
Kafka 简介、非0拷贝和0拷贝、实时计算和离线计算的流程
Kafka 简介
实时计算的数据源
存储实时数据的工具
由Scala语言编写
去中心化架构
kafka是一个高吞吐的分布式消息系统
Apache kafka is publish-subscribe messaging rethought as a distributed commit log
Kafka是一个发布与订阅的分布式消息系统

实时计算和离线计算的流程
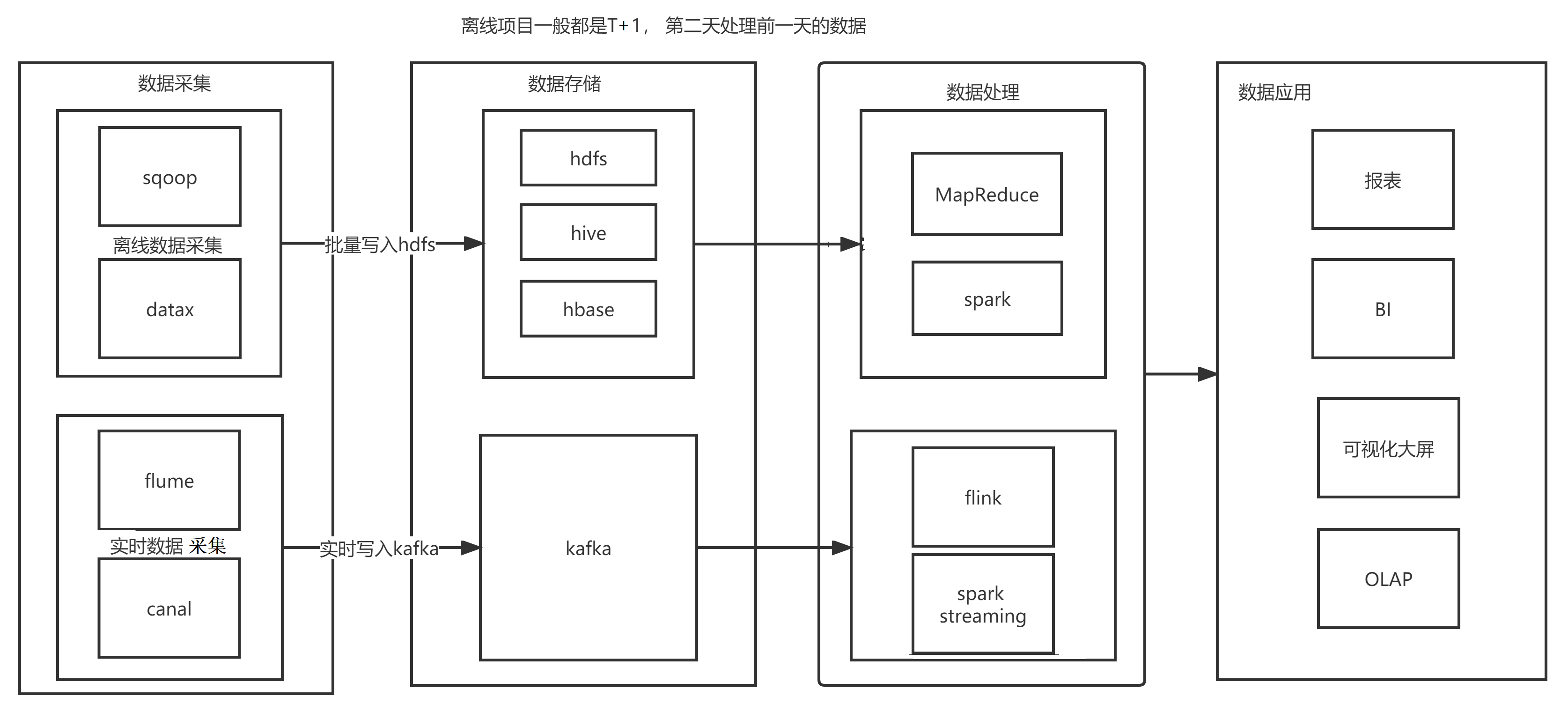
消息队列的应用场景
消息 -- 数据
系统之间解耦合
- queue模型
- publish-subscribe模型
峰值压力缓冲
异步通信
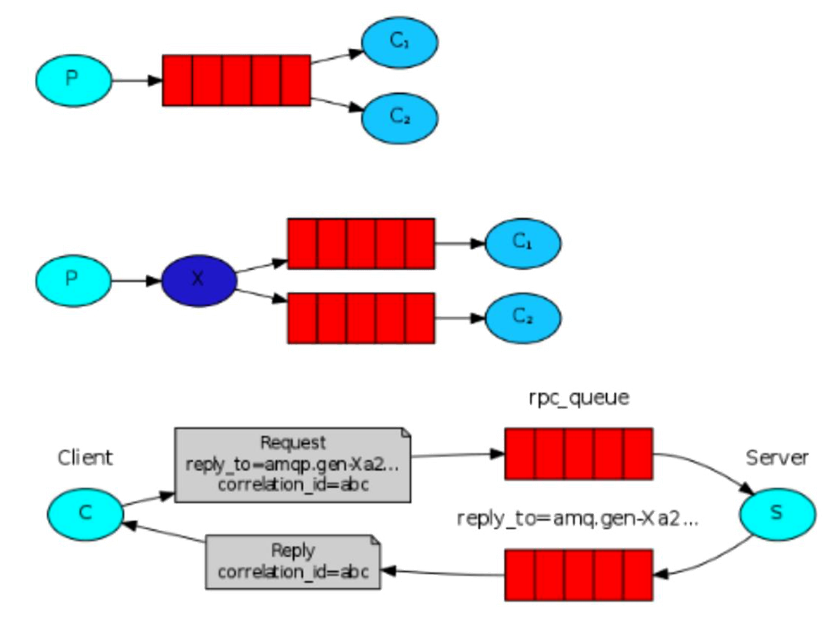
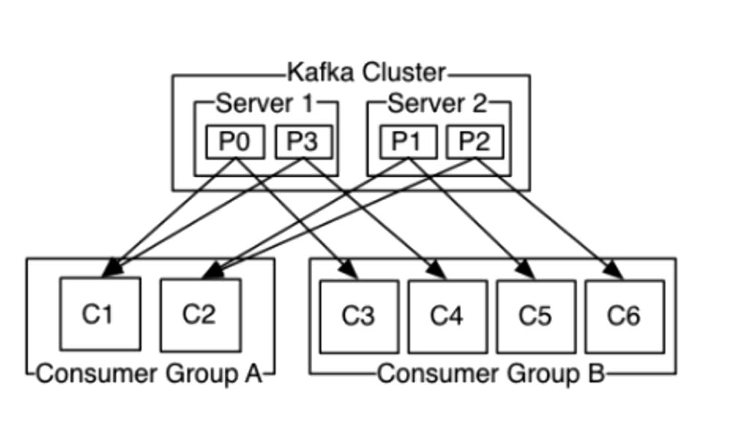
Kafka架构
producer:消息生存者
consumer:消息消费者
broker:kafka集群的server,负责处理消息读、写请求,存储消息
Kafka 的节点
topic:消息队列/分类
Queue里面有生产者消费者模型
broker就是代理,在kafka cluster这一层这里,其实里面是有很多个broker
topic就相当于queue
