
Flink 环境的搭建、Standallone Cluster 独立集群、Flink on Yarn、访问Flink web界面、Flink提交任务的三种方式、Flink读取HDFS上的数据、Flink集群的架构图、Flink on Yarn 图
Flink 环境的搭建
1、local 本地测试
2、Standallone Cluster 独立集群(可能用的上)
3、Flink on Yarn 推荐
Standallone Cluster 独立集群
独立集群是不依赖hadoop的,所以可以先停掉 Hadoop
注意:独立集群的搭建需要配置 JAVA_HOME 和 免密登录
1、上传、解压、配置环境变量
cd /usr/local/module
tar -zxvf /usr/local/module/flink-1.11.2-bin-scala_2.11.tgz -C /usr/local/soft/
vim /etc/profile
export FLINK_HOME=/usr/local/soft/flink-1.11.2
export PATH=$PATH:$FLINK_HOME/bin
source /etc/profile
2、修改配置文件
在此之前我们先来简单了解一下Flink集群的架构
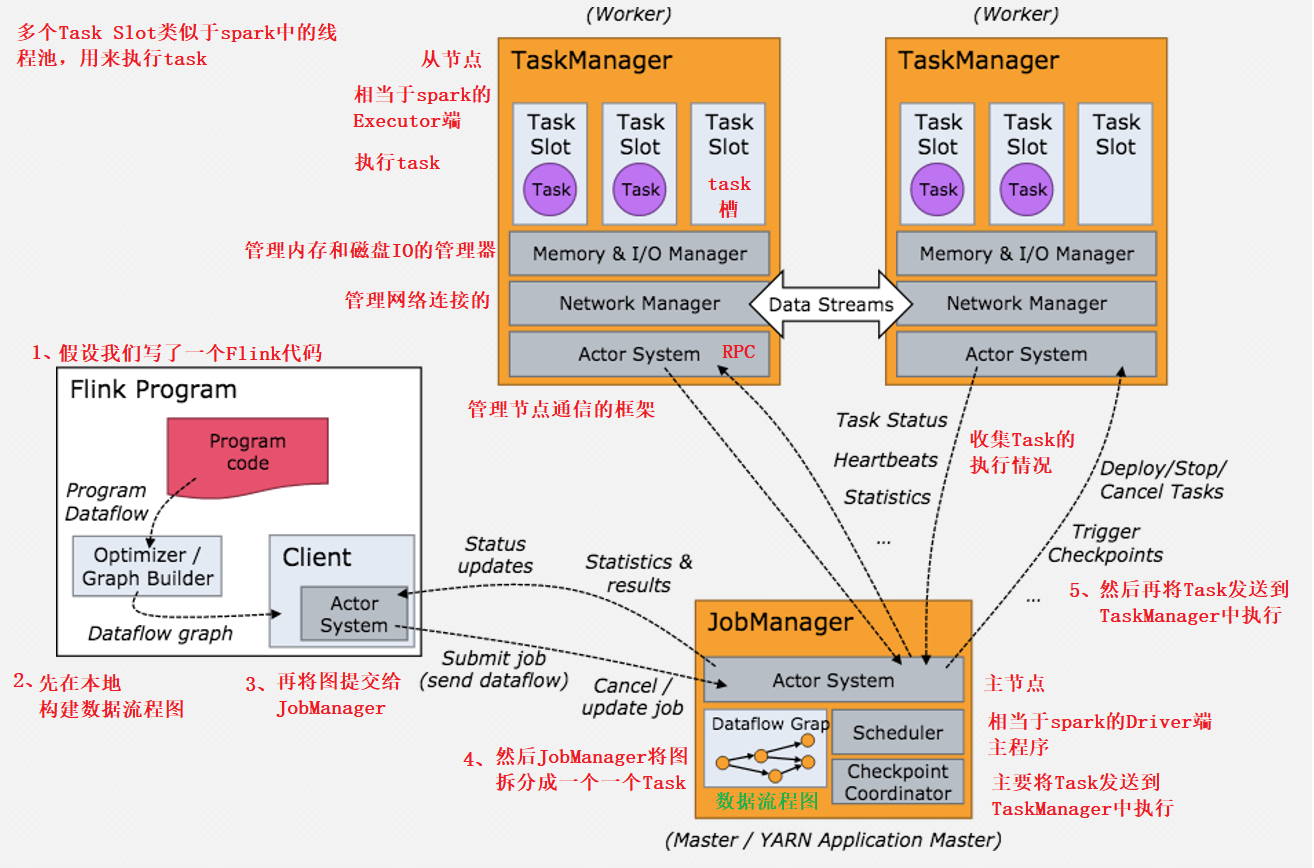
