
Kafka 集群架构图、通过 java(Scala) 来读写 Kafka
Kafka 集群架构图
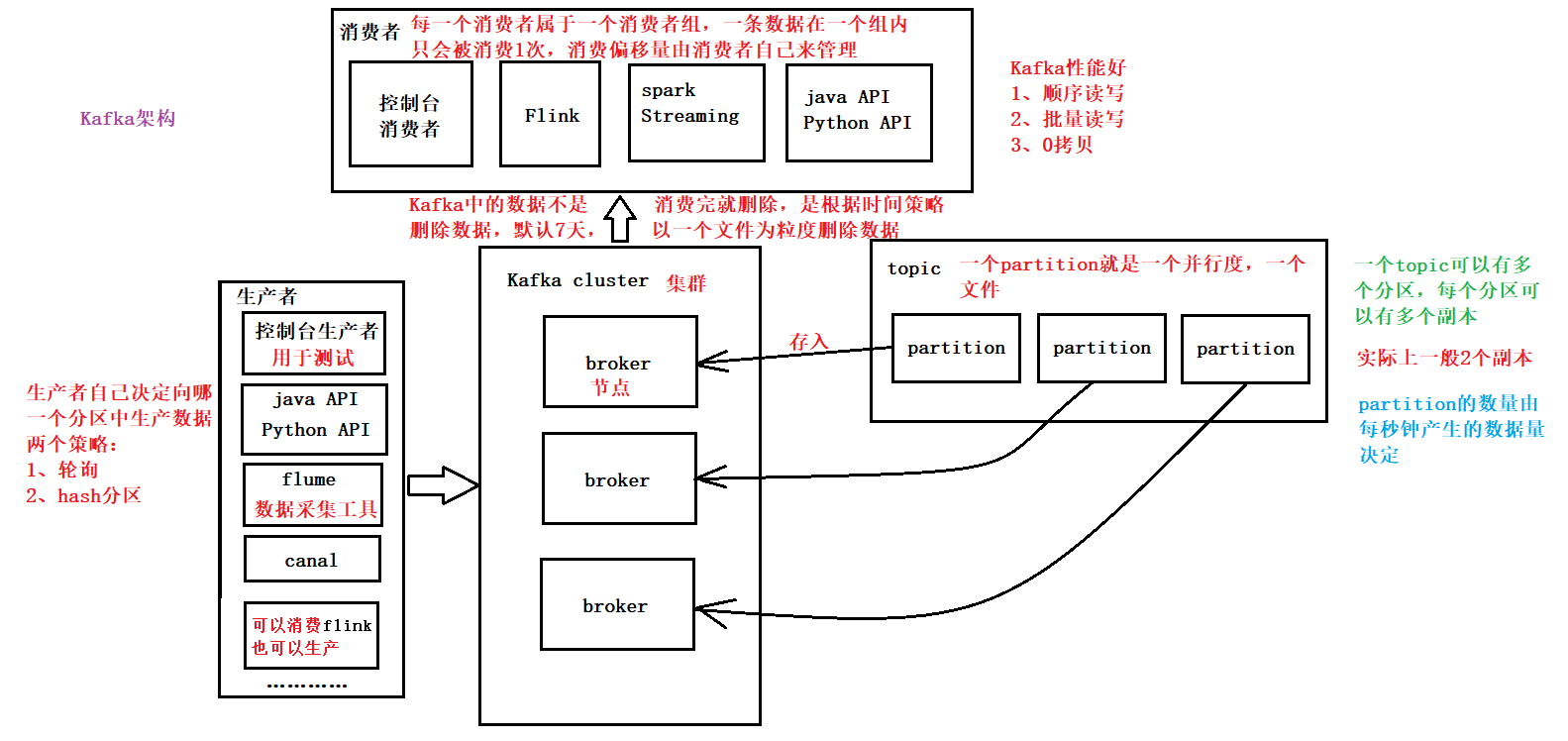
通过 java(Scala) 来读写 Kafka
导入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>1.0.0</version>
</dependency>
生产数据
Kafka 中存的数据是 K-V 格式的,只是 K 我们一般不用
package com.shujia.kafka
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
object Demo1KakfaProducer {
def main(args: Array[String]): Unit = {
/**
* 1、创建生产者
*
*/
val properties = new Properties()
//1、kafka broker(节点)列表
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092")
//2、指定kv的序列化类
//因为 KV 要在网络中传输
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//创建生产者
//指定 K-V 的类型
//properties -- 配置文件对象
val kafkaProducer = new KafkaProducer[String, String](properties)
/**
* 2、向kafka中生产数据
*
*/
//构建一行数据
//指定 K-V 的类型
//words -- topic
//java -- value
val record = new ProducerRecord[String, String]("words", "java")
//发送数据到kafka
kafkaProducer.send(record)
//手动将数据刷到kafka
//不手动flush的话,他会自动刷,但不是实时的
kafkaProducer.flush()
//关闭链接
kafkaProducer.close()
}
}
批量生产数据
package com.shujia.kafka
import java.util.Properties
import com.alibaba.fastjson.JSON
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import scala.io.Source
object Demo2StudentTokafka {
def main(args: Array[String]): Unit = {
/**
* 1、创建生产者
*
*/
val properties = new Properties()
//1、kafka broker列表
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092")
//2、指定kv的序列化类
properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
val kafkaProducer = new KafkaProducer[String, String](properties)
/**
* 读取本地文件
*
*/
//Scala IO
val studentList: List[String] = Source.fromFile("data/students.json").getLines().toList
//在Linux的shell中创建topic
//模拟多分区情况 -- 向student3中生产数据
//kafka-topics.sh --create --zookeeper master:2181,node1:2181,node2:2181 --replication-factor 2 --partitions 3 --topic student3
//循环将数据写入kafka
for (student <- studentList) {
/**
* 将同一个班级的数据写入到同一个分区中
* 共有3个分区
*/
//拿到班级 -- 解析json
val clazz: String = JSON.parseObject(student).getString("clazz")
//对班级进行 hash 分区, kafka生产者默认是轮询
val partition: Int = Math.abs(clazz.hashCode % 3)
//一行数据
//模拟多分区情况 -- 自定义分区
//多分区情况下生产数据时如果没有指定分区 -- 默认是轮询(随机写)
