
DataStream常用算子
DataStream常用算子
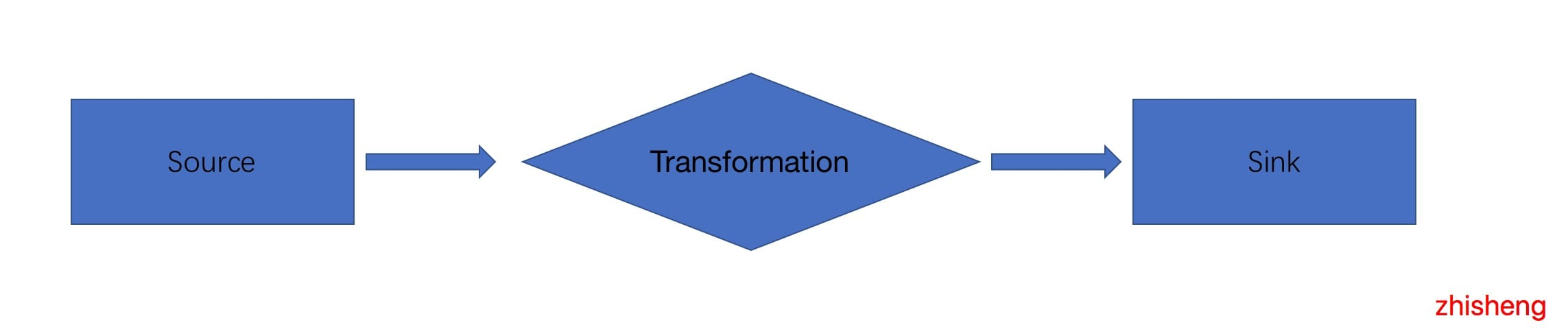
在 Flink 应用程序中,无论你的应用程序是批程序,还是流程序,都是上图这种模型,有数据源(source),有数据下游(sink),我们写的应用程序多是对数据源过来的数据做一系列操作,总结如下。
- Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
- Transformation: 数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
- Sink: 接收器,Sink 是指 Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来。Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 Socket 、自定义的 Sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
那么本文将给大家介绍的就是 Flink 中的批和流程序常用的算子(Operator)。
DataStream Operator 我们先来看看流程序中常用的算子。
1、Map
Map 算子的输入流是 DataStream,经过 Map 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成一个元素,举个例子:
SingleOutputStreamOperator<Employee> map = employeeStream.map(new MapFunction<Employee, Employee>() {
@Override
public Employee map(Employee employee) throws Exception {
employee.salary = employee.salary + 5000;
return employee;
}
});
map.print();
新的一年给每个员工的工资加 5000。
Map 程序示例
package com.shujia.flink.tf
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
object Demo1Map {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val studentDS: DataStream[String] = env.readTextFile("data/students.txt")
/**
* map 算子
* 1、传入一个函数 -- scala api
* 2、传入一个MapFunction -- java api
*/
val mapDS: DataStream[(String, Int)] = studentDS.map(new MapFunction[String, (String, Int)] {
/**
* @param value : DS中的一行数据
* @return 返回数据的类型
*/
override def map(value: String): (String, Int) = {
val clazz: String = value.split(",")(4)
(clazz, 1)
}
})
mapDS
.keyBy(_._1)
.sum(1)
.print()
env.execute()
}
}
2、FlatMap
FlatMap 算子的输入流是 DataStream,经过 FlatMap 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成零个、一个或多个元素,举个例子:
SingleOutputStreamOperator<Employee> flatMap = employeeStream.flatMap(new FlatMapFunction<Employee, Employee>() {
@Override