vim /usr/local/soft/flink-1.11.2/conf/flink-conf.yaml
# (修改)指定主节点ip地址
jobmanager.rpc.address: master
vim workers
# (修改)指定从节点
node1
node2
vim masters
# 改成主节点master
master:8081
3、同步到所有节点
scp -r /usr/local/soft/flink-1.11.2/ node1:`pwd`
scp -r /usr/local/soft/flink-1.11.2/ node2:`pwd`
4、启动(停止)集群
Flink集群的命令都在 bin 目录下,不记得可以去找
所有主从架构的集群都是在主节点操作命令
# 启动
start-cluster.sh
# 停止
stop-cluster.sh
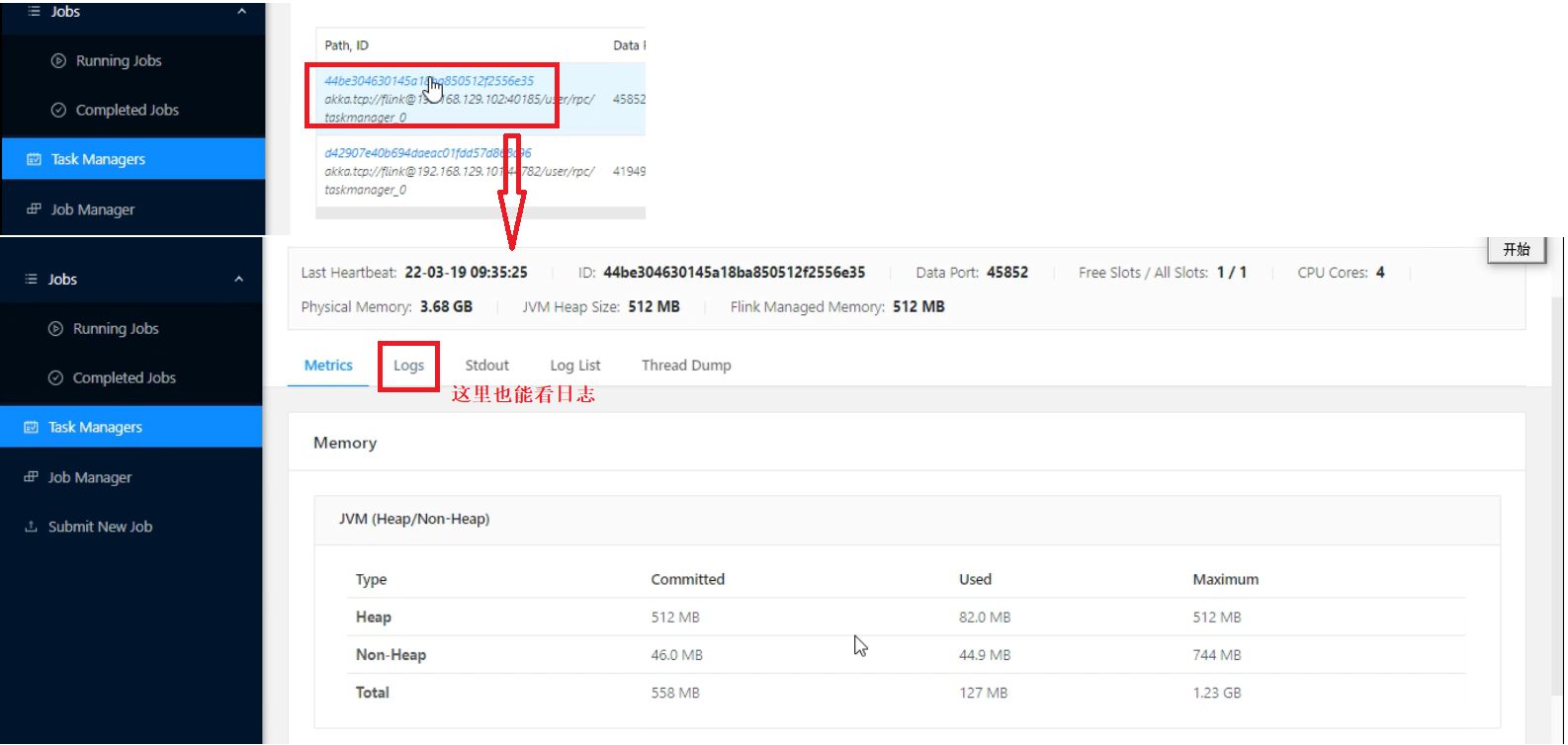
访问Flink web界面
http://master:8081
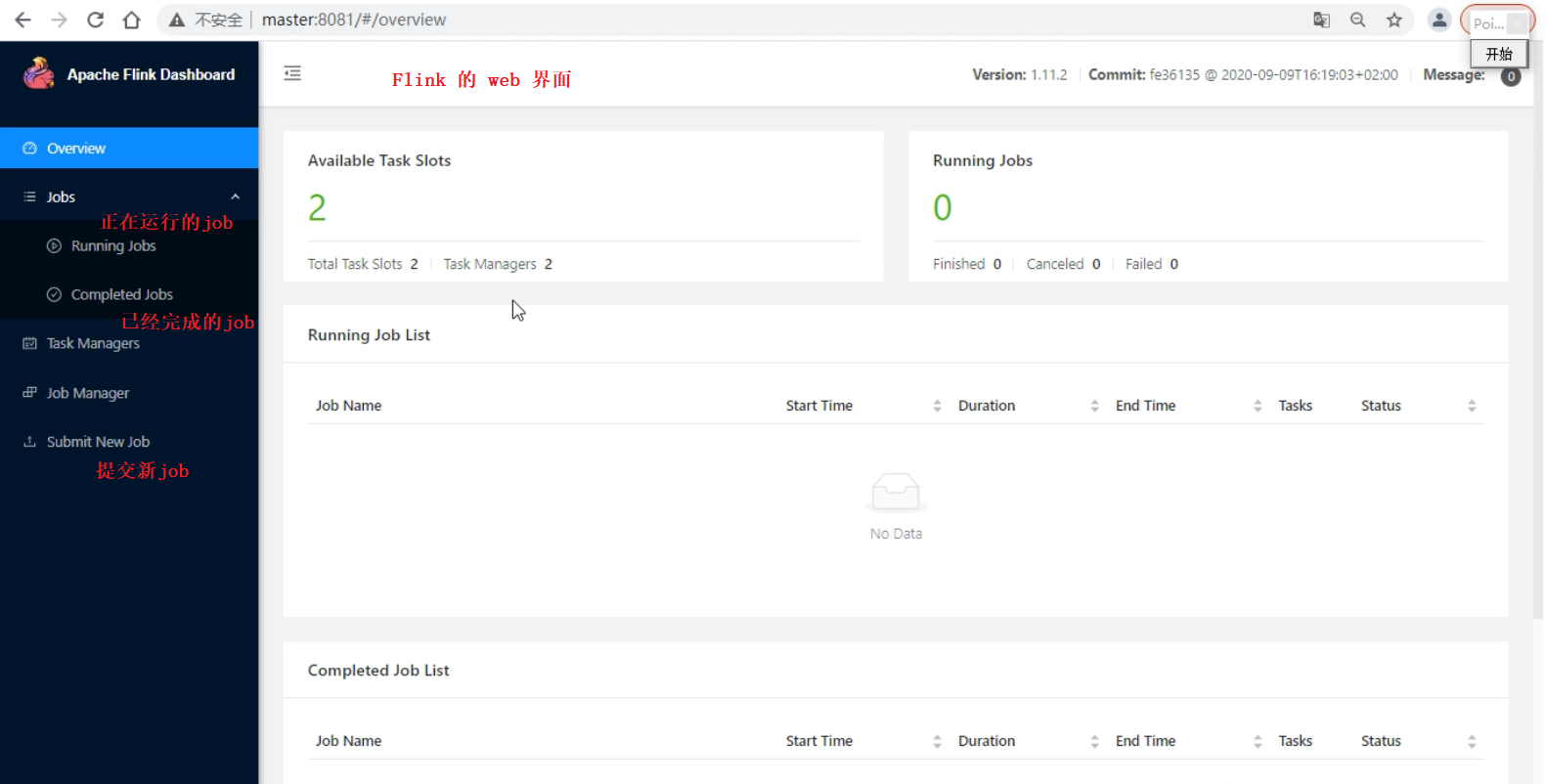
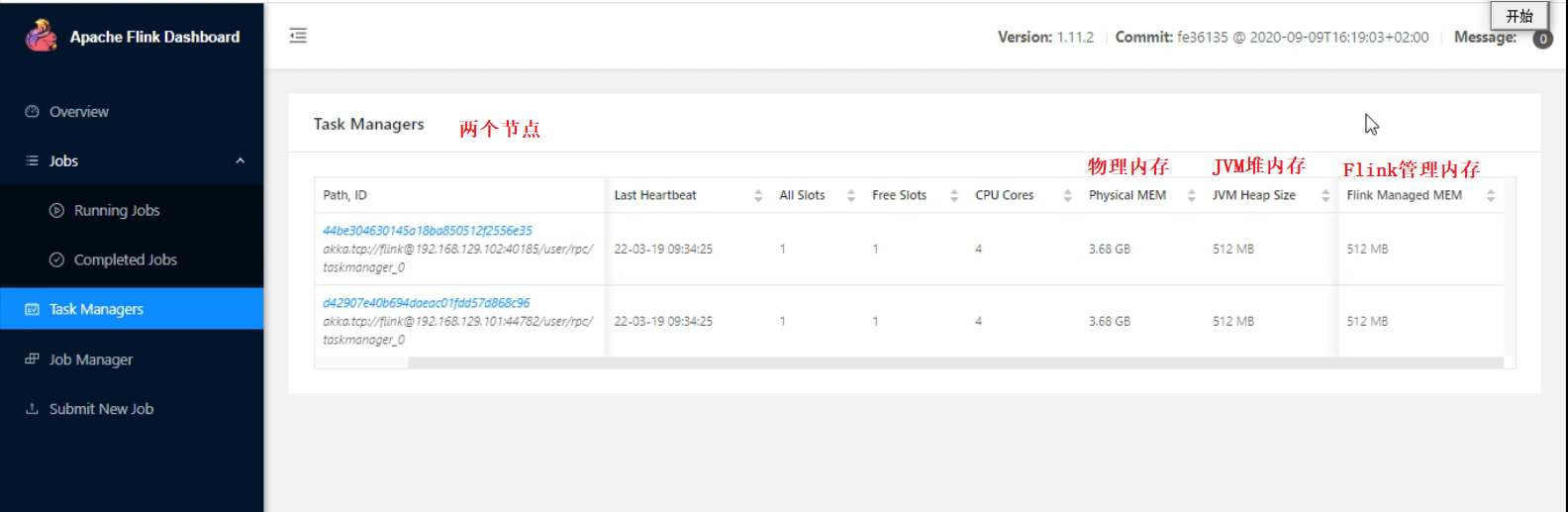
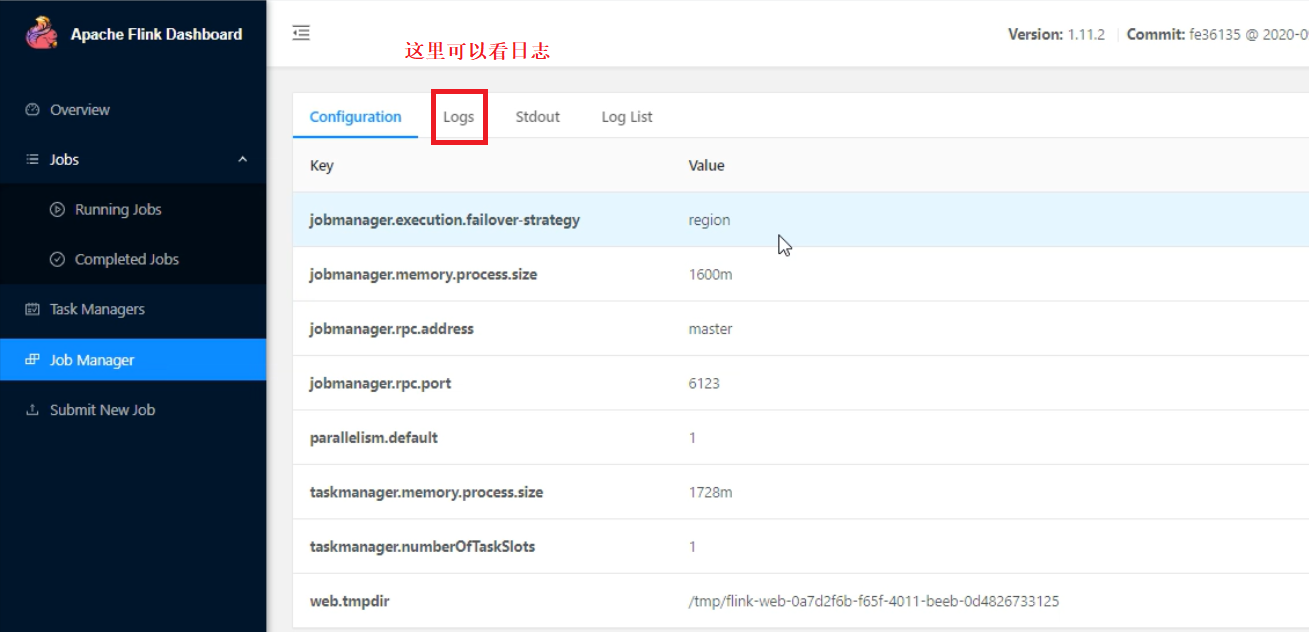