图里没有画其实还有zookeeper,这个架构里面有些元信息是存在zookeeper上面的,整个集群的管理也和zookeeper有很大的关系
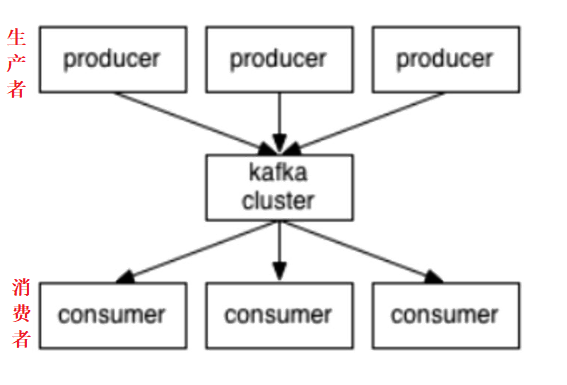
kafka的消息存储和生产消费模型
kafka 的数据也是存储在磁盘中的
一个topic分成多个partition
分出分区的目的是:为了实现分布式
在 topic 的角度上来说,数据并不是强有序的
每个partition内部消息强有序,其中的每个消息都有一个序号叫offset
强有序 -- 先进先出
offset -- 偏移量
一个partition只对应一个broker,一个broker可以管多个partition
这里的 partition 可以理解为 block 块
Kafka 中一个 topic 由多个 partition 组成,每一个 partition 对应到磁盘里是一个文件
消息不经过内存缓冲,直接写入文件
默认为7天删除
根据时间策略删除,而不是消费完就删除
producer自己决定往哪个partition写消息,可以是轮询的负载均衡,或者是基于hash的partition策略
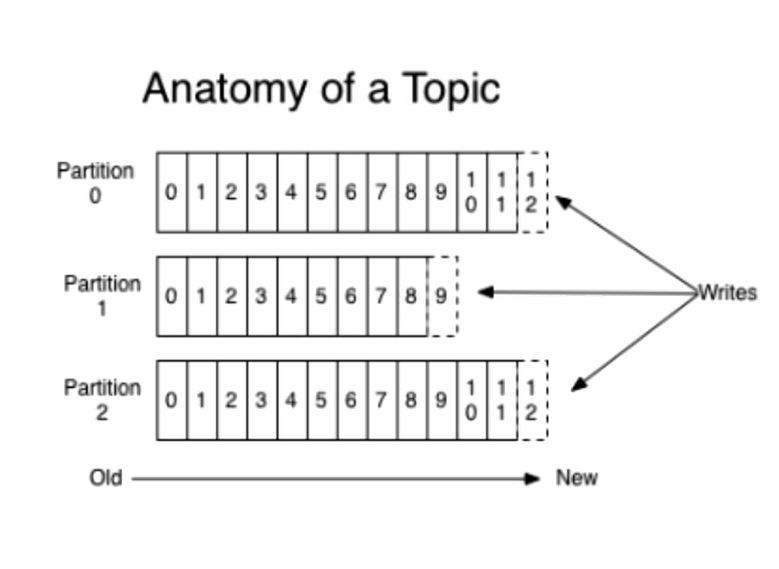
topic
