Flink简介
Flink
相当于是对spark的一个延伸
我们在学习一个框架的时候,要记住关注GitHub
GitHub: Where the world builds software · GitHub
和这个框架的官网
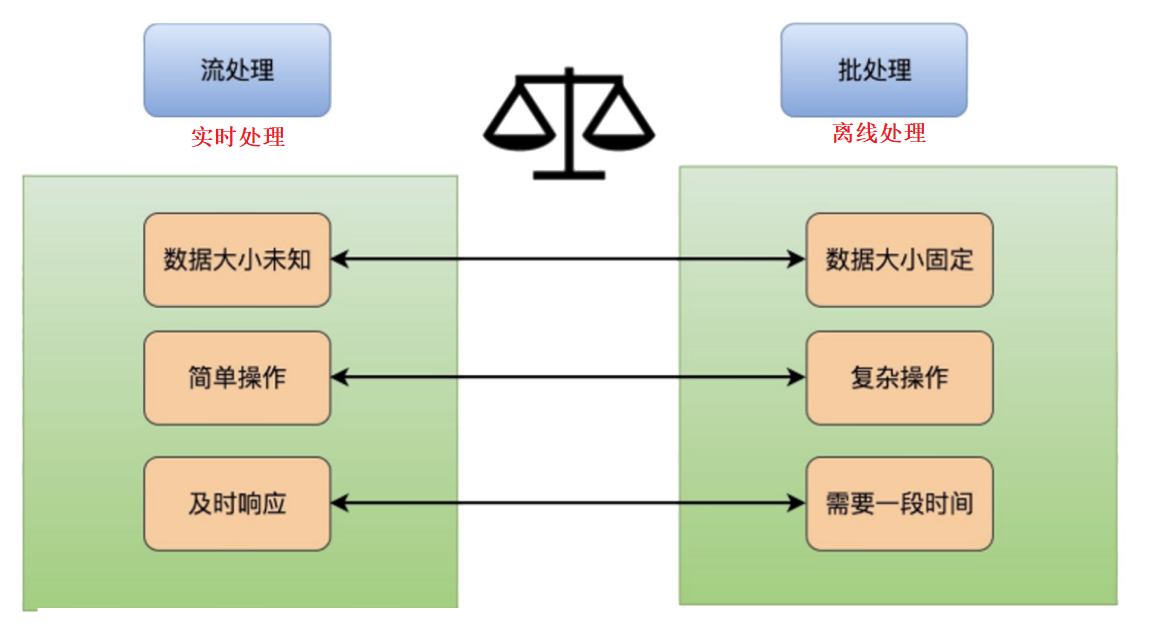
流处理和批处理的区别
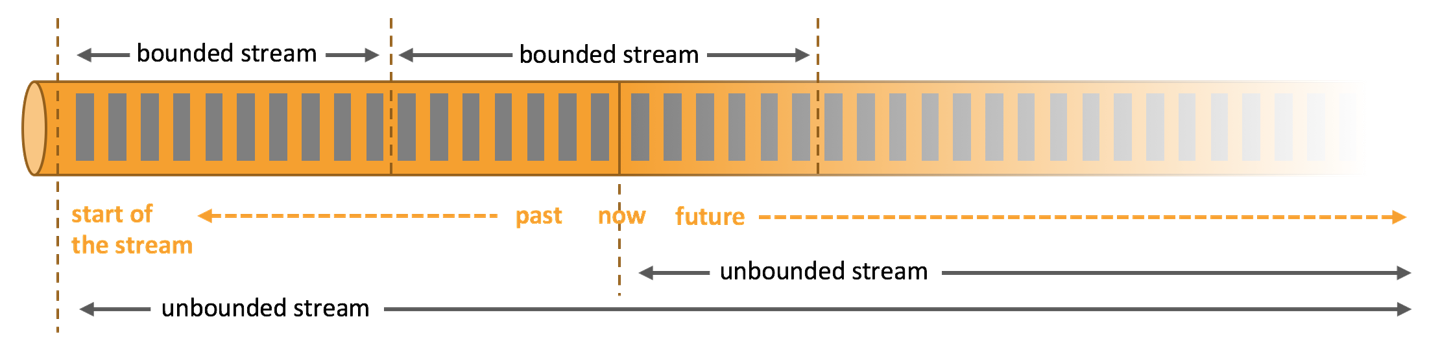
无界流和有界流
Flink 提出无界流和有界流的目的是因为Flink想要实现流批统一
将有界流看做无界流的一个特例
任何类型的数据都是作为事件流产生的。信用卡交易,传感器测量,机器日志或网站或移动应用程序上的用户交互,所有这些数据都作为流生成。