Flink提交任务的三种方式
1、在web页面中提交
以昨天WordCount代码为例(代码不需要改),将之打成jar包
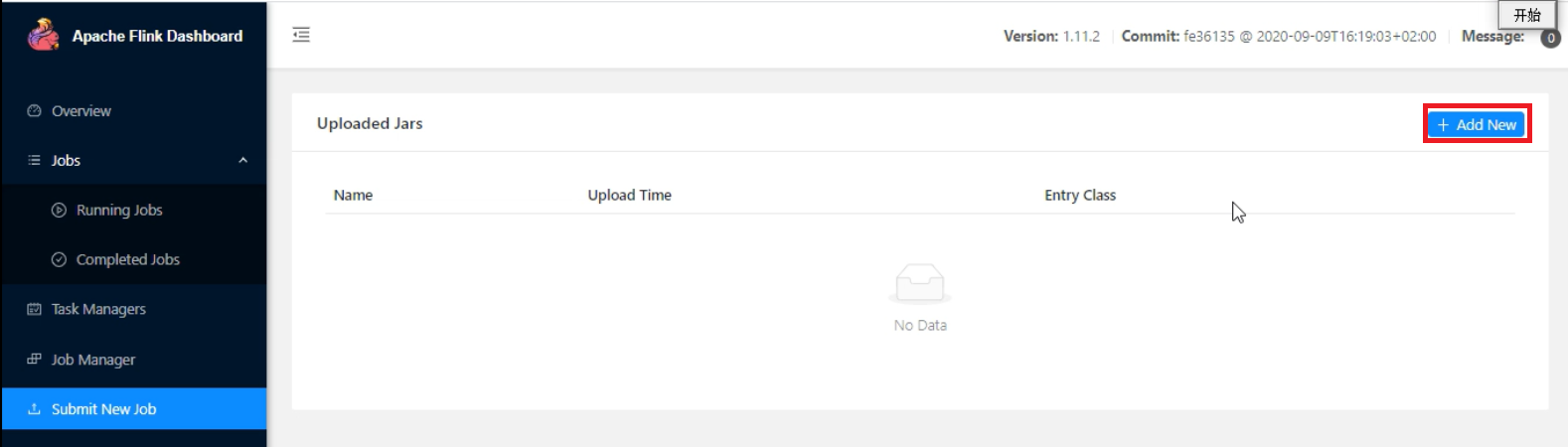
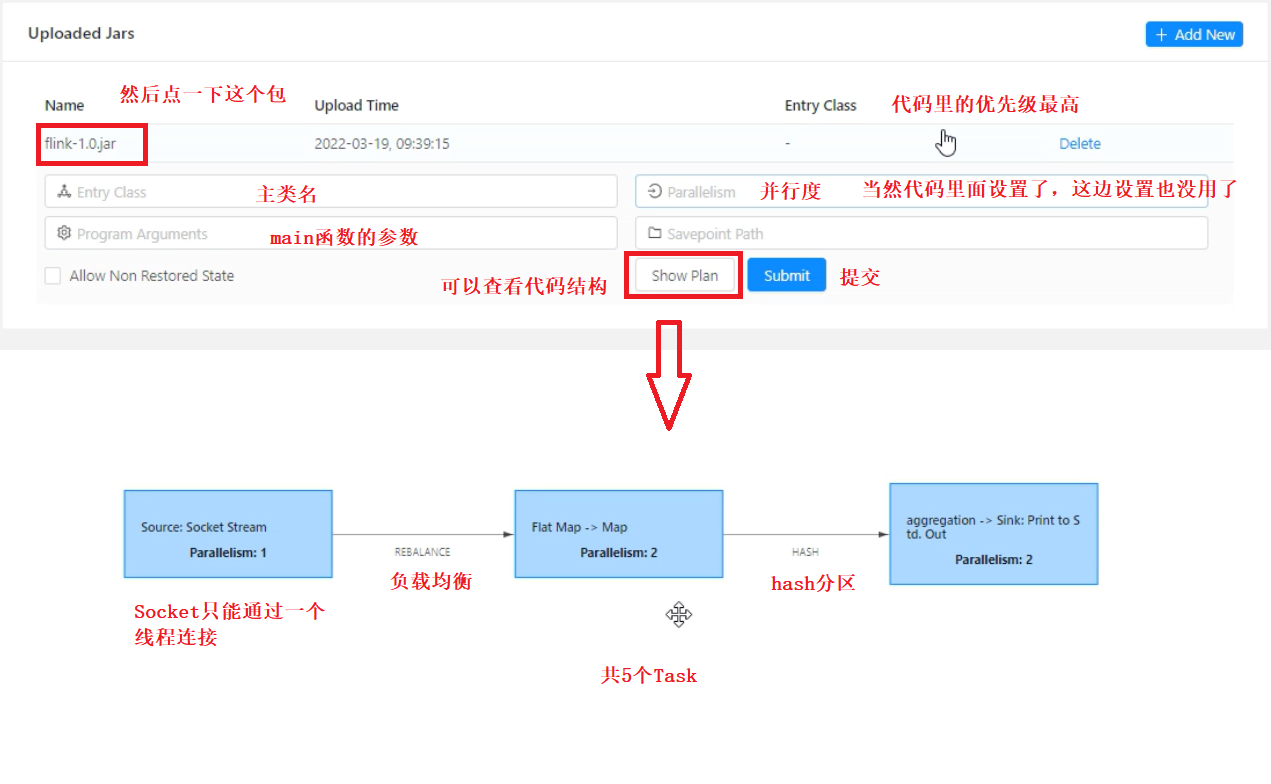
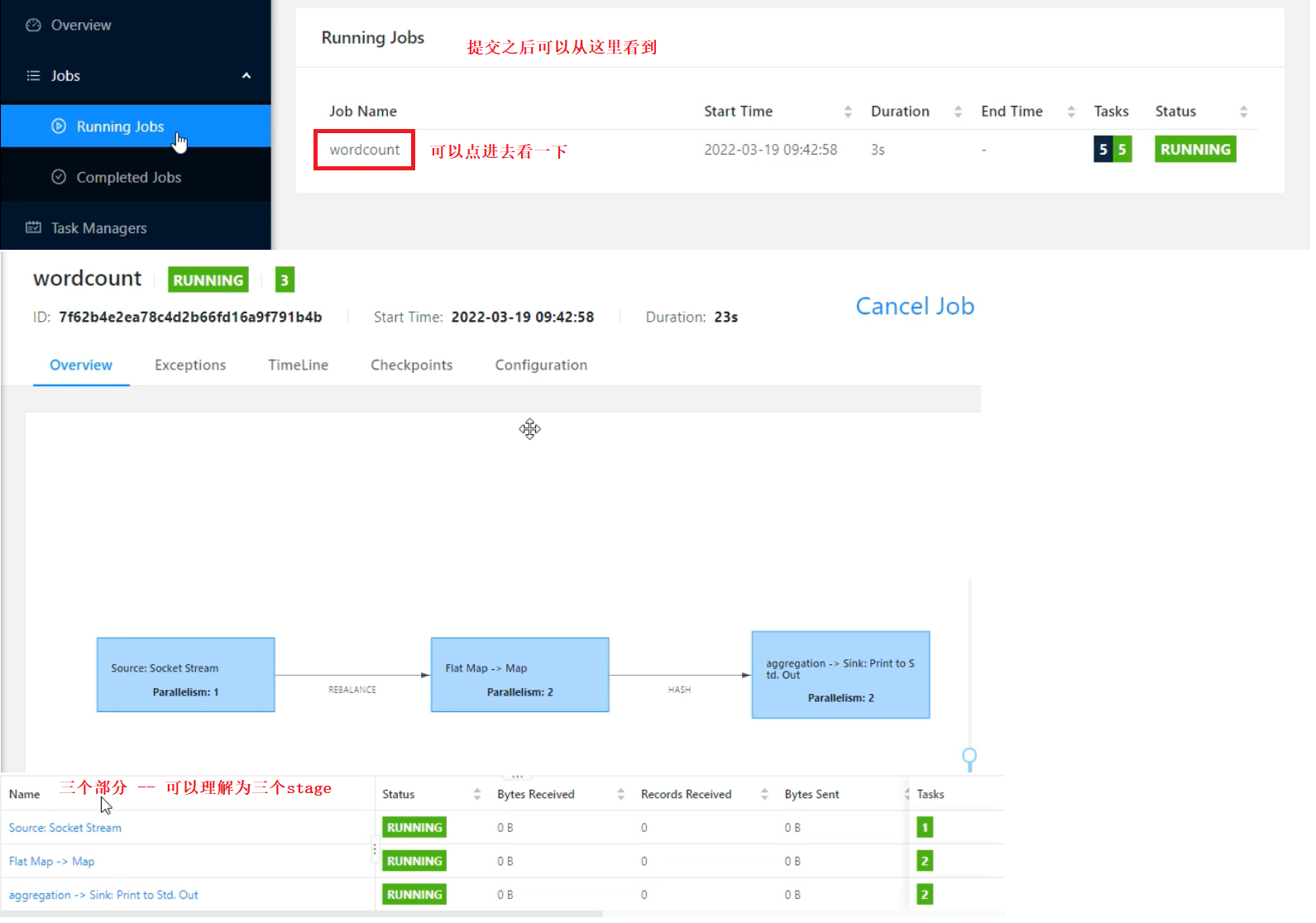
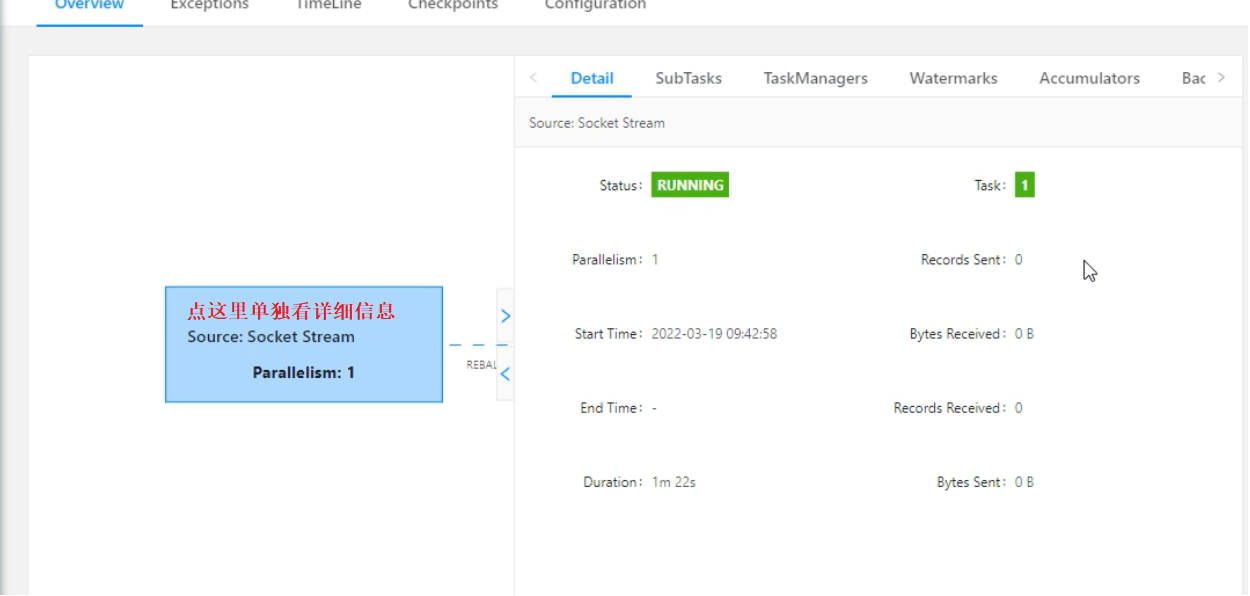
2、通过flink命令提交任务
将jar包上传至集群,提交任务
flink run -c com.shujia.flink.soure.Demo4ReadKafka flink-1.0.jar
com.shujia.flink.soure.Demo4ReadKafka -- 主类名
flink-1.0.jar -- jar包名
3、rpc方式提交任务 --- 远程提交
用的较少
代码写完之后需要先打包,再运行
Flink框架报错有一个特点:前几条报错原因都是废话,要从后面看
package com.shujia.flink.core
import org.apache.flink.streaming.api.scala._
object Demo2RpcSubmit {
def main(args: Array[String]): Unit = {