public void flatMap(Employee employee, Collector<Employee> out) throws Exception {
if (employee.salary >= 40000) {
out.collect(employee);
}
}
});
flatMap.print();
将工资大于 40000 的找出来。
FlatMap 程序示例
package com.shujia.flink.tf
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object Demo2FlatMap {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.readTextFile("data/words.txt")
//scala api
val scalaDS: DataStream[String] = linesDS.flatMap(_.split(","))
//java api
val wordDS: DataStream[String] = linesDS.flatMap(new FlatMapFunction[String, String] {
/**
* @param value : 原始的数据类型
* @param out : 用于将数据发送到下游
*/
override def flatMap(value: String, out: Collector[String]): Unit = {
val split: Array[String] = value.split(",")
//将数据一条一条发送到下游
for (word <- split) {
//将数据发送到下游
out.collect(word)
}
}
})
wordDS.print()
env.execute()
}
}
3、Filter
SingleOutputStreamOperator filter = ds.filter(new FilterFunction<Employee>() {
@Override
public boolean filter(Employee employee) throws Exception {
if (employee.salary >= 40000) {
return true;
}
return false;
}
});
filter.print();
对每个元素都进行判断,返回为 true 的元素,如果为 false 则丢弃数据,上面找出工资大于 40000 的员工其实也可以用 Filter 来做
Filter 程序示例
package com.shujia.flink.tf
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Demo3Filter {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val studentDS: DataStream[String] = env.readTextFile("data/students.txt")
val filterDS: DataStream[String] = studentDS.filter(new FilterFunction[String] {
/**
* 在Flink中没有转换算子和操作算子的区分
*
* @param value : 数据
* @return : 返回值,如果返回true 保留数据,如果返回false 过滤数据
*/
override def filter(value: String): Boolean = {
val gender: String = value.split(",")(3)
"男".equals(gender)
}
})
filterDS.print()
env.execute()
}
}
4、KeyBy

KeyBy 在逻辑上是基于 key 对流进行分区,相同的 Key 会被分到一个分区(这里分区指的就是下游算子多个并行节点的其中一个)。在内部,它使用 hash 函数对流进行分区。它返回 KeyedDataStream 数据流。举个例子:
KeyedStream<ProductEvent, Integer> keyBy = productStream.keyBy(new KeySelector<ProductEvent, Integer>() {
@Override
public Integer getKey(ProductEvent product) throws Exception {
return product.shopId;
}
});
keyBy.print();
根据商品的店铺 id 来进行分区。
KeyBy 程序示例
package com.shujia.flink.tf
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala._
object Demo4KeyBY {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val wordsDS: DataStream[String] = linesDS.flatMap(_.split(","))
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
/**
* keyBy 将相同的key 发送到同一个task中
*
*/
//scala api
//kvDS.keyBy(kv => kv._1).print()
//java api
val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(new KeySelector[(String, Int), String] {
override def getKey(value: (String, Int)): String = {
value._1
}
})
keyByDS.print()
env.execute()
}
}
5、Reduce
Reduce 返回单个的结果值,并且 reduce 操作每处理一个元素总是创建一个新值。常用的方法有 average、sum、min、max、count,使用 Reduce 方法都可实现。
SingleOutputStreamOperator<Employee> reduce = employeeStream.keyBy(new KeySelector<Employee, Integer>() {
@Override
public Integer getKey(Employee employee) throws Exception {
return employee.shopId;
}
}).reduce(new ReduceFunction<Employee>() {
@Override
public Employee reduce(Employee employee1, Employee employee2) throws Exception {
employee1.salary = (employee1.salary + employee2.salary) / 2;
return employee1;
}
});
reduce.print();
上面先将数据流进行 keyby 操作,因为执行 Reduce 操作只能是 KeyedStream,然后将员工的工资做了一个求平均值的操作。
Reduce 程序示例
package com.shujia.flink.tf
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
object Demo5Reduce {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val wordsDS: DataStream[String] = linesDS.flatMap(_.split(","))
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(_._1)
/**
* reduce: 分组之后进行聚合计算
*
*/
//scala api