kafka 里面的消息是有topic来组织的,简单的我们可以想象为一个队列,一个队列就是一个topic,然后它把每个 topic又 分为很多个partition,这个是为了做并行的,在每个 partition 里面是有序的,相当于有序的队列,其中每个消息都有个序号,比如0到12,从前面读往后面写
一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition
这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念,这个模型带来了很多个好处,这个我们后面再讨论一下
这里producer自己决定往哪个partition里面去写,这里有一些的策略,譬如如果hash就不用多个partition之间去join数据了
消费者和消费者组
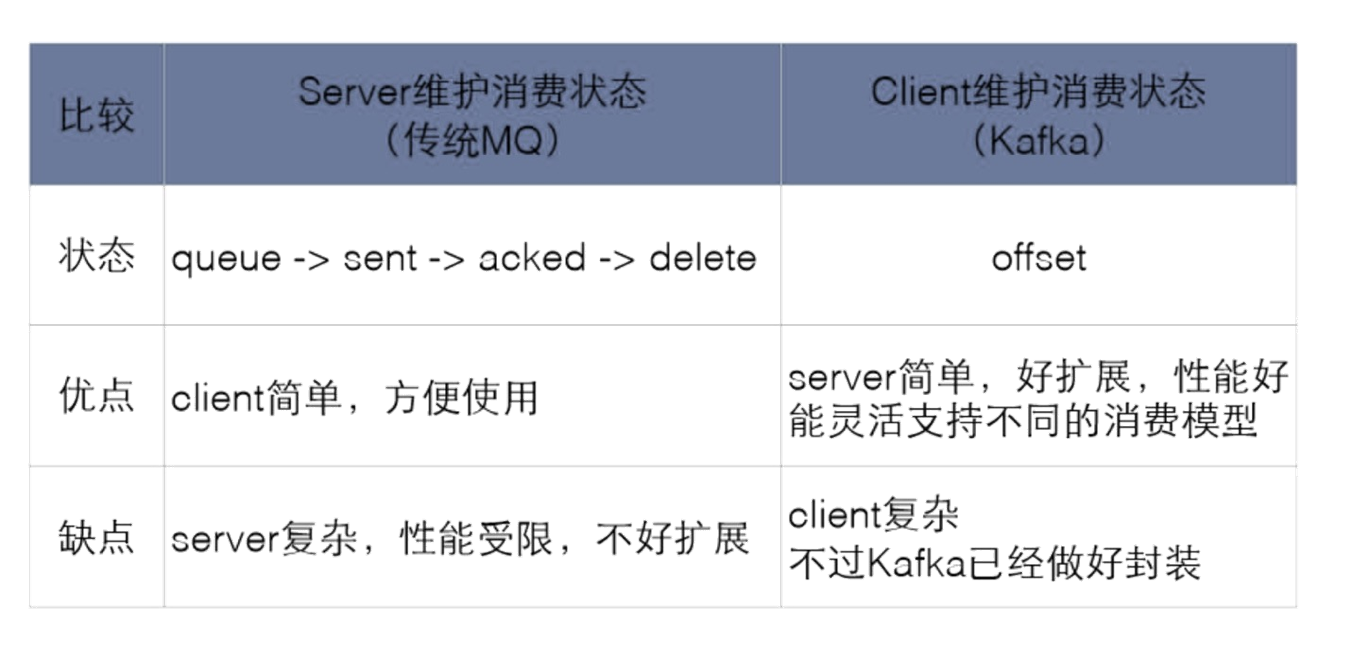
consumer自己维护消费到哪个offset
每个consumer都有对应的group
加入消费者组的概念是为了:并行消费,提高效率
group内是queue消费模型
-
各个consumer消费不同的partition
-
因此一个消息在group内只消费一次
group间是publish-subscribe消费模型
-
各个group各自独立消费,互不影响
-
因此一个消息在被每个group消费一次
kafka 的特点
消息系统的特点:生存者消费者模型,FIFO(先进先出)
