
spark SQL、Dataframe、Dataframe 和 RDD 的区别、spark SQL WordCount
首先让我们来回顾一下 spark 的生态系统
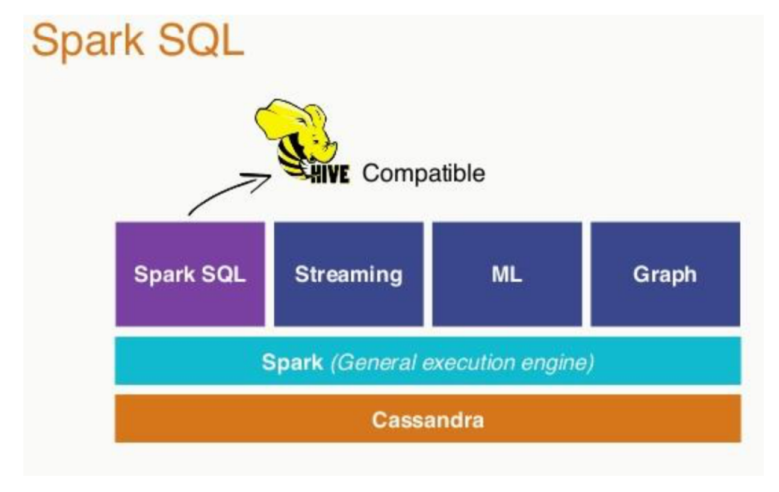
spark SQL
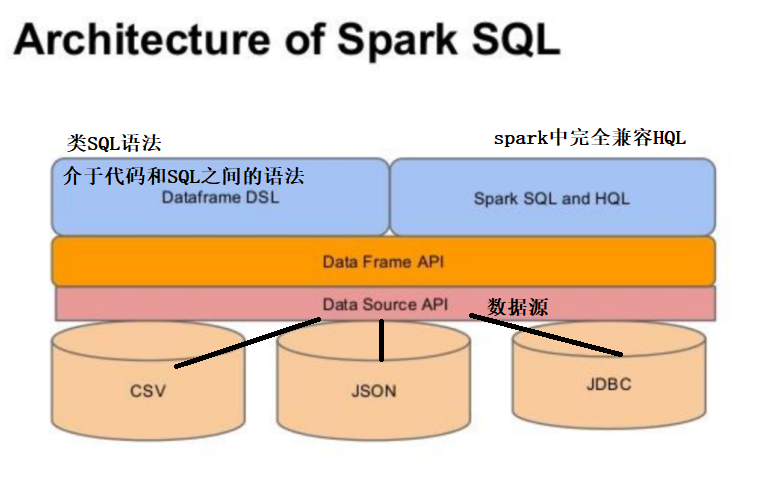
Dataframe
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。同时,与Hive类似,DataFrame也支 持嵌套数据类型(struct、array和map)。从API易用性的角度上看,DataFrame API提供的是 一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的 DataFrame类似,Spark DataFrame很好地继承了传统单机数据分析的开发体验。
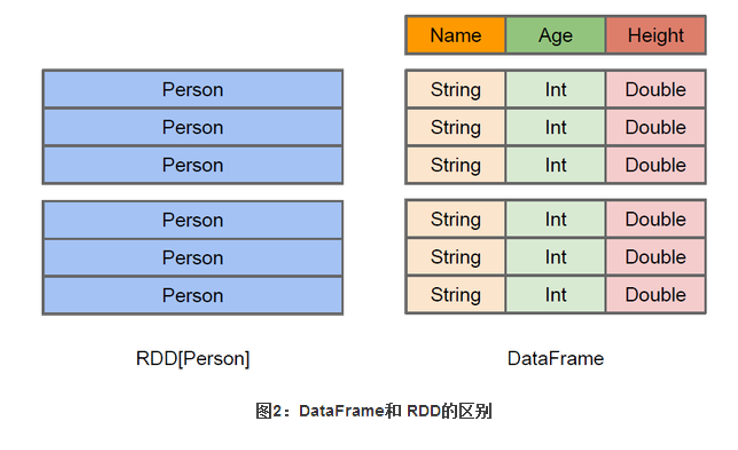
Dataframe 和 RDD 的区别
Dataframe 在 RDD 的基础上增加了列名
spark SQL WordCount
在IDEA写 Spark SQL 之前,我们需要导入依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.5</version> </dependency> 下面是 pom.xml 文件中 spark 需要的所有依赖
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.40</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
WordCount 代码示例
package com.shujia.sql
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 创建SParkSession环境
*
*/
val spark: SparkSession = SparkSession
.builder() // 构建
.appName("sql") // 指定任务名
.master("local") // 指定运行模式
.config("spark.sql.shuffle.partitions", 1) // 设置spark sql shuffle之后的分区数
.getOrCreate() // 获取或者创建
/**
* 1、读取文件,构建Dataframe(DF)
* Dataframe -- 底层还是RDD
* Dataframe 默认 shuffle 之后的分区数是200,所以在上面需要设置一下shuffle之后的分区数
*/
val linesDF: DataFrame = spark
.read
.format("csv") //指定读取文件的格式
.option("sep", "*") //指定分割方式
.schema("line STRING") //指定字段名和字段类型(多个字段之间用,分割)
.load("data/words.txt") //指定读取的路径
/**
* 如果要写sql 需要先注册一张表
*
*/
//将DF 注册成一张临时视图
linesDF.createOrReplaceTempView("lines")
/**
* 通过spark写sql, 统计单词的数量
*
*/
val countDF: DataFrame = spark.sql(
"""
|select
|word,count(1) as c
|from (
|select
|explode(split(line,',')) as word
|from
|lines) as a
|group by word
|
""".stripMargin)
//show 相当于一个action算子
//countDF.show()
/**
* 使用 DSL 统计单词的数量
*
* DSL 是一种类 sql 的代码
*
* $ 获取列的对象
*/
//导入spark sql 所有的函数
import org.apache.spark.sql.functions._
//导入隐式转换 -- 使用 $
import spark.implicits._
// groupBy 中 Column* 表示可变参数
val dslCountDF: DataFrame = linesDF
.select(explode(split($"line", ",")) as "word") //将一行数据转换成多行
.groupBy($"word") //按照单词分组, 会产生shuffle
.count() //统计单词的数量
dslCountDF.show()
/**
* 保存数据,相当于action算子
*
*/
dslCountDF
.write //保存数据
.format("csv") //指定保存数据的格式
.mode(SaveMode.Overwrite) //指定保存模式
.save("data/sql_count") // 指定路径
}
}

