Flink 并行度、共享槽位、如何判断Flink需要使用多少资源、查看Flink需要处理的数据频率
Flink 并行度
package com.shujia.flink.core
import org.apache.flink.streaming.api.datastream.DataStreamSink
import org.apache.flink.streaming.api.scala._
object Demo4Parallelism {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
*
* flink 的并行度
* 1、如果代码中不设置并行度,在提交任务的时候默认是1,可以在提交任务的时候指定并行度 参数: -p
* flink run -p 并行度的数量 -C 主类名 jar包名
*
* 2、代码中可以设置并行度 setParallelism ,代码的优先级比 -p 参数要高
* 3、每一个节点可以单独设置并行度
* 4、如果节点之前的关系没有产生 shuffle 并且并行度一致,可以合并成一个task
*
*
*/
/**
* 设置默认的并行度
*
*/
//env.setParallelism(4) -- 结果发现 linesDS 的并行度还是1
/**
* 读取socket的并行度只能是1
* 因为socket不支持同时被多个线程去读
*/
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
linesDS.name("读取socket数据")
// .parallelism -- 获取DataStream并行度
println(s"linesDS的并行度:${linesDS.parallelism}")
/**
* 节点的并行度由默认并行度决定
* 也可以单独设置每一个节点的并行度
* 单独设置并行度的优先级 > 默认并行度
* Flink中基本上所有的算子都可以改变它的并行度
*/
val wordsDS: DataStream[String] = linesDS.flatMap(_.split(","))
//单独设置每一个节点的并行度
//wordsDS.setParallelism(1)
// .name("展开数据") -- 设置节点的名称
wordsDS.name("展开数据")
println(s"wordsDS的并行度:${wordsDS.parallelism}")
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
/**
* 如果上游节点和下游节点并行度一样,同时算子不产生shuffle, 可以合并成一个task
*
*/
// kvDS.setParallelism(1)
kvDS.name("转换成kv")
println(s"kvDS的并行度:${kvDS.parallelism}")
/**
* keyBy不能设置名称和并行度,因为keyBy不构成一个节点,是一个隐藏的过程
*
* 在Flink中没有去重和排序,因为数据是一条一条流过来的
*/
val keyVyDS: KeyedStream[(String, Int), String] = kvDS.keyBy(_._1)
val countDS: DataStream[(String, Int)] = keyVyDS.sum(1)
countDS.name("统计单词的数量")
//countDS.setParallelism(2)
// print 也可以接收,返回 DataStreamSink
val print: DataStreamSink[(String, Int)] = countDS.print()
//基本上所有算子都可以设置并行度
//print.setParallelism(2)
//print也能设置节点的名字
print.name("打印结果")
env.execute()
}
}
并行数据流
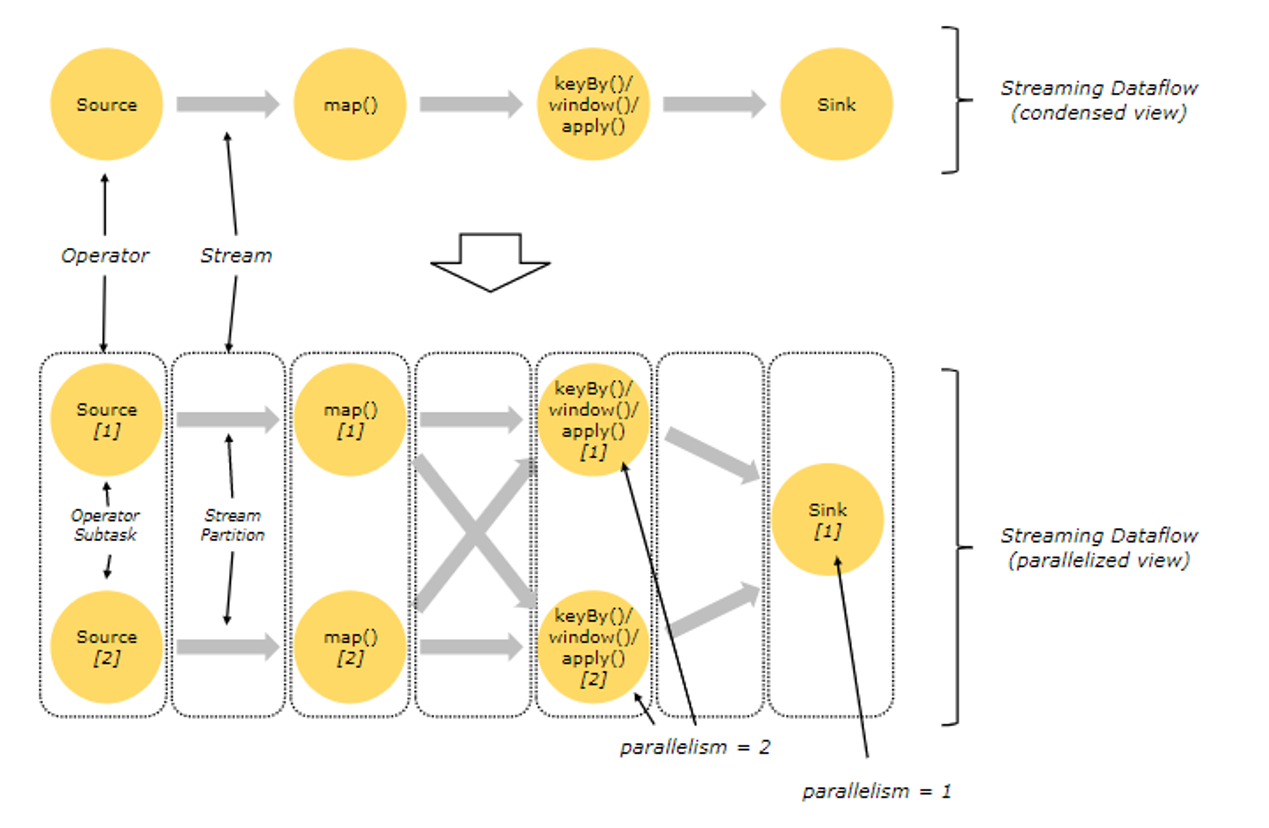
上图中有5个Task,那么这5个task是如何部署的呢?
