Spark Streaming、离线计算、实时计算、实时查询、Spark Streaming 原理、Spark Streaming WordCount、Spark Streaming 架构图
目录
Spark Streaming
spark 中 最重要的就是 spark core 和 spark sql (也就是之前笔记的内容)
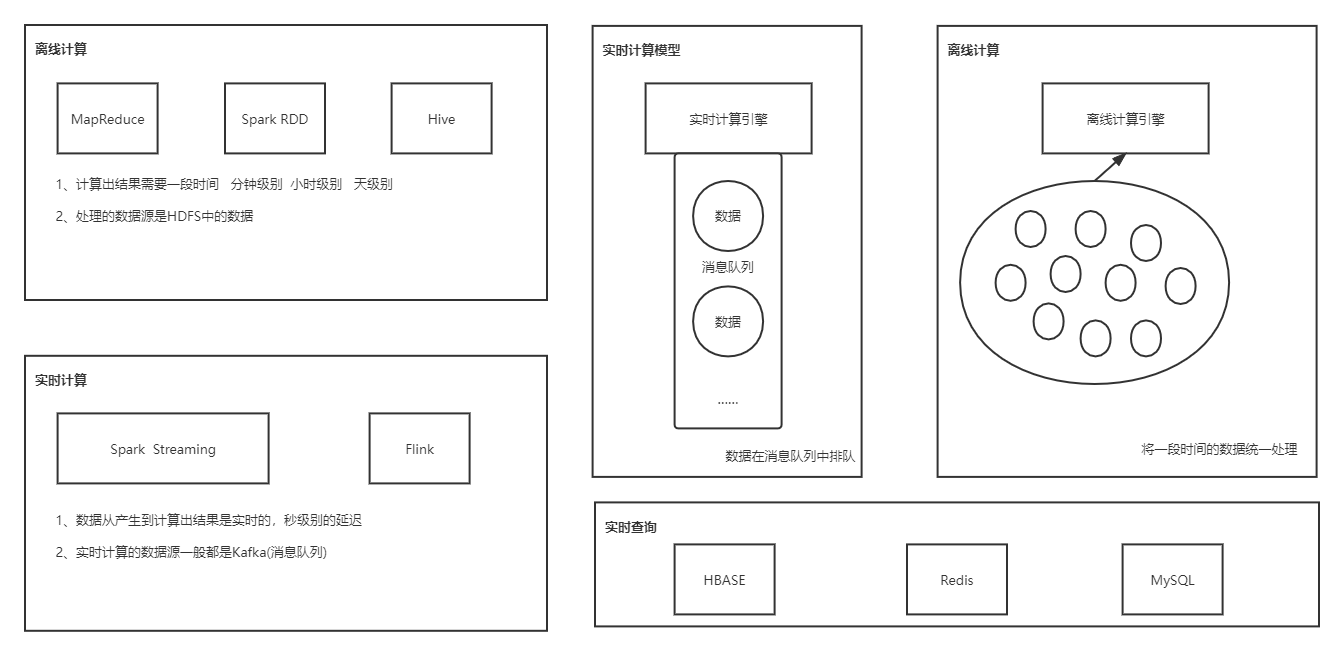
离线计算、实时计算、实时查询
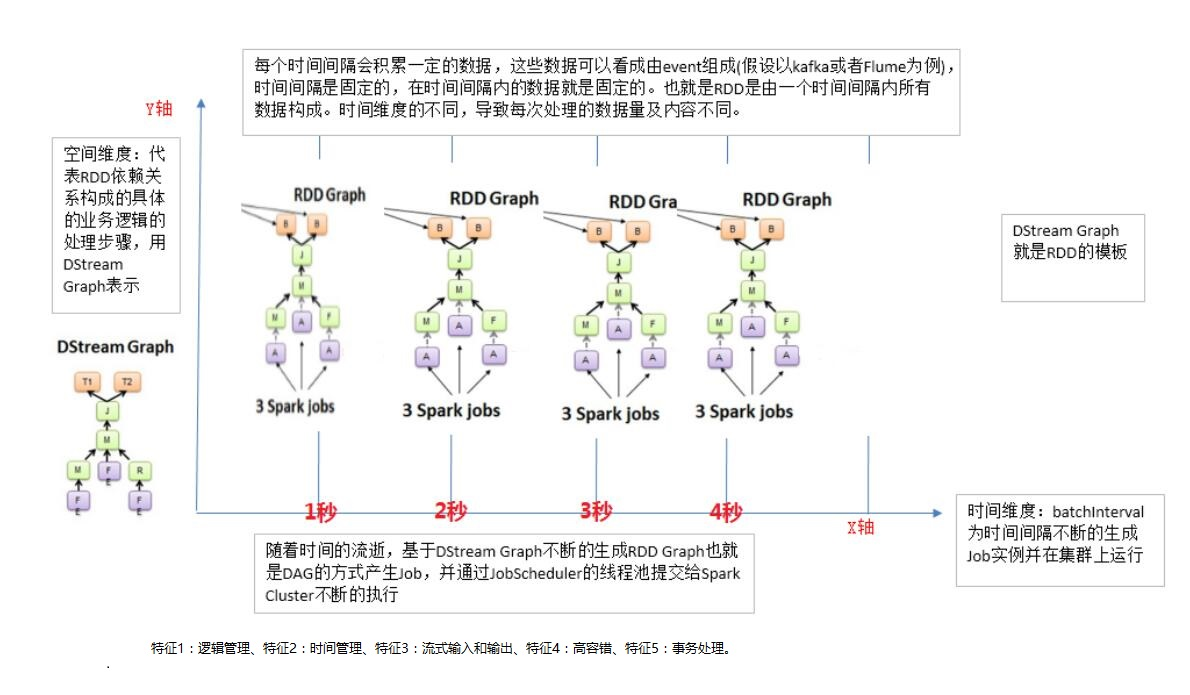
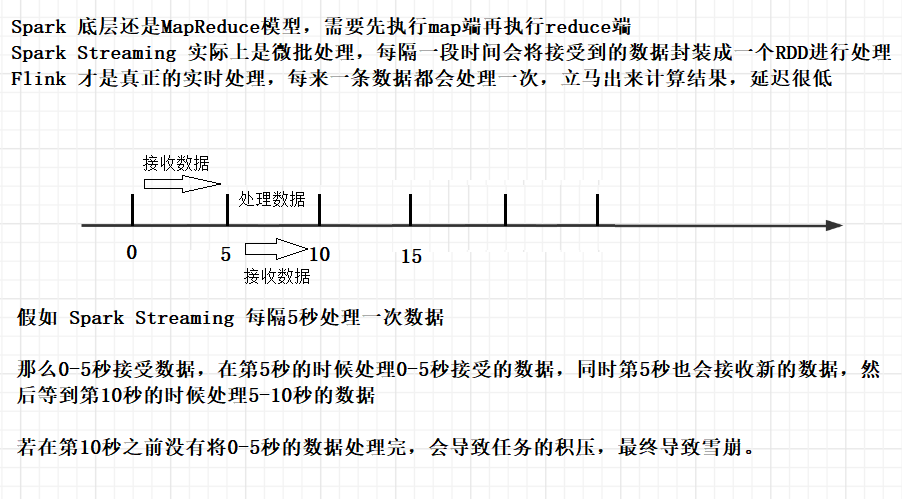
Spark Streaming 原理
Spark Streaming WordCount
1、导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.5</version>
</dependency>
以下列出 spark 项目 目前所需的所有依赖和插件
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
2、WordCount 示例
package com.shujia.stream
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Duration, Durations, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建 SparkContext
*
*/
val conf: SparkConf = new SparkConf()
//在local后面可以通过[]指定一个参数,指定一个任务运行时使用的CPU核数,不能超过自己电脑的CPU核数
//因为在处理数据的时候还要接收数据,所以这里要指定为 2 才能跑起来
.setMaster("local[2]")
.setAppName("stream")