FIFO(先进先出) -- 因为只在分区内强有序,所以想要实现FIFO,只有当Topic中只有一个分区的时候才可以实现
高性能:单节点支持上千个客户端,百MB/s吞吐
持久性:消息直接持久化在普通磁盘上且性能好
分布式:数据副本冗余、流量负载均衡、可扩展
很灵活:消息长时间持久化+Client维护消费状态
消息系统基本的特点是保证了,有基本的生产者消费者模型,partition内部是FIFO的,partition之间呢不是FIFO的,当然我们可以把topic设为一个partition,这样就是严格的FIFO
直接写到磁盘里面去,就是直接append到磁盘里面去,这样的好处是直接持久话,数据不会丢,第二个好处是顺序写,然后消费数据也是顺序的读,所以持久化的同时还能保证顺序,比较好,因为磁盘顺序读比较好
分布式,数据副本,也就是同一份数据可以到不同的broker上面去,也就是当一份数据,磁盘坏掉的时候,数据不会丢失,比如3个副本,就是在3个机器磁盘都坏掉的情况下数据才会丢,在大量使用情况下看这样是非常好的,负载均衡,可扩展,在线扩展,不需要停服务的
消费方式非常灵活,第一原因是消息持久化时间跨度比较长,一天或者一星期等,第二消费状态自己维护消费到哪个地方了,Queue的模型,发布订阅(广播)的模型,还有回滚的模型
kafka与其他消息队列对比

消费状态谁来维护Client vs.Server
kafka的消息存储
顺序读写磁盘
0拷贝
批量读写
