DStream、RDD、DataFrame 的相互转换、spark 比 MapReduce 快的原因
目录
DStream、RDD、DataFrame 的相互转换
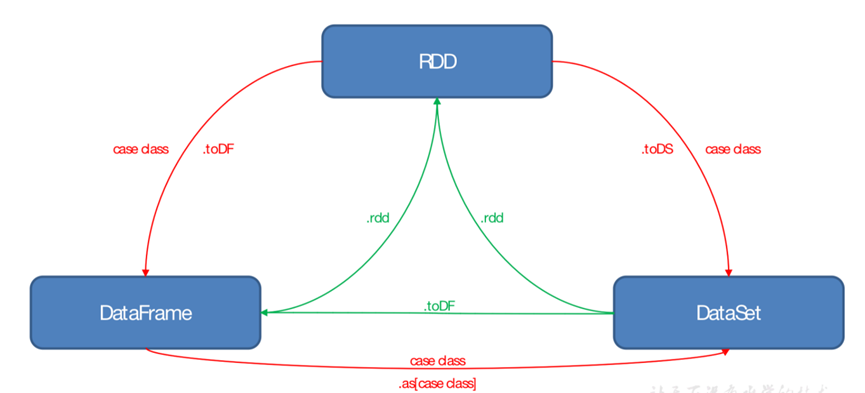
DStream → RDD → DataFrame
package com.shujia.stream
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Duration, Durations, StreamingContext}
object Demo4DStoRDD {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[2]")
.appName("stream")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
//需要加上隐式转换 -- RDD → DataFrame
import spark.implicits._
val sc: SparkContext = spark.sparkContext
val ssc = new StreamingContext(sc, Durations.seconds(5))
val linesDS: ReceiverInputDStream[String] = ssc.socketTextStream("master", 8888)
/**
* DStream 底层是不断重复计算的rdd,
* 可以将DStream转换成RDD来使用
*
* foreachRDD相当于一个循环,每隔5秒执行一次,rdd的数据是当前batch接收到的数据
*
*/
linesDS.foreachRDD((rdd: RDD[String]) => {
/*val kvRDD: RDD[(String, Int)] = rdd.flatMap(_.split(",")).map((_, 1))
val countRDD: RDD[(String, Int)] = kvRDD.reduceByKey(_ + _)
countRDD.foreach(println)*/
/**
* RDD可以转换成DF
*
*/
val linesDF: DataFrame = rdd.toDF("line")
//注册一张表
linesDF.createOrReplaceTempView("lines")
val countDF: DataFrame = spark.sql(
"""
|select word,count(1) as c from (
|select explode(split(line,',')) as word from lines
|) as a group by word
|
""".stripMargin)
countDF.show()
})
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
RDD → DStream
package com.shujia.stream
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object Demo5RDDtoDS {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local[2]")
.appName("stream")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
import spark.implicits._
val sc: SparkContext = spark.sparkContext
val ssc = new StreamingContext(sc, Durations.seconds(5))
val linesDS: ReceiverInputDStream[String] = ssc.socketTextStream("master", 8888)
/**
* transform:传入一个RDD,返回RDD并将之构建成DStream
*
* 将 DS 转换成rdd之后,rdd没有 有状态算子 ,所以不能进行全局累加
* transform:将 DS 转换成RDD,使用rdd的 API,处理完之后返回一个新的rdd
*
*/
val tfDS: DStream[(String, Int)] = linesDS.transform((rdd: RDD[String]) => {
val countRDD: RDD[(String, Int)] = rdd
.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
//返回一个rdd,得到一个新的DS
countRDD
})
tfDS.print()
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}
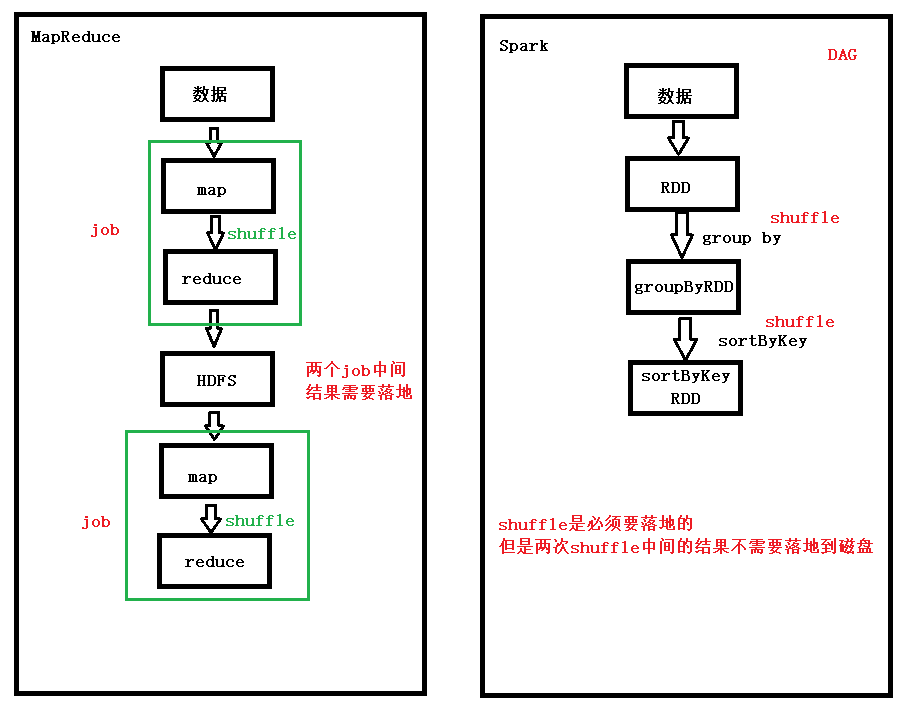
spark 比 MapReduce 快的原因
1、当对同一个rdd多次使用的时候可以将这个rdd缓存起来
2、spark -- 粗粒度的资源调度,MapReduce -- 细粒度的资源调度
3、DAG有向无环图
两次shuffle的中间结果不需要落地
spark没有MapReduce稳定,因为spark用内存较多