//val reduceDS: DataStream[(String, Int)] = keyByDS.reduce((x, y) => (y._1, x._2 + y._2))
//java api
val reduceDS: DataStream[(String, Int)] = keyByDS.reduce(new ReduceFunction[(String, Int)] {
override def reduce(value1: (String, Int), value2: (String, Int)): (String, Int) = {
(value1._1, value1._2 + value2._2)
}
})
reduceDS.print()
env.execute()
}
}
6、Aggregations
DataStream API 支持各种聚合,例如 min、max、sum 等。 这些函数可以应用于 KeyedStream 以获得 Aggregations 聚合。
KeyedStream.sum(0)
KeyedStream.sum("key")
KeyedStream.min(0)
KeyedStream.min("key")
KeyedStream.max(0)
KeyedStream.max("key")
KeyedStream.minBy(0)
KeyedStream.minBy("key")
KeyedStream.maxBy(0)
KeyedStream.maxBy("key")
max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键, min 和 minBy 同理。
Aggregations 程序示例
package com.shujia.flink.tf
import org.apache.flink.streaming.api.scala._
object Demo6Agg {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val studentDS: DataStream[String] = env.readTextFile("data/students.txt")
/**
* 取出每个班级年龄最大的学生
*
*/
val stuDS: DataStream[(String, String, Int, String, String)] = studentDS.map(line => {
val split: Array[String] = line.split(",")
(split(0), split(1), split(2).toInt, split(3), split(4))
})
val keyByDS: KeyedStream[(String, String, Int, String, String), String] = stuDS.keyBy(_._5)
/**
*
* sum
* max
* min
* maxBy
* minBy
*
* max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键, min 和 minBy 同理。
*
*/
//maxBy() -- 可以传入 列名 或者 下标
val maxDS: DataStream[(String, String, Int, String, String)] = keyByDS.maxBy(2)
maxDS.print()
env.execute()
}
}
7、Window
Window 函数允许按时间或其他条件对现有 KeyedStream 进行分组。 以下是以 10 秒的时间窗口聚合:
inputStream.keyBy(0).window(Time.seconds(10));
有时候因为业务需求场景要求:聚合一分钟、一小时的数据做统计报表使用。
Window 程序示例
这边先看个简单的,之后有 Window 详解
package com.shujia.flink.tf