/**
* 创建远程环境,远程提交flink任务
*
*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createRemoteEnvironment(
//主机名
"master",
//端口号
8081,
//指定jar包的路径
"C:\\Users\\qx\\IdeaProjects\\bigdata14\\flink\\target\\flink-1.0.jar"
)
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
//1、将数据展开
val wordsDS: DataStream[String] = linesDS.flatMap(line => line.split(","))
//2、转换成kv格式
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
//3、按照单词进行分组
val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(kv => kv._1)
//4、统计数量,对value进行求和, 指定下标进行聚合
val countDS: DataStream[(String, Int)] = keyByDS.sum(1)
//打印结果
countDS.print()
env.execute("rpc")
}
}
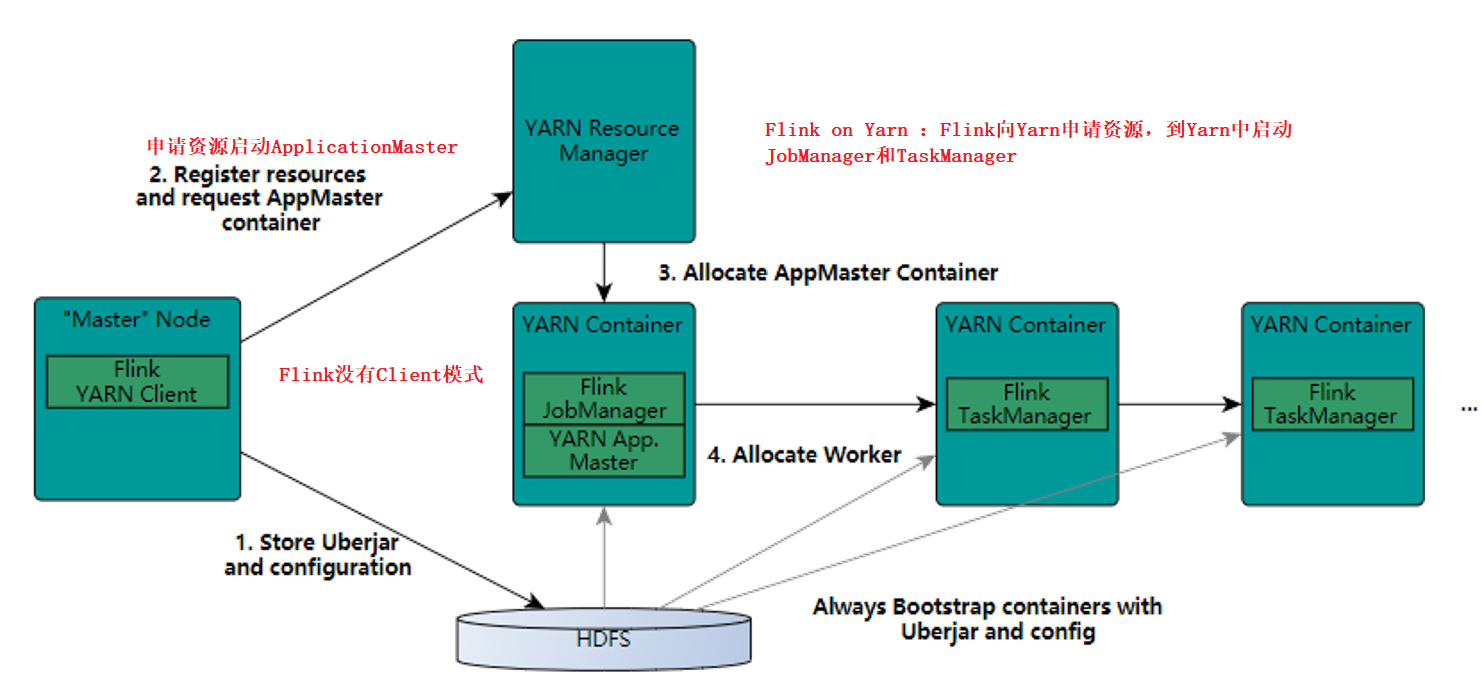
Flink on Yarn
只需要部署一个节点 -- 在master中部署即可
需要先将独立集群停掉
JAVA_HOME、免密登录、上传、解压、配置环境变量 -- 这些配置都要做
1、配置HADOOP_CONF_DIR
export -- 全局生效
vim /etc/profile
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-2.7.6/etc/hadoop/
2、将hadoop依赖jar上传到flink lib目录
#jar包名
flink-shaded-hadoop-2-uber-2.6.5-10.0.jar
flink和spark一样都是粗粒度资源申请
启动方式
1、yarn-session 在yarn里面启动一个flink集群 jobManager(ApplicationMaster)
需要先启动Hadoop
yarn-session是所有任务共享同一个jobmanager
# 在master中
# 开启
# 启动完毕之后会返回一个地址给我们 -- Flink集群的web界面
yarn-session.sh -jm 1024m -tm 1096m
