spark 调优、spark 代码的优化
spark 调优
三个方面:
代码的优化
参数的优化
数据倾斜的优化
spark 代码的优化
加粗的为重点
1、避免创建重复的RDD
2、尽可能复用同一个RDD
3、对多次使用的RDD进行持久化
4、尽量避免使用shuffle类算子
5、使用map-side预聚合的shuffle操作
6、使用高性能的算子
7、广播大变量
8、使用Kryo优化序列化性能
Kryo-- 对数据压缩的工具库
9、优化数据结构
10、使用高性能的库fastutil
fastutil库 : 针对不同类型的集合做了优化的库
对多次使用的RDD进行持久化
如何选择一种最合适的持久化策略
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大, 可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传 送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用 MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上, 如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是 MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写 ,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
使用高性能的算子
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map Transformation算子
使用foreachPartitions替代foreach Action算子
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操作代码
repartition:coalesce(numPartitions,true) 增多分区使用这个
coalesce(numPartitions,false) 减少分区没有shuffle只是合并 partition
使用foreachPartitions替代foreach Action算子
package com.shujia.opt
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1ForeachPartition {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("partition")
val sc = new SparkContext(conf)
val studentRDD: RDD[String] = sc.textFile("data/stu")
/**
* 1、将创建链接放在foreach里面,每一条数据都会创建一个链接,需要创建很多链接,效率低,而且会导致mysql链接不够
* 2、将创建链接放在Driver端,在Executor不能使用这个链接,网络链接不能在网络中传输(不能序列化)
*/
/**
* 将rdd的数据保存到mysql中
* ?useUnicode=true&characterEncoding=utf-8 -- 指定编码格式的参数
*/
/* studentRDD.foreach(line => {
//写jdbc代码
Class.forName("com.mysql.jdbc.Driver")
//1、创建链接
val con: Connection = DriverManager.getConnection("jdbc:mysql://master:3306/bigdata?useUnicode=true&characterEncoding=utf-8", "root", "123456")
//编写sql
val stat: PreparedStatement = con.prepareStatement("insert into student(id,name,age,gender,clazz) values(?,?,?,?,?)")
val split: Array[String] = line.split(",")
//设置列值
stat.setString(1, split(0))
stat.setString(2, split(1))
stat.setInt(3, split(2).toInt)
stat.setString(4, split(3))
stat.setString(5, split(4))
//执行插入
stat.execute()
})*/
/**
* foreachPartition: 一次传进去一个分区的数据
* 为每一个分区创建一个链接
*
* 当我们将rdd的数据写入到外部数据库中的时候需要使用foreachPartition
*
*/
studentRDD.foreachPartition(iter => {
println("创建链接")
Class.forName("com.mysql.jdbc.Driver")
//1、创建链接
val con: Connection = DriverManager.getConnection("jdbc:mysql://master:3306/bigdata?useUnicode=true&characterEncoding=utf-8", "root", "123456")
//这里的foreach是Scala中迭代器的一个方法
iter.foreach(line => {
//编写sql
val stat: PreparedStatement = con.prepareStatement("insert into student(id,name,age,gender,clazz) values(?,?,?,?,?)")
val split: Array[String] = line.split(",")
//设置列值
stat.setString(1, split(0))
stat.setString(2, split(1))
stat.setInt(3, split(2).toInt)
stat.setString(4, split(3))
