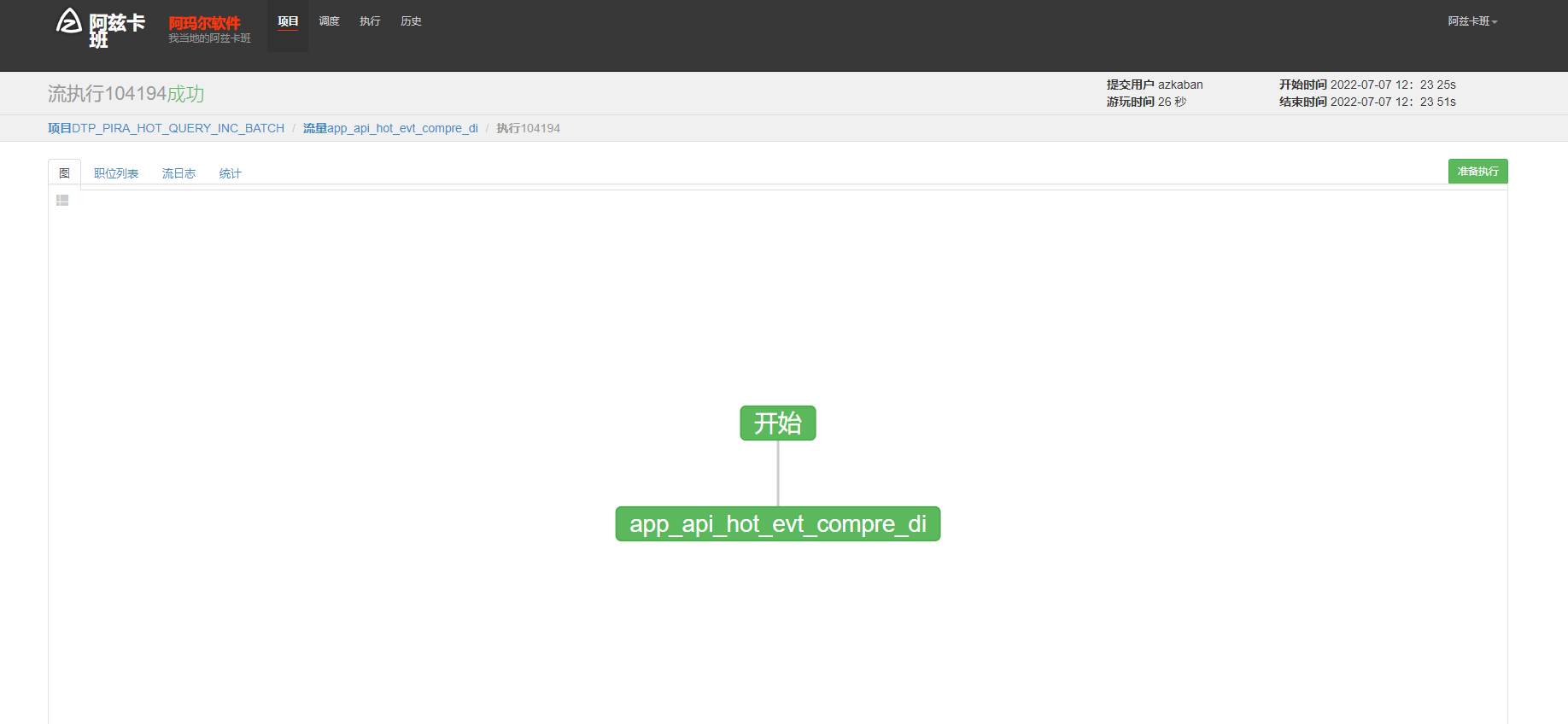
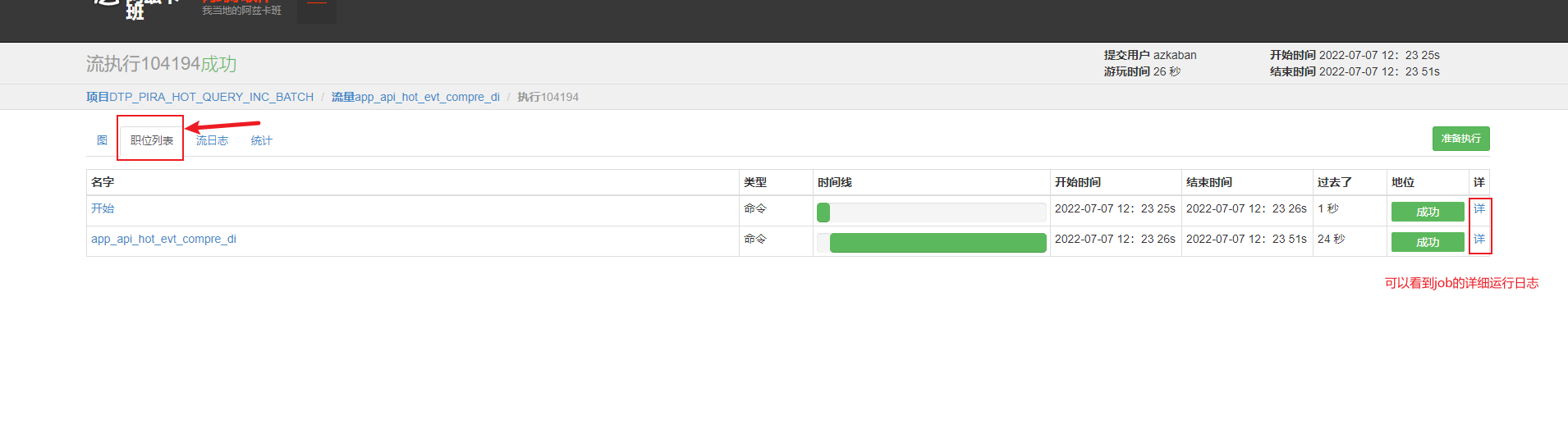
azkaban 查看job执行结果和详细运行日志
SQL cast() 函数
CAST函数用于将某种数据类型的表达式显式转换为另一种数据类型。CAST()函数的参数是一个表达式,它包括用AS关键字分隔的源值和目标数据类型。
语法:CAST (expression AS data_type)
expression:任何有效的SQServer表达式。
AS:用于分隔两个参数,在AS之前的是要处理的数据,在AS之后是要转换的数据类型。
data_type:目标系统所提供的数据类型,包括bigint和sql_variant,不能使用用户定义的数据类型。
可以转换的类型是有限制的。这个类型可以是以下值其中的一个:
- 二进制,同带binary前缀的效果 : BINARY
- 字符型,可带参数 : CHAR()
- 日期 : DATE
- 时间: TIME
- 日期时间型 : DATETIME
- 浮点数 : DECIMAL
- 整数 : SIGNED
- 无符号整数 : UNSIGNED

 浙公网安备 33010602011771号
浙公网安备 33010602011771号