Flink WordCount、打开Flink的日志输出、Spark WordCount 和 Flink WordCount 的运行流程对比
目录
Flink WordCount
导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.11.2</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.12</scala.version>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
WordCount 代码
package com.shujia.flink.core
// **这里很重要,有的时候这边不是 _ 程序会报错
import org.apache.flink.streaming.api.scala._
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建flink的运行环境
* 是flink程序的入口
* StreamExecutionEnvironment -- 流处理的执行环境,导包的时候有两个包可以选择
* org.apache.flink.streaming.api.scala -- 写Scala代码
* org.apache.flink.streaming.api.environment -- 写java代码
*/
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
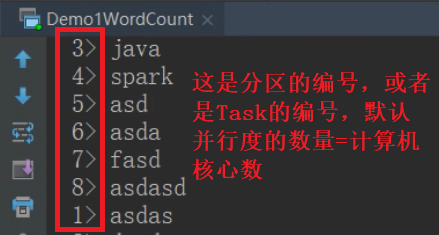
//设置并行度, 默认并行度是计算机核心数
env.setParallelism(2)
/**
* 2、读取数据
*
* DataStream : 相当于spark中DStream
*
* socketTextStream("主机名","端口号")
*
* 开启scoket
* 在Linux的shell中 nc -lk 8888
*
*/
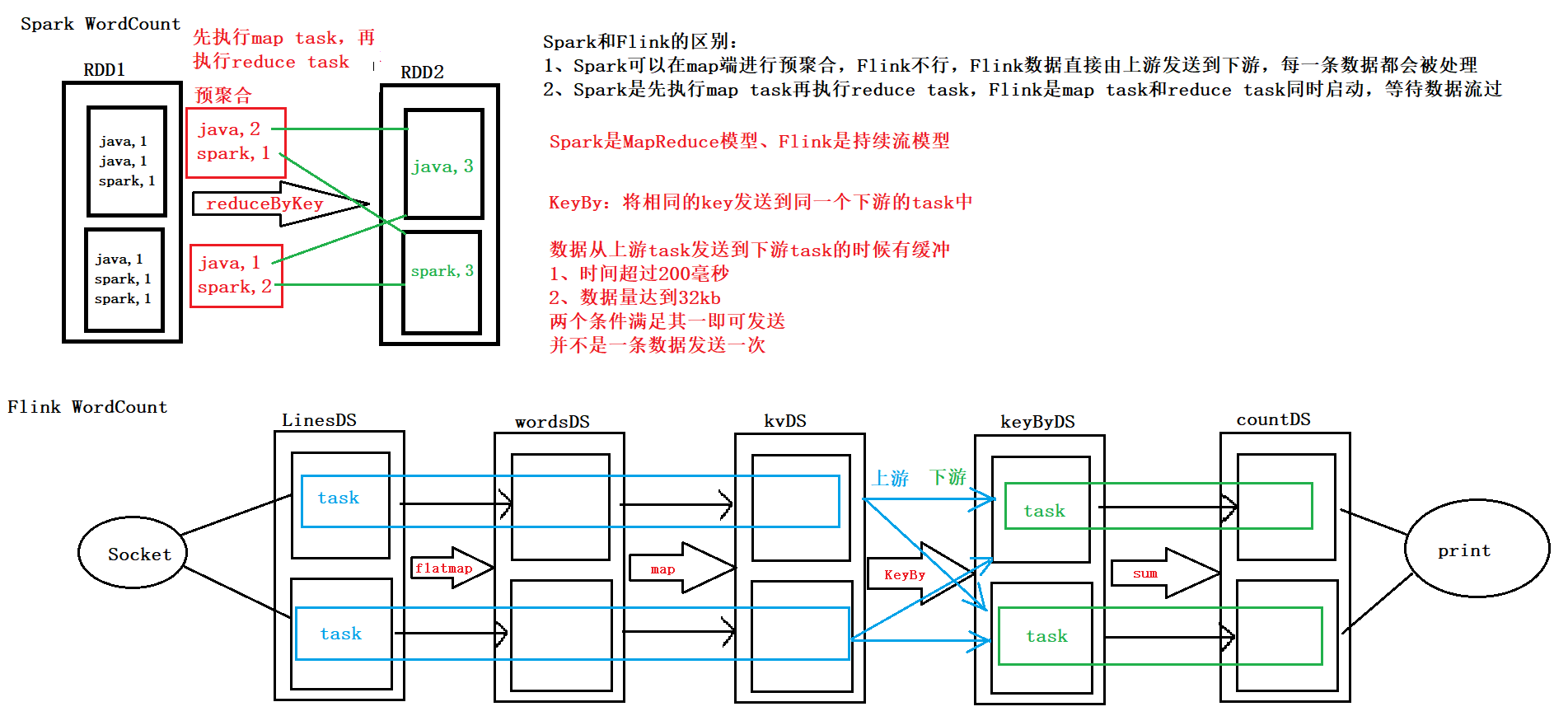
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
//1、将数据展开
val wordsDS: DataStream[String] = linesDS.flatMap(line => line.split(","))
//2、转换成kv格式
val kvDS: DataStream[(String, Int)] = wordsDS.map((_, 1))
//3、按照单词进行分组
val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(kv => kv._1)
/**
*
* flink中的算子本身就是有状态的算子,
*
*/
//4、统计数量 sum():对value进行求和, 指定下标进行聚合
val countDS: DataStream[(String, Int)] = keyByDS.sum(1)
//打印结果
//在流处理中不是foreach
countDS.print()
/**
* 启动flink程序
* execute("job_name")
*/
env.execute("wordcount")
}
}
Flink默认是不打印日志的
运行图:
打开Flink的日志输出
Flink 的日志多少有点摆设
1、导入log4j的依赖
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
2、将log4j的配置文件放在项目的resources目录下
文件名:
log4j2.properties
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
rootLogger.level=info
rootLogger.appenderRef.console.ref=ConsoleAppender
logger.sink.name=org.apache.flink.walkthrough.common.sink.AlertSink
logger.sink.level=INFO
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
Spark WordCount 和 Flink WordCount 的运行流程对比
缓冲 -- 提高吞吐量
Spark 和 Flink 都是粗粒度的资源调度