//student3 -- topic
//partition -- 手动指定的分区
//null -- key(不指定key)
//student -- value
val record = new ProducerRecord[String, String]("student3", partition, null, student)
//将数据发送到kafka
kafkaProducer.send(record)
//刷新
kafkaProducer.flush()
}
//关闭链接
kafkaProducer.close()
}
}
消费者
package com.shujia.kafka
import java.{lang, util}
import java.util.Properties
import org.apache.kafka.clients.consumer.{ConsumerRecord, ConsumerRecords, KafkaConsumer}
object Demo3Consumer {
def main(args: Array[String]): Unit = {
/**
* 创建消费者
*
*/
val properties = new Properties()
//1、kafka broker列表
properties.setProperty("bootstrap.servers", "master:9092,node1:9092,node2:9092")
//2、指定消费者组
//“group.id” 消费组 ID
properties.setProperty("group.id", "asdasdad")
//指定 key value 反序列化的类
//序列化类型需要和生产者中一致
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
/**
* earliest
* 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
* latest
* 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
* none
* topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
*
*/
//指定读取数据的位置
//从最早读取数据
properties.put("auto.offset.reset", "earliest")
//创建消费者
val consumer = new KafkaConsumer[String, String](properties)
/**
* 订阅topic
*
*/
val topics = new util.ArrayList[String]()
//存入一个需要被订阅的topic
topics.add("student3")
//需要传入一个集合对象
consumer.subscribe(topics)
/**
*
* 消费数据
*/
//加上循环模拟一直消费
//没有数据的时候,一秒拉取一次 -- 超时时间1秒
while (true) {
println("消费数据")
//从kafka中拉取数据,一次拉多条数据
//需要指定超时时间,1秒
val records: ConsumerRecords[String, String] = consumer.poll(1000)
//解析数据,获取指定topic的数据
//传入topic -- student3
val iterable: lang.Iterable[ConsumerRecord[String, String]] = records.records("student3")
//返回一个迭代器,并拿到迭代器对象
val iter: util.Iterator[ConsumerRecord[String, String]] = iterable.iterator()
while (iter.hasNext) {
//一行数据
val record: ConsumerRecord[String, String] = iter.next()
val key: String = record.key()
val topic: String = record.topic()
val partition: Int = record.partition()
val ts: Long = record.timestamp() //时间戳默认是有的,默认为当前系统时间
val value: String = record.value()
println(s"$key\t$topic\t$partition\t$ts\t$value")
}
}
}
}