无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件,以便能够推断结果完整性。
有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。
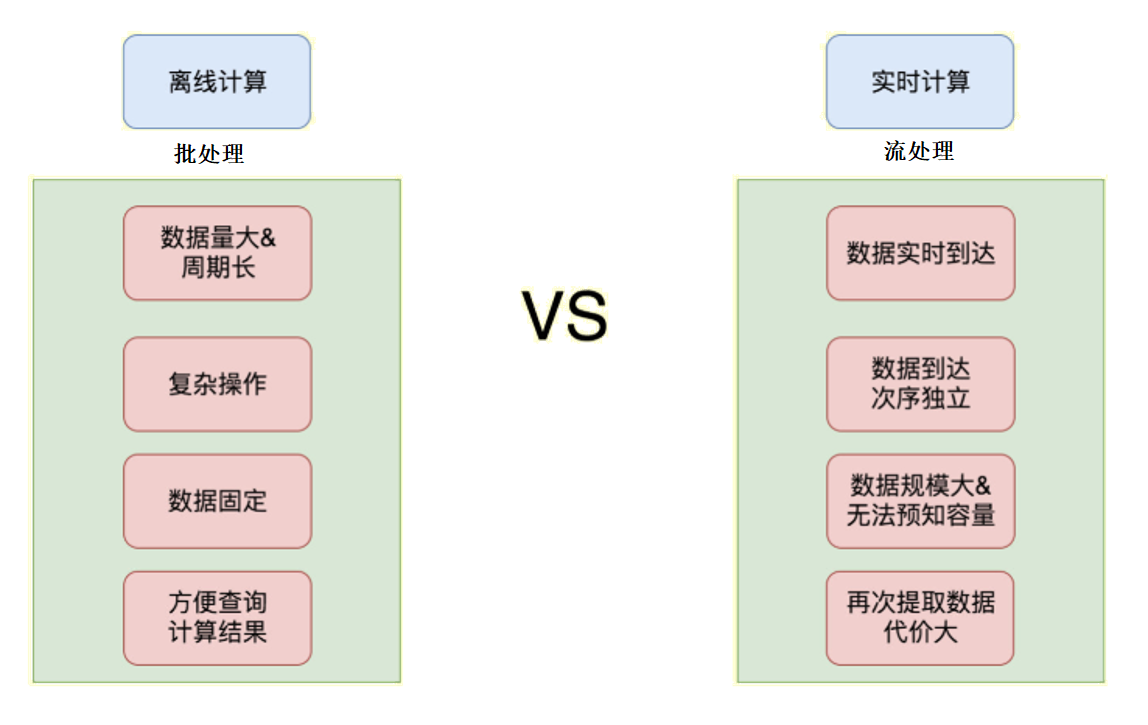
流处理
批处理
流处理和批处理的特点
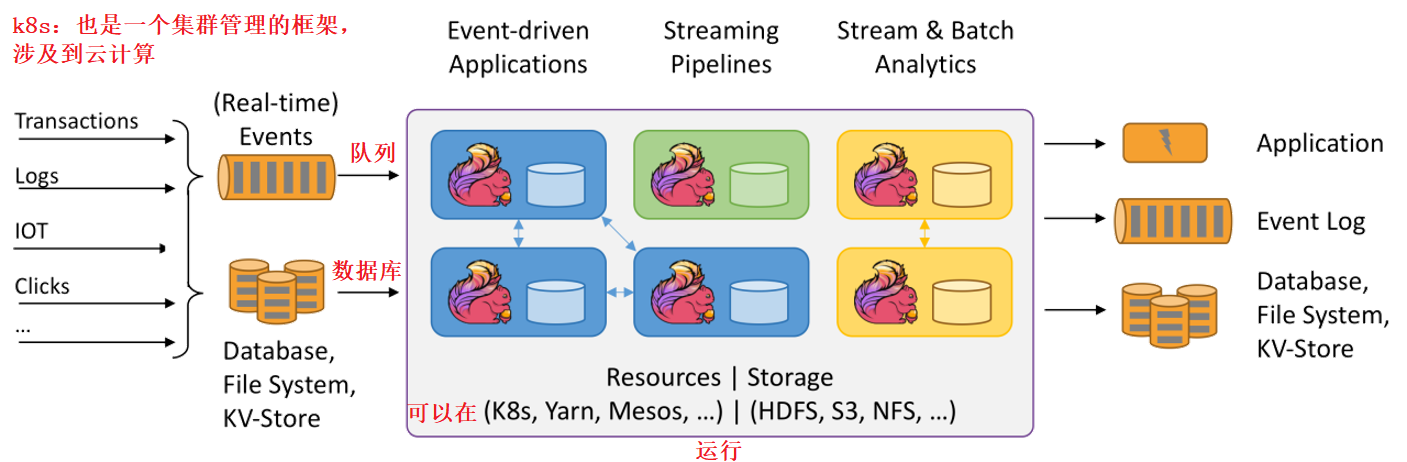
实时计算面临的挑战
1、数据处理唯一性(如何保证数据只处理一次?至少一次?最多一次?)