有人可能会说kafka写磁盘,会不会是瓶颈,其实不会而且是非常好的,为什么是非常好的,因为kafka写磁盘是顺序的,所以不断的往前产生,不断的往后写,kafka还用了sendFile的0拷贝技术,提高速度,而且还用到了批量读写,一批批往里写,64K为单位,100K为单位,每一次网络传输量不会特别小,RTT(RTT:Round-TripTime往返时间)的开销就会微不足道,对文件的操作不会是很小的IO,也不会是比较大块的IO
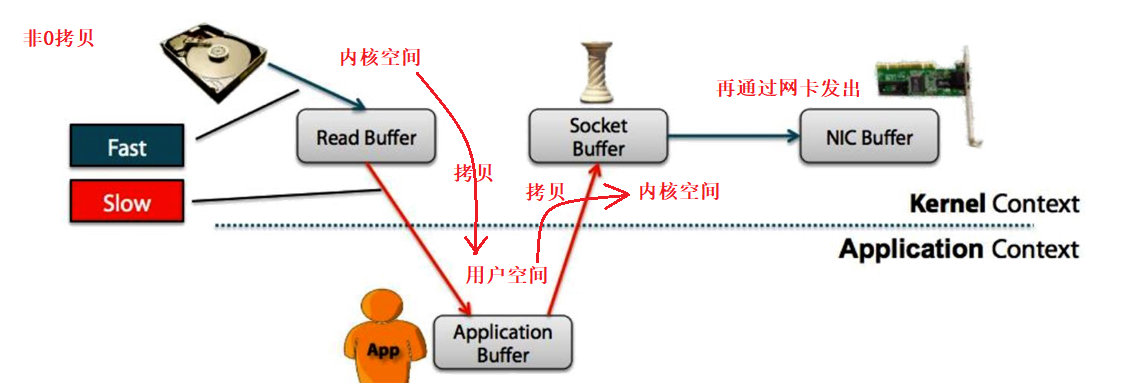
非0拷贝和0拷贝
用户空间 -- 代码
内核空间 -- 系统
从WIKI的定义中,我们看到“零拷贝”是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式。
Non-Zero Copy方式:
Zero Copy方式:
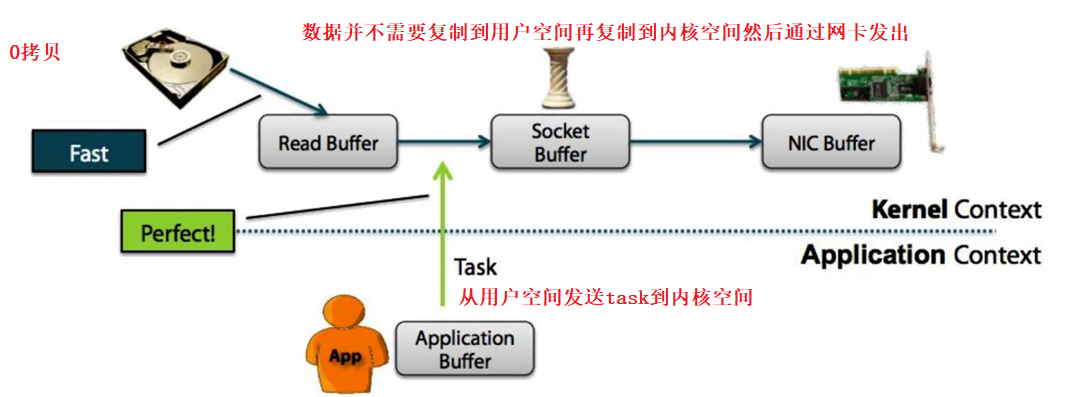
从上图中可以清楚的看到,Zero Copy的模式中,避免了数据在用户空间和内存空间之间的拷贝,从而提高了系统的整体性能。Linux中的sendfile()以及Java NIO中的FileChannel.transferTo()方法都实现了零拷贝的功能,而在Netty中也通过在FileRegion中包装了NIO的FileChannel.transferTo()方法实现了零拷贝。