stat.setString(5, split(4))
//执行插入
stat.execute()
})
})
}
}
重分区
package com.shujia.opt
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo2RePartition {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local[8]")
.setAppName("partition")
val sc = new SparkContext(conf)
/**
* 读取hdfs文件得到的rdd分区数由block决定
*/
val studentRDD: RDD[String] = sc.textFile("data/students.txt")
println(s"studentRDD分区数:${studentRDD.getNumPartitions}")
/**
* 在使用shuffle类算子的时候可以改变分区数
*
*/
/**
* repartition: 修改rdd的分区数,没有具体代码逻辑
* repartition会产生shuffle
* repartition其中只需要传入指定的分区数
*/
//repartition = coalesce(numPartitions, shuffle = true)
val rePartitionRDD: RDD[String] = studentRDD.repartition(10)
println(s"rePartitionRDD分区数:${rePartitionRDD.getNumPartitions}")
/**
* coalesce -- 默认shuffle为false
* coalesce: 指定shuffle为false 只能用于减少分区 -- 一般用于合并小文件
* coalesce: 指定shuffle为true 可以用于增加分区和减少分区 -- 一般用于提高并行度
*/
val coalesceRDD: RDD[String] = rePartitionRDD.coalesce(20, false)
println(s"coalesceRDD分区数:${coalesceRDD.getNumPartitions}")
//产生小文件
val rdd1: RDD[String] = studentRDD.repartition(200)
rdd1.saveAsTextFile("data/partition")
}
}
合并上面产生的小文件
package com.shujia.opt
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo3coalesce {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local[8]")
.setAppName("partition")
val sc = new SparkContext(conf)
/**
* 读取数据的时候合并小文件
*
*/
val rdd1: RDD[String] = sc.textFile("data/partition")
println(s"rdd1分区数:${rdd1.getNumPartitions}")
/**
* 合并小文件
*
*/
val rdd2: RDD[String] = rdd1.coalesce(10)
println(s"rdd2分区数:${rdd2.getNumPartitions}")
rdd2.foreach(println)
}
}
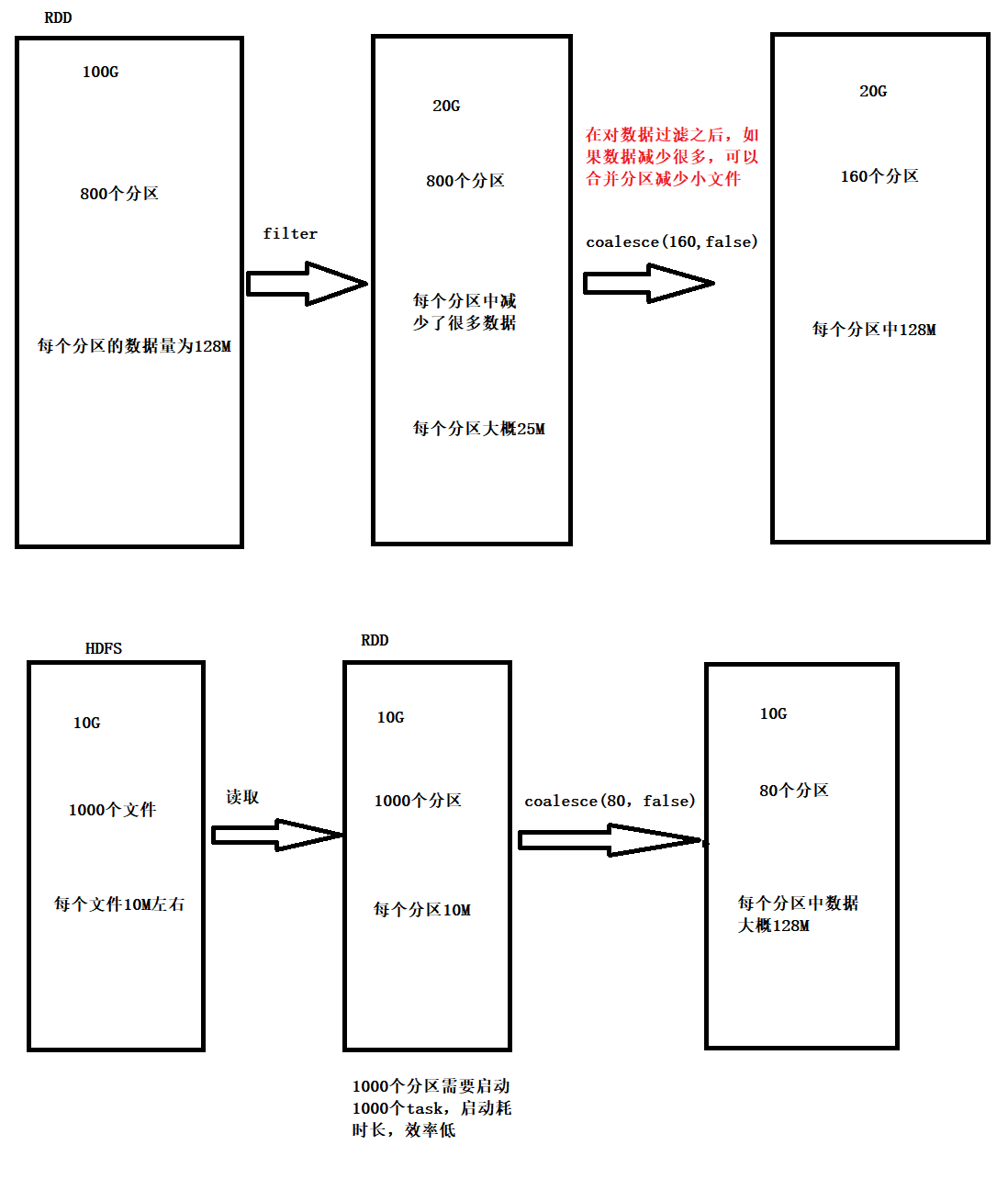
使用filter之后进行coalesce操作
coalesce中指定的分区数需要自己计算
可以通过
hdfs dfs -du -h 文件路径命令查看一下HDFS上的指定的文件到底多大,有多少个小文件
广播大变量
一般大于1G的不能被广播
开发过程中,会遇到需要在算子函数中使用外部变量的场景(尤其是大变量,比如 100M以上的大集合),那么此时就应该使用Spark的广播(Broadcast)功能来提 升性能
函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络 传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如 100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC(垃圾回收),都会极大地影响性能
如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播 后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的 task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低 GC的频率
广播大变量发送方式:Executor一开始并没有广播变量,而是task运行需要用到广播变量,会找executor的blockManager要,bloackManager找Driver里面的 blockManagerMaster要。
使用Kryo优化序列化性能
**在Spark中,主要有三个地方涉及到了序列化: **
在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输
将自定义的类型作为RDD的泛型类型时(比如JavaRDD,SXT是自定义类型),所有自 定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现 Serializable接口。
使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个 partition都序列化成一个大的字节数组。