2、数据处理的及时性(采集的实时数据量太大的话可能会导致短时间内处理不过来,如何保证数据能够及时的处理,不出现数据堆积?)
3、数据处理层和存储层的可扩展性(如何根据采集的实时数据量的大小提供动态扩缩容?)
4、数据处理层和存储层的容错性(如何保证数据处理层和存储层高可用,出现故障时数据处理层和存储层服务依旧可用?)
什么是Flink?
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态(之前计算的结果)计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
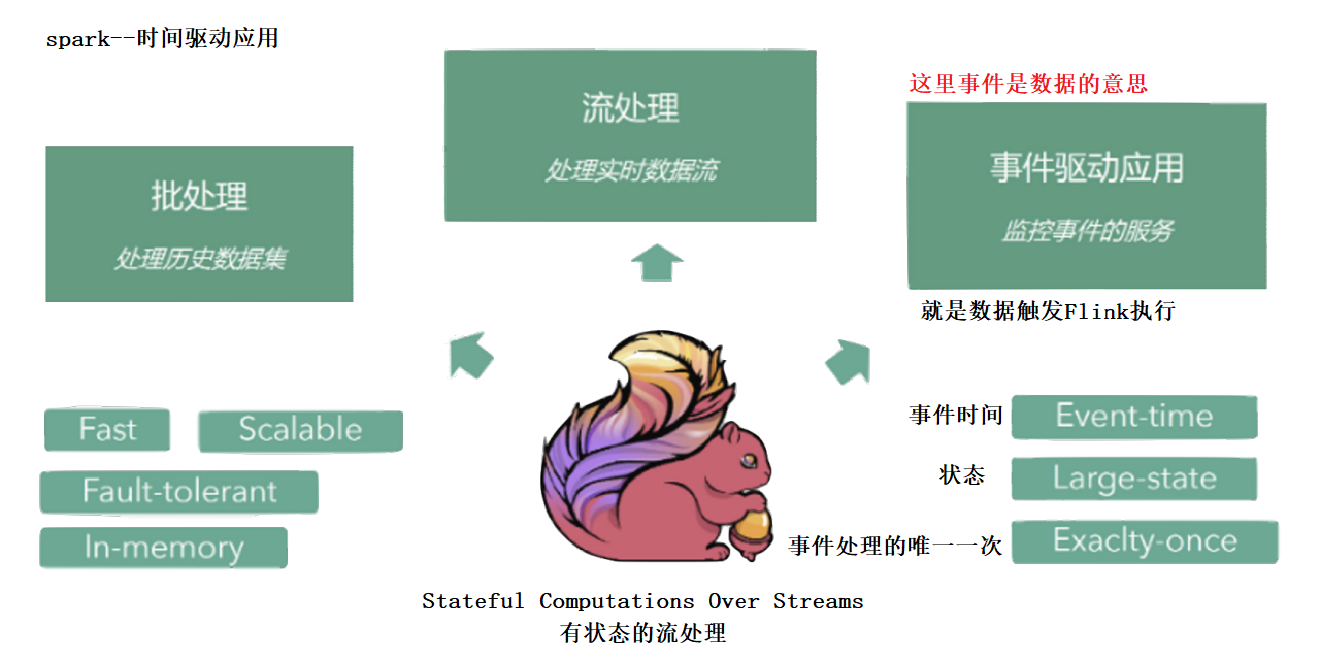
Flink的特点
1、支持高吞吐、低延迟、高性能的流处理
2、支持带有事件时间的窗口(Window)操作
滑动窗口和滚动窗口
3、支持有状态计算的Exactly-once语义
4、支持高度灵活的窗口(Window)操作,支持基于time(时间窗口)、count(统计窗口)、session(会话窗口),以及data-driven的窗口操作
5、支持具有反压功能的持续流模型
反压:为了缓解Flink处理数据的压力,减少数据拉取的速度,防止任务失败
6、支持基于轻量级分布式快照(Snapshot)实现的容错
7、一个运行时同时支持Batch on Streaming处理和Streaming处理
8、Flink在JVM内部实现了自己的内存管理,避免了出现oom
9、支持迭代计算
10、支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
Blink
仅了解
Blink 是阿里云基于Flink开发的一个分支.
