
PageRank、图计算、图存储的两种方式
PageRank
网页排名算法
什么是PageRank?
PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。
是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的。
PageRank实现了将链接价值概念作为排名因素。
如果一个网页可以被很多网页通过链接跳转过来,那么说明这个网页比较重要
算法原理
入链 ====投票
PageRank让链接来“投票“,到一个页面的超链接相当于对该页投一票
入链数量
如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
不能只看数量,因为可以做一堆网页去指向该网页,去刷PageRank
入链质量
指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
网络上各个页面的连接图
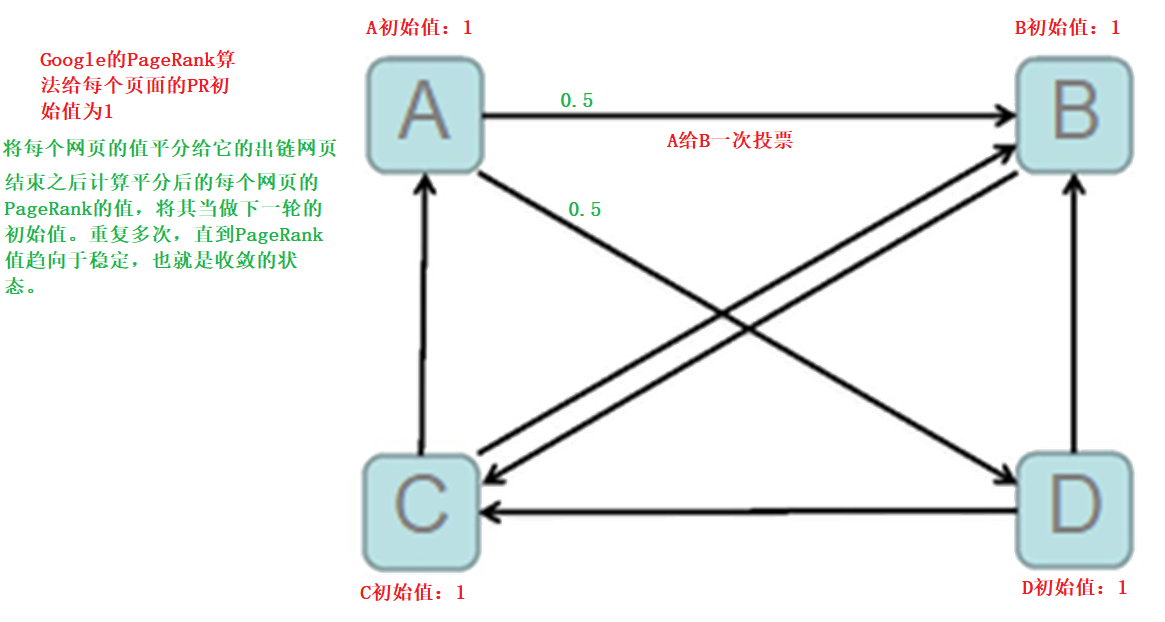
计算过程
初始值
每个页面设置相同的PR值
Google的PageRank算法给每个页面的PR初始值为1。
迭代递归计算(收敛)
Google不断的重复计算每个页面的PageRank。那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。
在具体企业应用中怎么样确定收敛标准?
每个页面的PR值和上一次计算的PR相等
设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小于该标准时,则收敛。
设定一个百分比(99%),当99%的页面和上一次计算的PR相等
图存储的两种方式
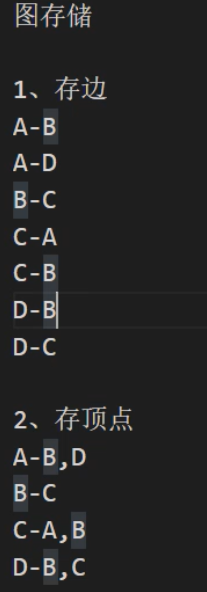
代码实现
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo26PageRank {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo23Cache")
val sc = new SparkContext(conf)
//1、读取原始数据
//A-B,D
//B-C
//C-A,B
//D-b,C
val dataRDD: RDD[String] = sc.textFile("data/pagerank.txt")
//2、拆分数据
val pageLinkRDD: RDD[(String, List[String])] = dataRDD.map(line => {
val split: Array[String] = line.split("-")
//当前网页
val page: String = split(0)
//出链列表
val linkList: List[String] = split(1).split(",").toList
(page, linkList)
})
//对多次使用的rdd进行缓存 -- 优化
pageLinkRDD.cache()
/**
* 计算pagerank
*
*/
//1、给每一个网页一个初始的pr值 1
var pagerankRDD: RDD[(String, List[String], Double)] = pageLinkRDD.map {
case (page: String, linkList: List[String]) =>
(page, linkList, 1.0)
}
var flag = true // 为了让循环有一个出口,这边做一个标记
while (flag) { // 循环
//2、将初始的pr值分配给出链列表
val avgPrRDD: RDD[List[(String, Double)]] = pagerankRDD.map {
case (page: String, linkList: List[String], pr: Double) =>
//将pr等分
val avgPr: Double = pr / linkList.length
linkList.map(p => (p, avgPr))
}
//展开数据
val pageKVRDD: RDD[(String, Double)] = avgPrRDD.flatMap(list => list)
//累加每个网页分到的pr值
val currPrRDD: RDD[(String, Double)] = pageKVRDD.reduceByKey(_ + _)
//关联出链列表
val joinRDD: RDD[(String, (Double, List[String]))] = currPrRDD.join(pageLinkRDD)
//整理数据
val resultRDD: RDD[(String, List[String], Double)] = joinRDD.map {
case (page: String, (pr: Double, linkList: List[String])) =>
(page, linkList, pr)
}
/**
* 计算收敛条件
*
*/
//计算网页新的pr值和前一次的pr的差值平均值
val kvRDD1: RDD[(String, Double)] = resultRDD.map(i => (i._1, i._3))
val kvRDD2: RDD[(String, Double)] = pagerankRDD.map(i => (i._1, i._3))
val kvJoinRDD: RDD[(String, (Double, Double))] = kvRDD1.join(kvRDD2)
//计算差值
val chaValueRDD: RDD[Double] = kvJoinRDD.map {
case (_: String, (pr1: Double, pr2: Double)) =>
//差值可能为负数,所以去绝对值
Math.abs(pr1 - pr2)
}
//差值的平均值
val chaAvg: Double = chaValueRDD.sum() / chaValueRDD.count()
//收敛--结束循环的条件
if (chaAvg < 0.001) {
flag = false
}
//切换rdd 下一次计算使用新的pr值进行计算
pagerankRDD = resultRDD
pagerankRDD.foreach(println)
}
}
}