**Kryo序列化器介绍: **
Spark支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制,速度要快 ,序列化后的数据要更小,大概是Java序列化机制的1/10。所以Kryo序列化优化以后,可 以让网络传输的数据变少;在集群中耗费的内存资源大大减少。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和 反序列化的性能。**Spark默认使用的是Java的序列化机制,也就是 ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。 官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦 **
package com.shujia.opt
import com.shujia.opt.Demo4TestKryo.Student
import com.twitter.chill.Kryo
import org.apache.spark.serializer.KryoRegistrator
class MyRegisterKryo extends KryoRegistrator {
//注册类
override def registerClasses(kryo: Kryo): Unit = {
//注册Student类
//注册之后student类序列化的时候就会使用kryo
//classOf 获取类对象
kryo.register(classOf[Student])
kryo.register(classOf[Int])
kryo.register(classOf[String])
//可以同时注册多个
// kryo.register()
}
}
package com.shujia.opt
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Demo4TestKryo {
/**
* 使用kryo序列化方式代替默认序列化方式(objectOutPutStream/objectInPutStream)
* 性能提高10倍 -- 实际2~3倍左右
*
* spark 三个地方涉及到序列化
*
* 1、算子里面用到可外部变量
* 2、RDD 类型为自定义类型,同时使用checkpoint或者使用shuffle类算子的时候会产生序列化
* 3、cache SER
*/
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("app")
//序列化方式
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//指定注册序列化的类,在自定义类(上面)中注册
.set("spark.kryo.registrator", "com.shujia.opt.MyRegisterKryo")
val sc: SparkContext = new SparkContext(conf)
val data: RDD[String] = sc.textFile("data/students.txt")
/**
* 自定义对象比字符串占用内存更多
* 因为自定义对象含有对象头信息
*
*/
var stuRDD: RDD[Student] = data
.map(_.split(","))
.map(line => Student(line(0), line(1), line(2).toInt, line(3), line(4)))
//对rdd进程缓存, MEMORY_ONLY_SER:会产生序列化
stuRDD.persist(StorageLevel.MEMORY_ONLY_SER)
//shuffle 类算子产生序列化
stuRDD.map(s => (s.id, s)).groupByKey().foreach(println)
stuRDD.map(s => (s.id, s)).groupByKey().foreach(println)
while (true) {
}
}
//样例类
case class Student(id: String, name: String, age: Int, gender: String, clazz: String)
}
优化数据结构
Java中,有三种类型比较耗费内存:
对象,每个Java对象都有对象头、引用等额外的信息,因此比较占用内存空间。
字符串,每个字符串内部都有一个字符数组以及长度等额外信息。
集合类型,比如HashMap、LinkedList等,因为集合类型内部通常会使用一些内部类来 封装集合元素,比如Map.Entry。
Map.Entry -- 用于遍历
因此Spark官方建议,在Spark编码实现中,特别是对于算子函数中的代码,尽量不要使用上述三种数据结构,尽量使用字符串替代对象,使用原始类型(比如 Int、Long)替代字符串,使用数组替代集合类型,这样尽可能地减少内存占用 ,从而降低GC频率,提升性能。
元组 -- 很节省内存空间
使用高性能的库fastutil
因为使用很麻烦,所以很少用
**fastutil介绍: **
fastutil是扩展了Java标准集合框架(Map、List、Set;HashMap、ArrayList、 HashSet)的类库,提供了特殊类型的map、set、list和queue;
fastutil能够提供更小的内存占用,更快的存取速度;我们使用fastutil提供的集合类,来 替代自己平时使用的JDK的原生的Map、List、Set,好处在于,fastutil集合类,可以减 小内存的占用,并且在进行集合的遍历、根据索引(或者key)获取元素的值和设置元素 的值的时候,提供更快的存取速度;
fastutil最新版本要求Java 7以及以上版本;
fastutil的每一种集合类型,都实现了对应的Java中的标准接口(比如fastutil的map,实 现了Java的Map接口),因此可以直接放入已有系统的任何代码中。
fastutil的每一种集合类型,都实现了对应的Java中的标准接口(比如fastutil的 map,实现了Java的Map接口),因此可以直接放入已有系统的任何代码中。
//导入依赖
<dependency>
<groupId>fastutil</groupId>
<artifactId>fastutil</artifactId>
<version>5.0.9</version>
</dependency>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号