
Flink 窗口、Scala泛型通配符、Flink 窗口的底层 API、解析 json 格式的数据
目录
Flink 窗口
1、Time Window
时间窗口
2、Session Window
会话窗口
如果一段时间没有数据生成一个窗口
3、Count Window
统计窗口
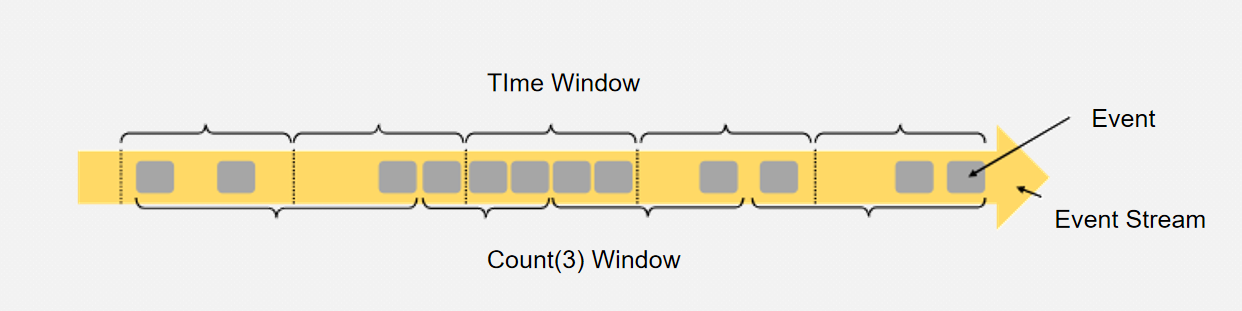
窗口的使用需要先分组,因为需要针对某一个key去划分窗口
Time Window
窗口的使用需要先 keyBy ,再去划分窗口
package com.shujia.flink.window
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{SlidingProcessingTimeWindows, TumblingEventTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object Demo1TimeWindow {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val kvDS: DataStream[(String, Int)] = linesDS.flatMap(_.split(",")).map((_, 1))
/**
* TumblingProcessingTimeWindows : 滚动(两个窗口没有交叉)的处理时间窗口
* TumblingEventTimeWindows : 滚动的事件时间窗口,需要设置时间字段和水位线
* SlidingProcessingTimeWindows : 滑动的处理时间窗口,滑动窗口需要指定窗口大小和滑动时间
* SlidingEventTimeWindows : 滑动的事件时间窗口,需要设置时间字段和水位线
*/
kvDS
//窗口的使用需要先 keyBy ,再去划分窗口
.keyBy(_._1)
//需要传入一个时间的是滚动窗口,需要传入两个时间的是滑动窗口
//.timeWindow(Time.seconds(5)) //处理时间的滚动窗口 -- 这样写是简写
//完整写法:
.window(SlidingProcessingTimeWindows.of(Time.seconds(15), Time.seconds(5)))
.sum(1)
.print()
env.execute()
}
}
Session Window
package com.shujia.flink.window
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.{EventTimeSessionWindows, ProcessingTimeSessionWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object Demo2SessionWindow {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度为1,因为我们现在数据量很少
//如果设置多个并行度的话,每个并行度中的task会单独计算时间的
//假设来了一条达到计算条件的数据,进入了其中某一个并行度
//这样会产生一个问题,多个并行度之间的水位线没有对齐,那么是不会计算的
env.setParallelism(1)
//设置时间模式,不设置默认是处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val eventDS: DataStream[(String, Long)] = linesDS.map(line => {
val split: Array[String] = line.split(",")
(split(0), split(1).toLong)
})
//设置水位线和时间字段
val assDS: DataStream[(String, Long)] = eventDS.assignTimestampsAndWatermarks(
//执行水位线前移的时间
new BoundedOutOfOrdernessTimestampExtractor[(String, Long)](Time.seconds(5)) {
//指定时间戳字段
override def extractTimestamp(element: (String, Long)): Long = element._2
}
)
/**
* 会话窗口
* 一段时间没有数据生成一个窗口并开始计算,将前面的数据放到一个窗口中进行计算,每一个key是独立计时的
*
* ProcessingTimeSessionWindows: 处理时间的会话窗口
* EventTimeSessionWindows: 事件时间的会话窗口,需要设置时间字段和水位线
*/
assDS
.map(kv => (kv._1, 1))
.keyBy(_._1)
//过了5秒钟(事件时间)没有数据了生成一个窗口
.window(EventTimeSessionWindows.withGap(Time.seconds(5)))
.sum(1)
.print()
env.execute()
}
}
Count Window
package com.shujia.flink.window
import org.apache.flink.streaming.api.scala._
object Demo3CountWindow {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val kvDS: DataStream[(String, Int)] = linesDS.flatMap(_.split(",")).map((_, 1))
/**
* 滚动的统计窗口
* 滑动的统计窗口
*
*/
kvDS
.keyBy(_._1)
.countWindow(10, 2) //每隔两条数据将最近的10条数据放到一个窗口中进行计算
.sum(1)
.print()
env.execute()
}
}
Flink 窗口的底层 API
使用窗口的复杂处理
process : flink 底层 API , 可以操作 flink 的时间,事件,状态
W <: Wondow -- Scala泛型通配符,向下限定,W可以是Wondow及其子类
package com.shujia.flink.window