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object Demo7Window {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val wordsDS: DataStream[String] = linesDS.flatMap(_.split(","))
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
/**
* 每隔5秒统计单词的数量
* timeWindow() -- 里面可以传入一个参数(滚动窗口)或者两个参数(滑动窗口)
*/
kvDS
.keyBy(_._1)
.timeWindow(Time.seconds(5)) //滚动窗口
.sum(1)
.print()
env.execute()
}
}
8、Union
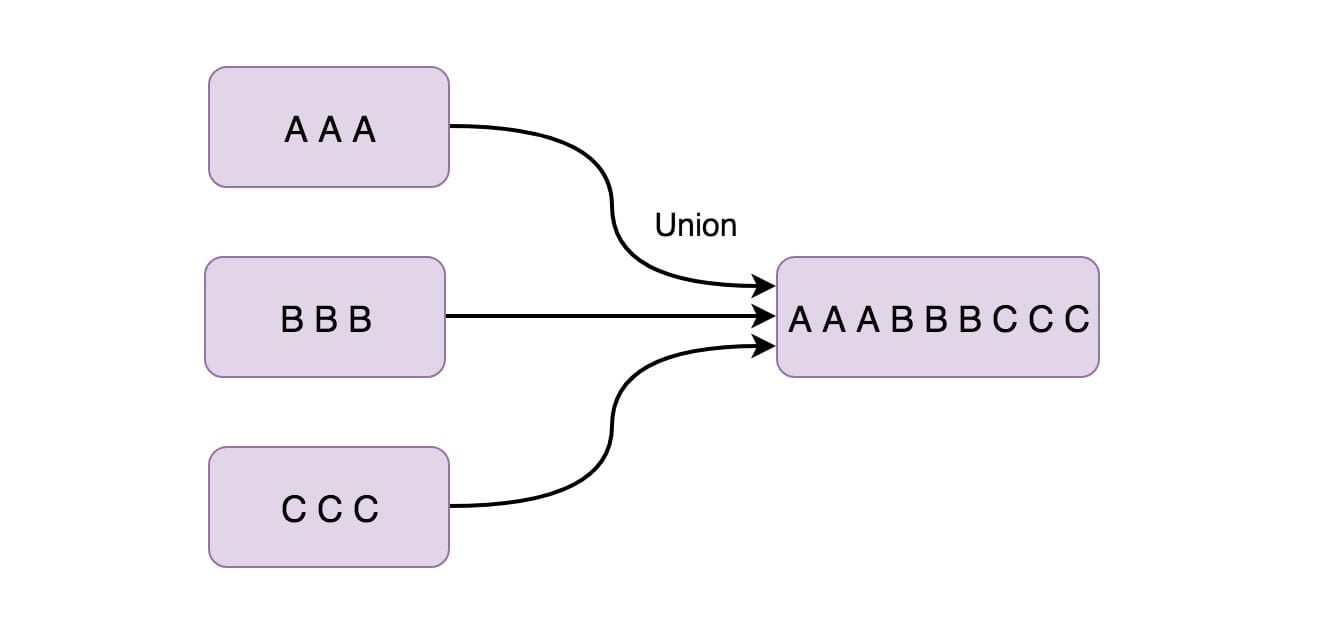
Union 函数将两个或多个数据流结合在一起。 这样后面在使用的时候就只需使用一个数据流就行了。 如果我们将一个流与自身组合,那么组合后的数据流会有两份同样的数据。
inputStream.union(inputStream1, inputStream2, ...);
Union 程序示例
package com.shujia.flink.tf
// 当代码中没有用到Scala API的时候不需要导 _ (隐式转换)
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
object Demo8Union {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val ds1: DataStream[String] = env.socketTextStream("master", 7777)
val ds2: DataStream[String] = env.socketTextStream("master", 8888)
/**
* 将多个流合并成一个流,类型要一致
*
*/
val unionDS: DataStream[String] = ds1.union(ds2)
unionDS.print()
env.execute()
}
}
9、Window Join
我们可以通过一些 key 将同一个 window 的两个数据流 join 起来。
inputStream.join(inputStream1)
.where(0).equalTo(1)
.window(Time.seconds(5))
.apply (new JoinFunction () {...});
以上示例是在 5 秒的窗口中连接两个流,其中第一个流的第一个属性的连接条件等于另一个流的第二个属性。
10、Split
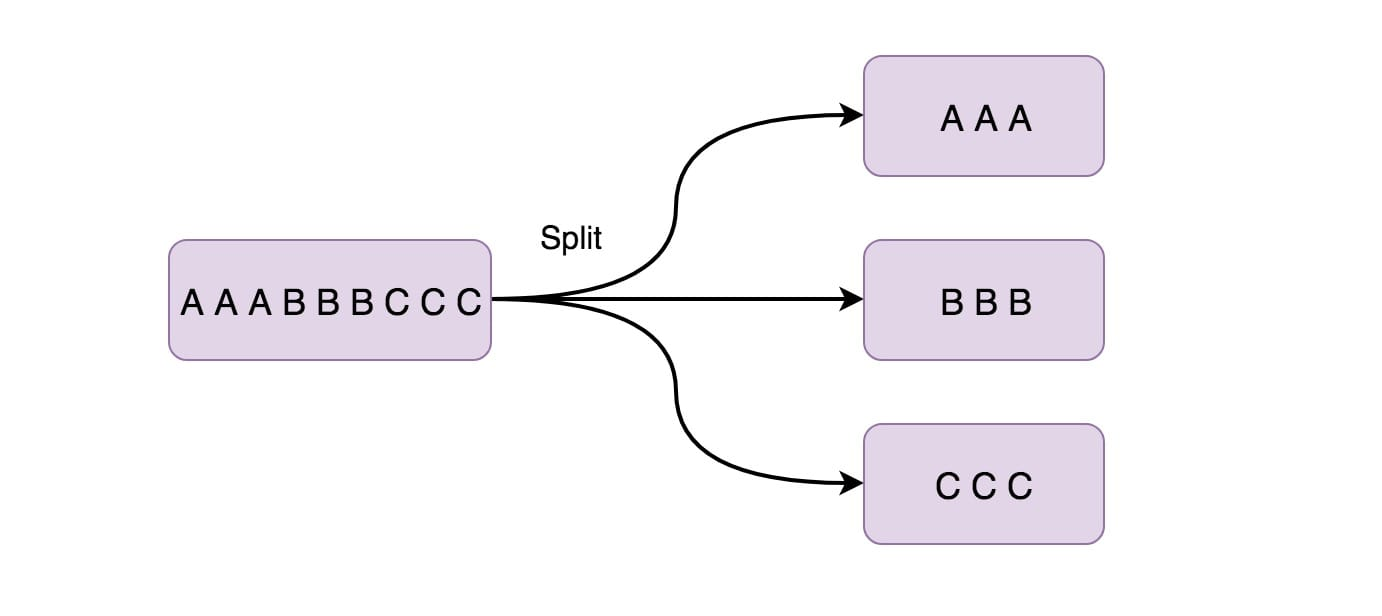
此功能根据条件将流拆分为两个或多个流。 当你获得混合流然后你可能希望单独处理每个数据流时,可以使用此方法。
SplitStream<Integer> split = inputStream.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
} else {
output.add("odd");
}
return output;
}
});
上面就是将偶数数据流放在 even 中,将奇数数据流放在 odd 中。
11、Select
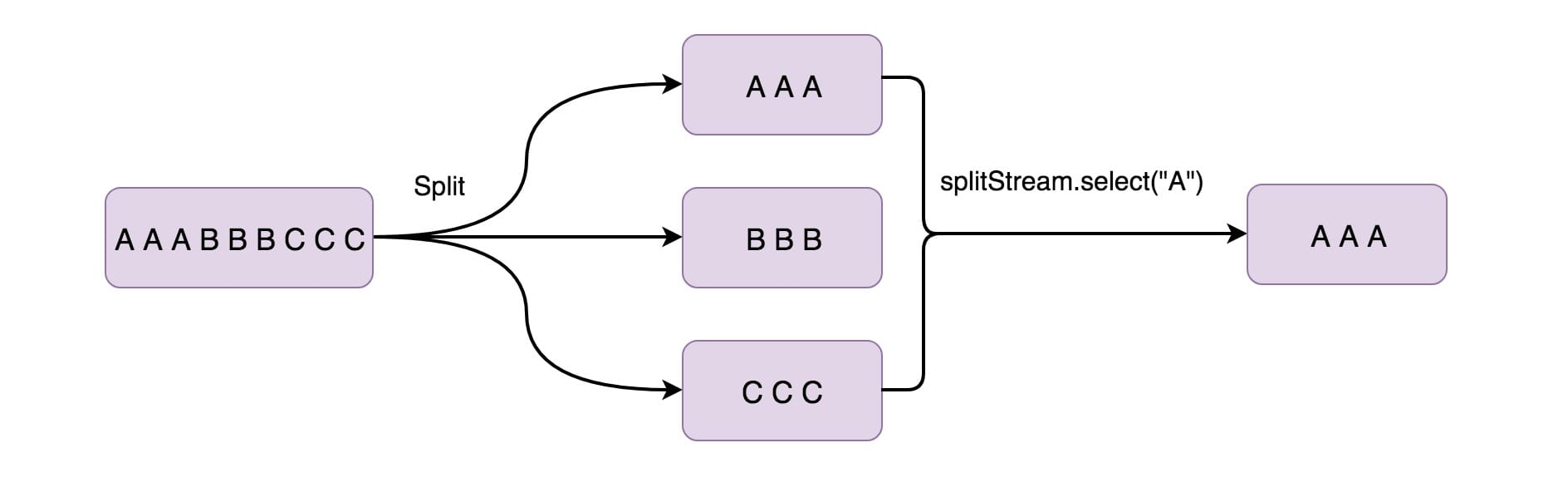
上面用 Split 算子将数据流拆分成两个数据流(奇数、偶数),接下来你可能想从拆分流中选择特定流,那么就得搭配使用 Select 算子(一般这两者都是搭配在一起使用的),
SplitStream<Integer> split;
DataStream<Integer> even = split.select("even");
DataStream<Integer> odd = split.select("odd");
DataStream<Integer> all = split.select("even","odd");