在Flink1.9中已经将大部分Blink功能合并到Flink.
Blink 在 TPC-DS 上和 Spark 相比有着非常明显的性能优势,而且这种性能优势随着数据量的增加而变得越来越大。在实际的场景这种优势已经超过 Spark 三倍,在流计算性能上我们也取得了类似的提升。我们线上的很多典型作业,性能是原来的 3 到 5 倍。在有数据倾斜的场景,以及若干比较有挑战的 TPC-H query,流计算性能甚至得到了数十倍的提升。
Flink技术栈
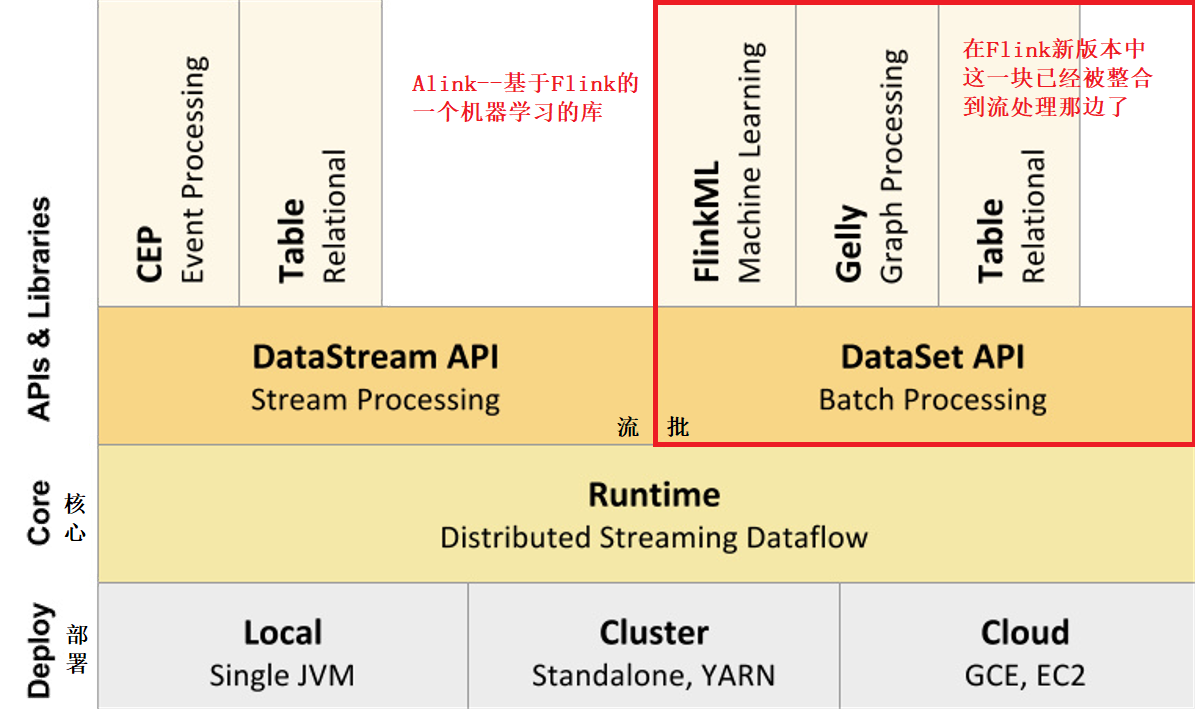
Flink APIs