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object Demo4ProcessFunction {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val kvDS: DataStream[(String, Int)] = linesDS.flatMap(_.split(",")).map((_, 1))
//将同一个单词分到同一个窗口中 -- 划分窗口
val windowDS: WindowedStream[(String, Int), String, TimeWindow] = kvDS
.keyBy(_._1)
.timeWindow(Time.seconds(5))
/**
* process : flink 底层 API , 可以操作 flink 的时间,事件,状态
*
*/
//ProcessWindowFunction[IN,OUT,KEY,W <: Wondow] --需要指定4个泛型
//W <: Wondow -- Scala泛型通配符,向下限定,W可以是Wondow及其子类
//IN:输入的类型
//OUT:输出的类型
//KEY:key的类型
//W:窗口的类型
//统计单词的数量,返回 单词,窗口结束时间,单词的数量
val countDS: DataStream[(String, Long, Int)] = windowDS.process(new ProcessWindowFunction[(String, Int), (String, Long, Int), String, TimeWindow] {
/**
* process: 每一个key对应的每一个窗口执行一次process方法
*
* @param key : key
* @param context : 上下文对象,可以获取到窗口的开始和结束时间
* @param elements : 这一个key在窗口内所有的数据,是一个迭代器
* @param out : 用于将数据发送到下游
*/
override def process(key: String,
context: Context,
elements: Iterable[(String, Int)],
out: Collector[(String, Long, Int)]): Unit = {
//一个单词在一个窗口内的数量
val count: Int = elements.size
//获取窗口的结束时间
val winEndTime: Long = context.window.getEnd
//将数据发送到下游
out.collect((key, winEndTime, count))
}
})
countDS.print()
env.execute()
}
}
卡口过车需求案例
数据:json格式
{"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"00120","orientation":"西南","road_id":34053114,"time":1614711895,"speed":36.38} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"00120","orientation":"西南","road_id":34053114,"time":1614711904,"speed":35.38} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"01220","orientation":"西南","road_id":34053114,"time":1614711914,"speed":45.38} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"00210","orientation":"西北","road_id":34053114,"time":1614711924,"speed":45.29} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"01214","orientation":"西北","road_id":34053114,"time":1614712022,"speed":75.29} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"00032","orientation":"西北","road_id":34053114,"time":1614712120,"speed":46.29} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"01014","orientation":"西北","road_id":34053114,"time":1614712218,"speed":82.29} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"00104","orientation":"西北","road_id":34053114,"time":1614712316,"speed":82.29} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"00111","orientation":"西北","road_id":34053114,"time":1614712414,"speed":48.5} {"car":"皖A9A7N2","city_code":"340500","county_code":"340522","card":117988031603010,"camera_id":"01124","orientation":"西北","road_id":34053114,"time":1614712619,"speed":59.5} …………
解析 json 格式的数据
通过工具
Gson -- 谷歌提供
fastutil
fastjson -- 阿里云提供
……
导入 fastjson 依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.79</version>
</dependency>
fastJson解析json字符串