val sc = new SparkContext(conf)
/**
* 2、创建 SparkStreaming 环境
*
* 需要SparkContext对象+指定batch的间隔时间(多久处理一次)
*
*/
val ssc = new StreamingContext(sc, Durations.seconds(5))
/**
* 实时计算的数据源一般是 Kafka
* 因为目前 Kafka 没有学,所以通过 socket 去模拟实时环境
*
* 读取socket中的数据 -- socketTextStream("主机名","端口号")
*
* 在Linux中启动 socket 服务
* 没有nc命令的话,要yum一个
* yum install nc
* nc -lk 8888
* 之后就可以在Linux的shell中输入数据,然后谁连接了我指定的端口号,谁就能拿到我输入的数据
*
*/
/**
* DStream : Spark Streaming 的编程模型,其底层也是RDD,每隔5秒将数据封装成一个rdd
*/
val lineDS: DStream[String] = ssc.socketTextStream("master", 8888)
/**
* 统计单词的数量
*
*/
val wordsDS: DStream[String] = lineDS.flatMap(line => line.split(","))
val kvDS: DStream[(String, Int)] = wordsDS.map(word => (word, 1))
val countDS: DStream[(String, Int)] = kvDS.reduceByKey(_ + _)
countDS.print()
/**
* 启动Spark Streaming程序
* 这几行代码是必须的,这和RDD中不一样
*/
ssc.start()//启动
ssc.awaitTermination()//等待关闭
ssc.stop()//关闭
}
}
Spark Streaming 架构图