
查看 spark-sql 的 SQL语法树、spark-sql 的优化、整合 hive 之后通过代码操作
查看 spark-sql 的 SQL语法树
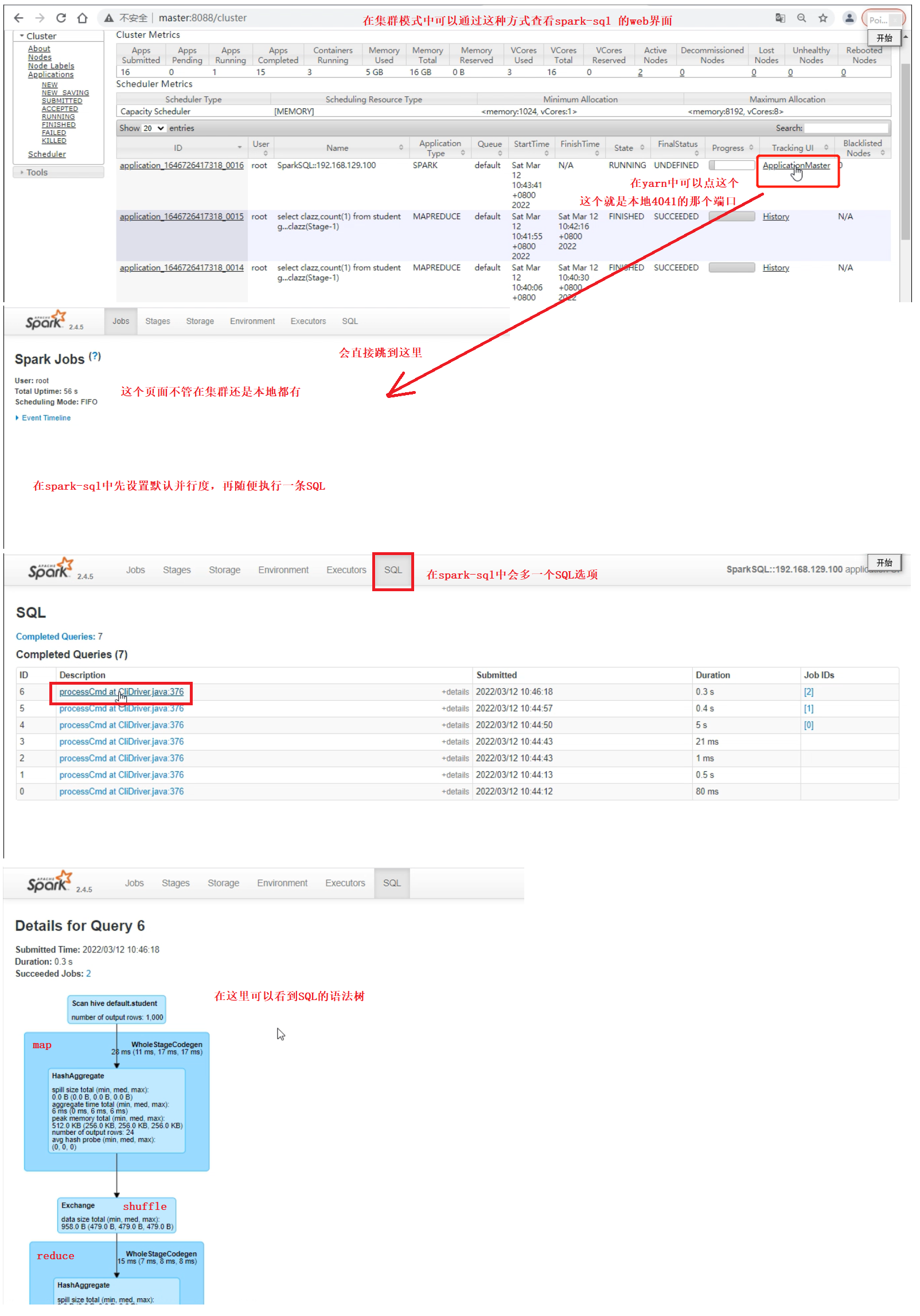
查看 spark-sql 的web界面的一种方式
在通过 spark-sql --master yarn-client 命令进入 spark-sql 的时候
可以在yarn的web界面中通过下图所示的步骤进入spark-sql 的web界面,并查看 spark-sql 的 SQL语法树
spark-sql 的优化
1、缓存
添加缓存
cache table 表名;
删除缓存
uncache table 表名;
2、广播小表 -- 实现mapjoin -- hint
在map端实现表关联,将小表加载到内存,小表的大小不能超过一个Executor的内存的0.6
select /*+broadcast(a)*/ * from
student as a
join
score as b
on a.id=b.student_id
在代码中实现优化
package com.shujia.sql
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo9MapJoin {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("student")
.config("spark.sql.shuffle.partitions", 1)
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
//读取学生表
val student: DataFrame = spark
.read
.format("csv")
.option("sep", ",")
.schema("id STRING,name STRING,age INT,gender STRING, clazz STRING")
.load("data/students.txt")
//读取分数表
val score: DataFrame = spark.read
.format("csv")
.option("sep", ",")
.schema("sId STRING,cId STRING ,sco DOUBLE")
.load("data/score.txt")
/**
* 会有自动的优化
*
* DF实现mapjoin
* //将小表广播实现mapjoin
* .hint("broadcast")
*
*/
val joinDF: DataFrame =
score.join(student.hint("broadcast"), $"sId" === $"id")
joinDF.show()
while (true) {
}
}
}
整合 hive 之后,通过代码操作
通过代码拿hive数据
package com.shujia.sql
import org.apache.spark.sql.{DataFrame, SparkSession}
object Demo10SaprkOnHIve {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("student")
.config("spark.sql.shuffle.partitions", 1)
//代码在本地不能运行,必须打包到集群中运行
.enableHiveSupport() //使用hived的元数据,可以直接在代码中使用hive的表
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
//读取hive中的表
//student -- hive 中的表
//通过 spark.table 直接拿
val student: DataFrame = spark.table("student")
val score: DataFrame = spark.table("score")
student
.join(score, $"id" === $"student_id")
.show(1000)
}
}
spark SQL 是完全兼容 hive SQL 的,但是 hive SQL 不是完全兼容 spark SQL 的