package com.shujia.flink.window
import java.lang
import com.alibaba.fastjson.{JSON, JSONObject}
object Demo6Json {
def main(args: Array[String]): Unit = {
//因为外面有 " ,所以里面的 " 被转义了
val json = "{\"car\":\"皖A9A7N2\",\"city_code\":\"340500\",\"county_code\":\"340522\",\"card\":117988031603010,\"camera_id\":\"00012\",\"orientation\":\"西北\",\"road_id\":34053114,\"time\":1614714188,\"speed\":58.51}"
/**
* fastJson 解析 json字符串
*
*/
//parseObject() -- 将json字符串转换成json对象,json对象可以使用key获取value
val jsonObj: JSONObject = JSON.parseObject(json)
//直接通过key获取value
val card: String = jsonObj.getString("card")
val time: Long = jsonObj.getLong("time")
val speed: lang.Double = jsonObj.getDouble("speed")
println(card)
println(time)
println(speed)
}
}
实现需求
package com.shujia.flink.window
import java.lang
import com.alibaba.fastjson.{JSON, JSONObject}
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object Demo5Car {
def main(args: Array[String]): Unit = {
/**
* 实时读取卡口过车数据 -- 实时统计道路拥堵情况
* 拥堵判断条件
* 1、最近一段时间的平均车速
* 2、最近一段时间的车流量
*
* 计算最近10分钟的数据,每隔1分钟计算一次
*
*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//设置时间模式
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//读取卡口过车数据
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
/**
* 解析json数据
*
*/
val carDS: DataStream[(String, Long, Double)] = linesDS.map(line => {
val jsonObj: JSONObject = JSON.parseObject(line)
//直接通过key获取value
val card: String = jsonObj.getString("card")
val time: Long = jsonObj.getLong("time")
val speed: Double = jsonObj.getDouble("speed")
//将time变成毫秒级别的
(card, time * 1000, speed)
})
/**
* 设置时间字段和水位线
*
*/
val assDS: DataStream[(String, Long, Double)] = carDS.assignTimestampsAndWatermarks(
//执行水位线前移的时间
new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Double)](Time.seconds(5)) {
//指定时间戳字段, 指定的时间字段必须是毫秒级别
override def extractTimestamp(element: (String, Long, Double)): Long = element._2
}
)
/**
*
* 计算最近10分钟的数据,每隔1分钟计算一次
*/
val windowDS: WindowedStream[(String, Long, Double), String, TimeWindow] = assDS
//按照卡口分组
.keyBy(_._1)
//划分窗口
.timeWindow(Time.minutes(10), Time.minutes(1))
/**
* 1、最近一段时间的平均车速
* 2、最近一段时间的车流量
*
* 输出结果
* 卡口,窗口的结束时间,平均车速,车的数量
*/
val resultDS: DataStream[(String, Long, Double, Long)] = windowDS.process(new ProcessWindowFunction[(String, Long, Double), (String, Long, Double, Long), String, TimeWindow] {
override def process(key: String,
context: Context,
elements: Iterable[(String, Long, Double)],
out: Collector[(String, Long, Double, Long)]): Unit = {
var num = 0
var sumSpeed = 0.0
//(card, time, speed) <- elements -- 直接接收遍历出来的数据
for ((card, time, speed) <- elements) {
//统计车辆数量
num += 1
//总的车速
sumSpeed += speed
}
//计算平均车速
val avgSpeed: Double = sumSpeed / num
//获取窗口的结束时间
val endTIme: Long = context.window.getEnd
//将数据发送到下游
out.collect((key, endTIme, avgSpeed, num))
}
})
resultDS.print()
env.execute()
}
}