任务槽和资源
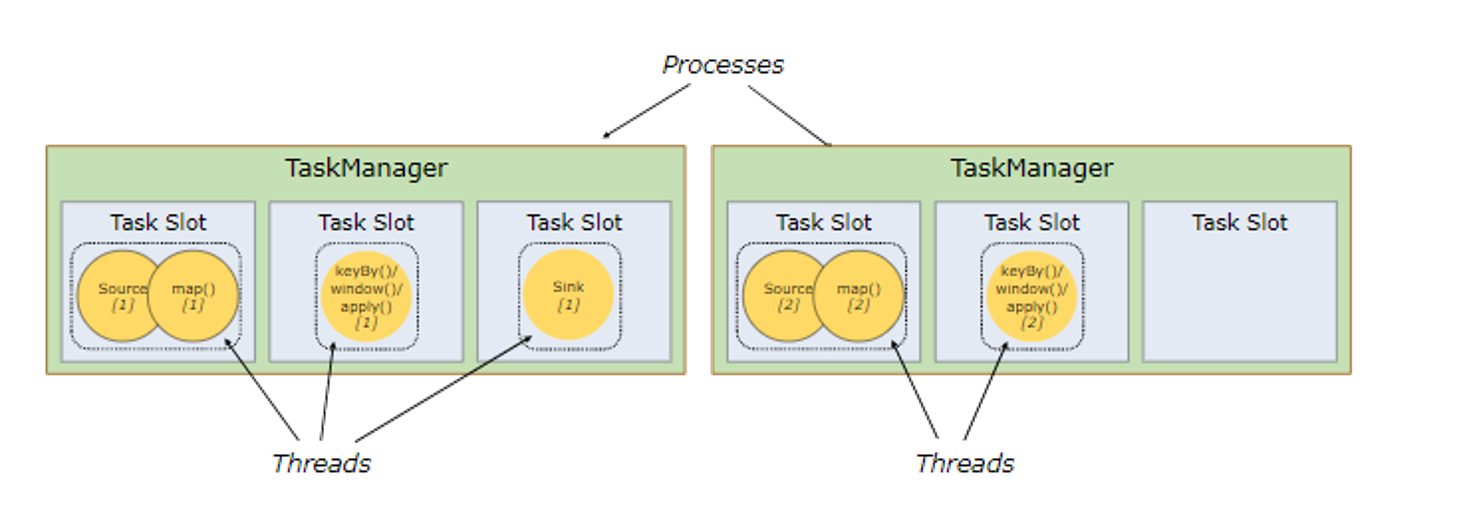
Flink 并不是这样部署的
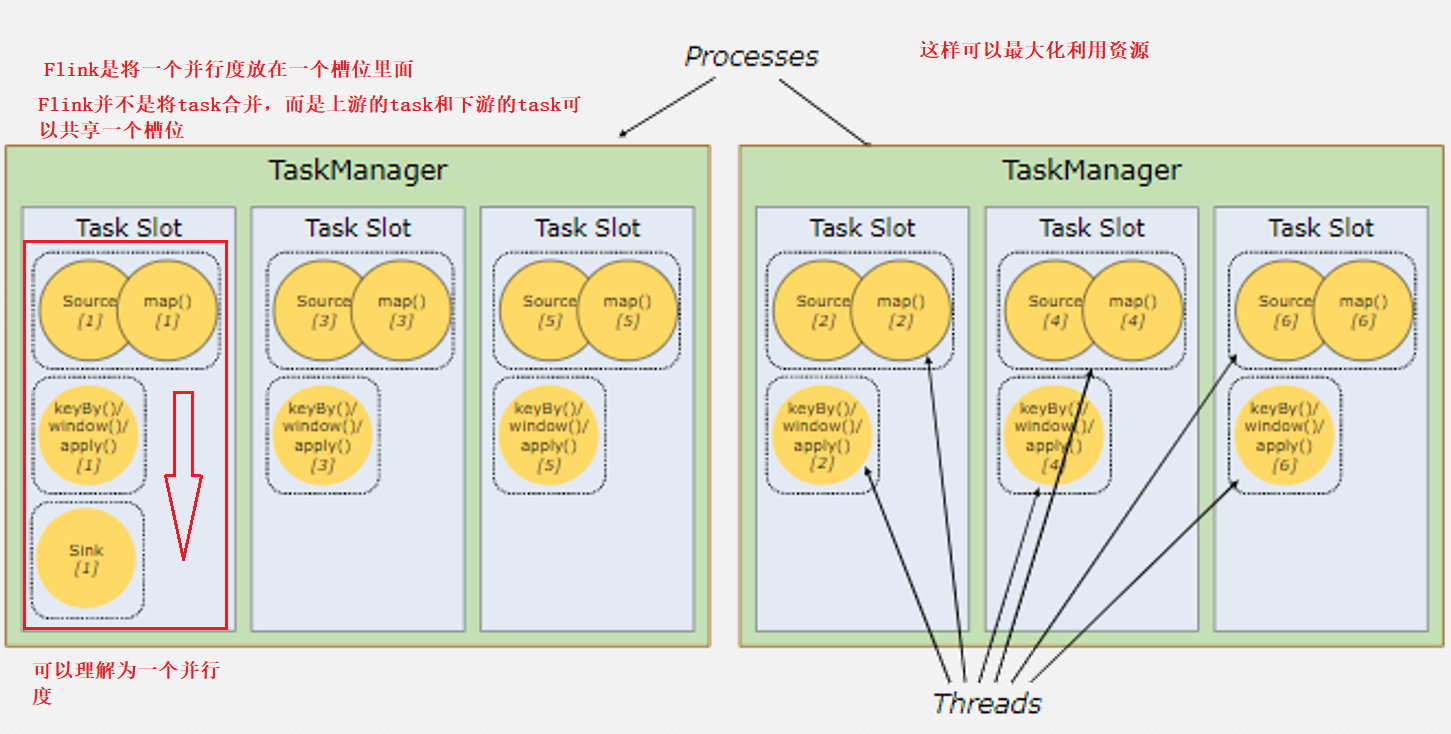
共享槽位
Flink并不是将task合并,而是上游的task和下游的task可以共享一个槽位
所以Flink需要使用多少资源和task的数量没有关系,而是和节点的最大并行度有关系,因为有几个并行度就需要几个槽位