-jm 1024m -- 指定JobManager的内存
-tm 1096m -- 指定TaskManager的内存
# 提交任务 任务提交的时候是根据并行度动态申请taskmanager
1、在web页面提交任务
2、同flink命令提交任务
flink run -c com.shujia.flink.soure.Demo4ReadKafka flink-1.0.jar
3、rpc方式提交任务
# 任务结束之后,资源被动态回收
# 关闭
yarn application -kill application_1647657435495_0001
application_1647657435495_0001 -- yarn-session的yarn上进程号
stop 也能退出
2、直接提交任务到yarn 每一个任务都会有一个jobManager
flink run -m yarn-cluster -yjm 1024m -ytm 1096m -c com.shujia.flink.core.Demo1WordCount flink-1.0.jar
-m yarn-cluster -- 指定提交模式
-yjm 1024m -ytm 1096m -- 指定JobManager和TaskManager的内存
-c com.shujia.flink.core.Demo1WordCount -- 指定主类名
flink-1.0.jar -- 指定jar包名
# 杀掉yarn上的任务
yarn application -kill application_1599820991153_0005
# 查看日志
yarn logs -applicationId application_1647657435495_0002
yarn-session先在yarn中启动一个jobMansager ,所有的任务共享一个jobmanager (提交任务更快,任务之间共享jobmanager , 相互有影响)
直接提交任务模型,为每一个任务启动一个joibmanager (每一个任务独立jobmanager , 任务运行稳定)
Flink读取HDFS上的数据
package com.shujia.flink.core
import java.util.concurrent.TimeUnit
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala._
object Demo3FlinkOnHdfs {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 读取hdfs中的数据 -- 有界流
*
*/
val studentDS: DataStream[String] = env.readTextFile("hdfs://master:9000/data/student")
val clazzNumDS: DataStream[(String, Int)] = studentDS
.map(stu => (stu.split(",")(4), 1))
.keyBy(_._1)
.sum(1)
/**
* 将数据保存到hdfs
*
*/
val sink: StreamingFileSink[(String, Int)] = StreamingFileSink
//指定保存路径和数据的编码格式
.forRowFormat(new Path("hdfs://master:9000/data/flink_clazz"), new SimpleStringEncoder[(String, Int)]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toSeconds(15))
.withInactivityInterval(TimeUnit.MINUTES.toSeconds(5))
.withMaxPartSize(1024)
.build())
.build()
clazzNumDS.addSink(sink)
env.execute()
}
}