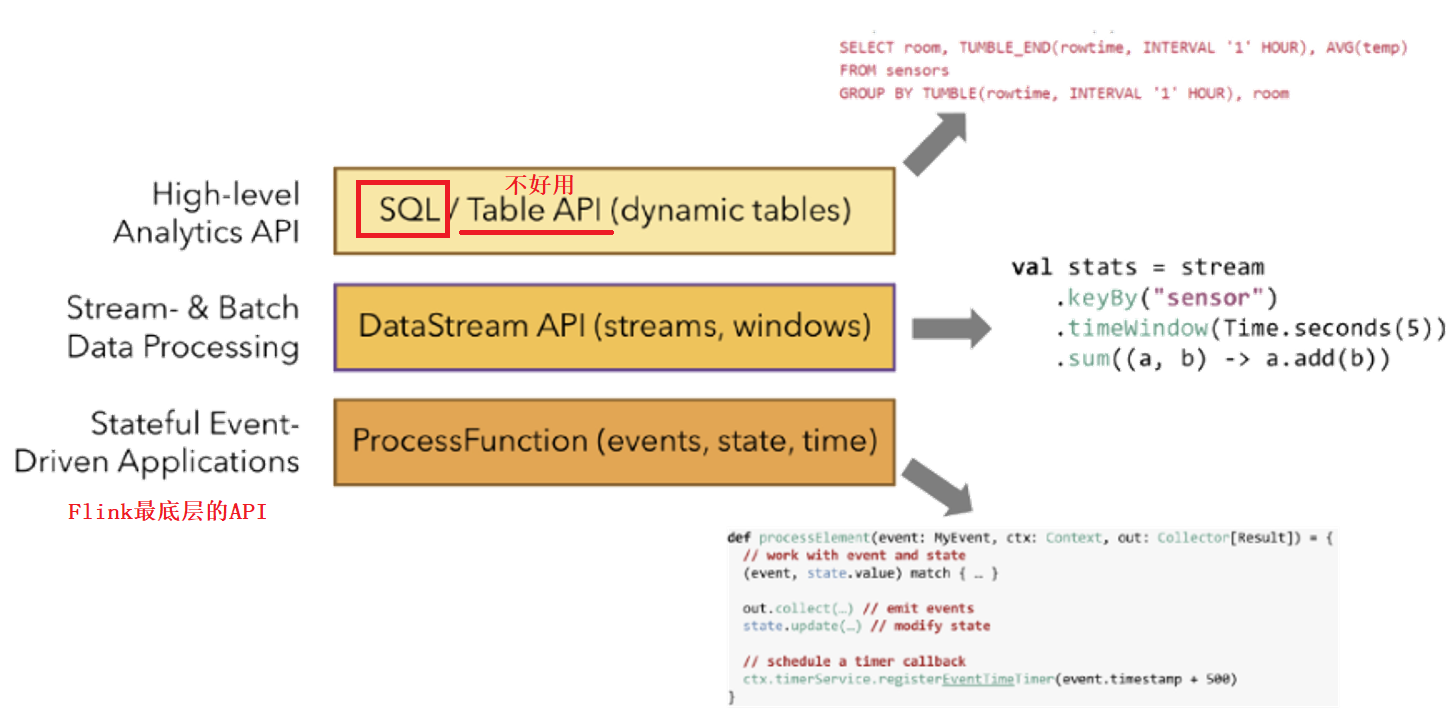
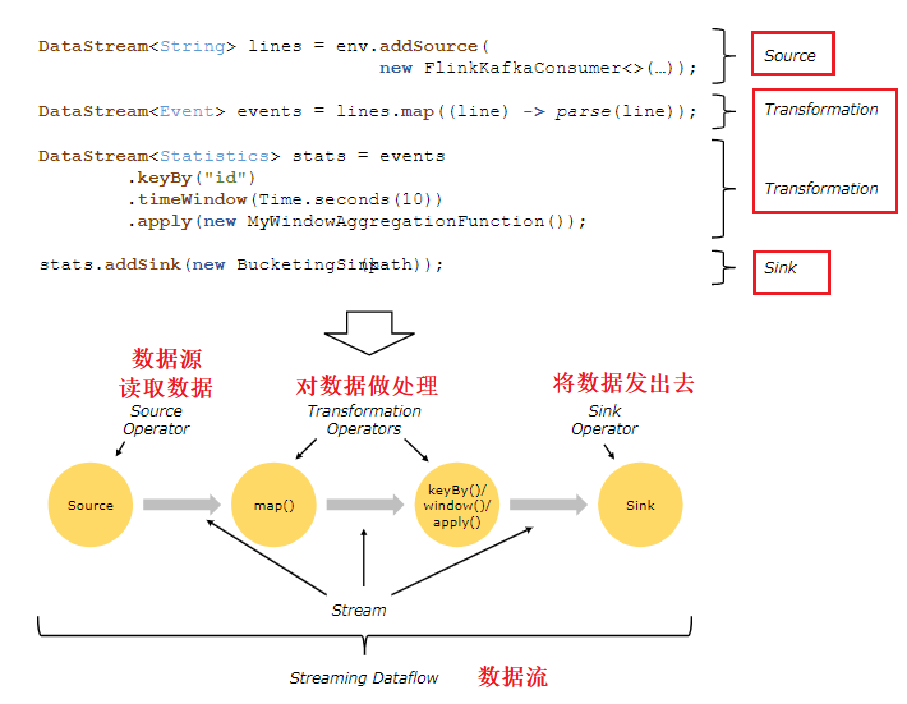
数据流编程模型
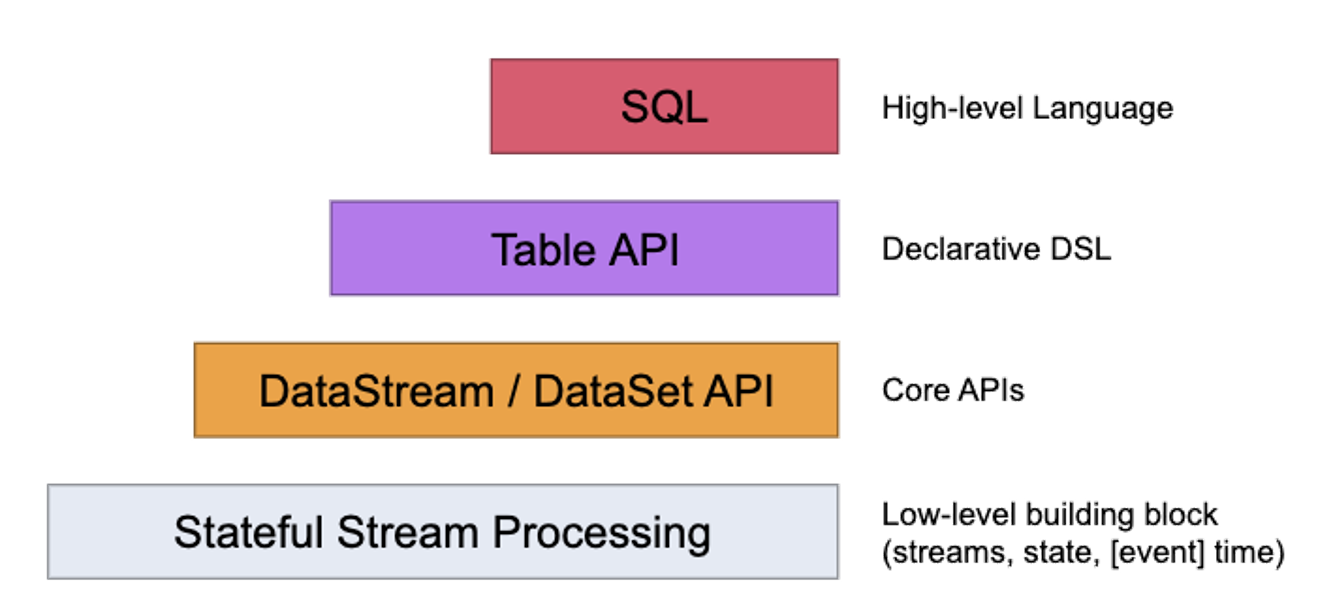
Flink代码结构