这样不仅可以节省资源,还可以提高数据传输的效率。
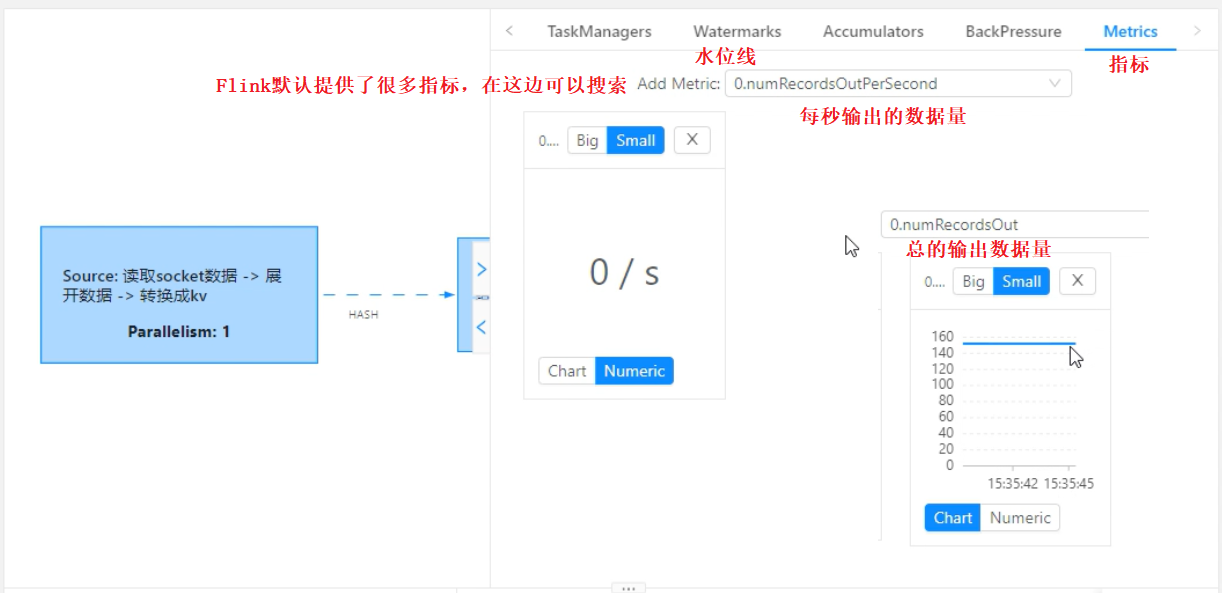
如何判断Flink需要使用多少资源
1、需要看一下集群的资源
可以从yarn的web界面查看
2、将来需要处理的数据量
可以从Flink的web界面查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号