spark 累加器
package com.shujia.spark
import java.lang
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object Demo24Acc {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo23Cache")
val sc = new SparkContext(conf)
val studentsRDD: RDD[String] = sc.textFile("data/students.txt")
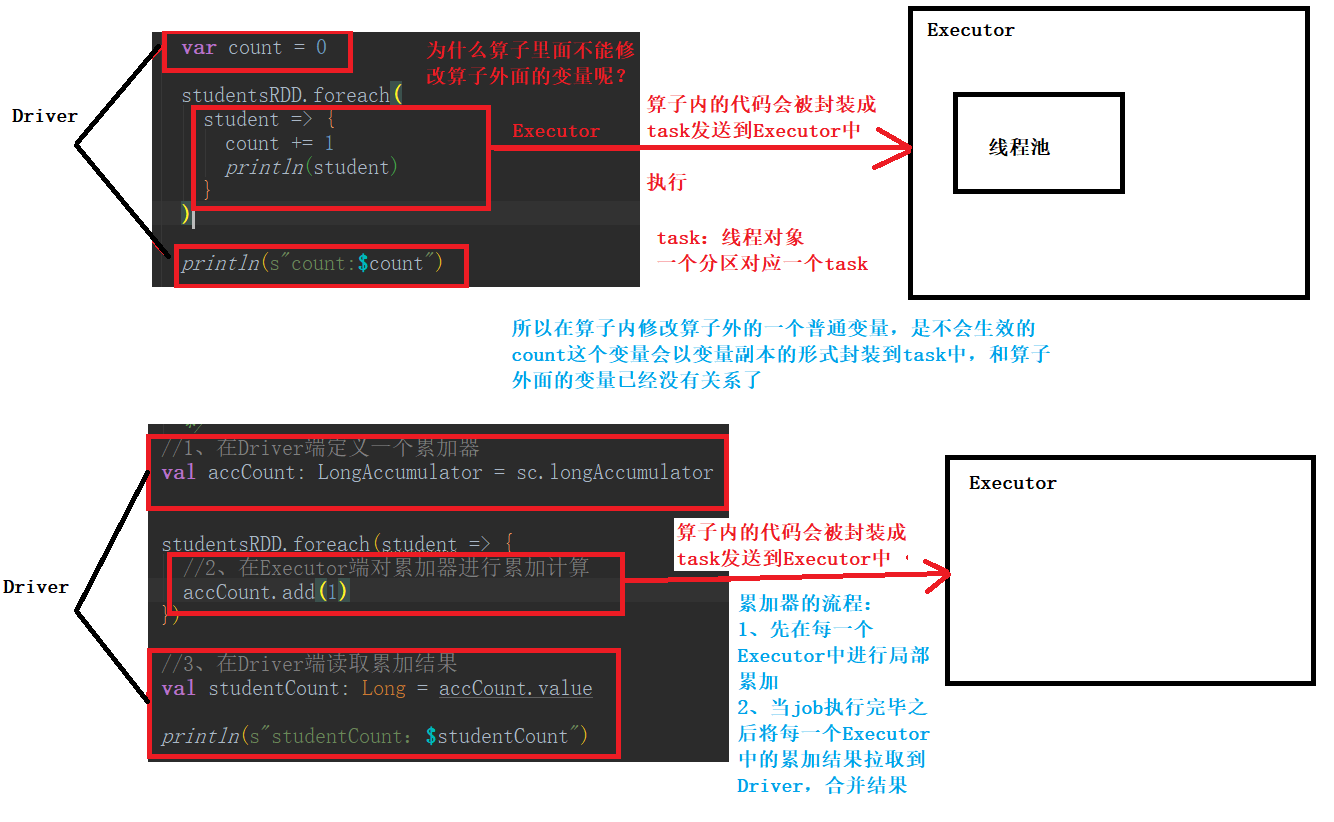
var count = 0
studentsRDD.foreach(
student => {
//在算子内修改算子外的一个变量不会生效
count += 1
println(count) //里面的count是一个变量副本,会生效
println(student) //这里加上一个输出,我们发现代码是运行的,所以下面的count:0并不是代码没有运行
}
)
//为什么呢?
println(s"count:$count") //count:0
/**
* 累加器
*
* 累加器有局限性:仅能做累加、累减
* 因为这是一个并行计算的环境,多个task对同一个数据做修改,易发生线程安全的问题
*/
//1、在Driver端定义一个累加器(这里是Long类型的)
val accCount: LongAccumulator = sc.longAccumulator
studentsRDD.foreach(student => {
//2、在Executor端对累加器进行累加计算
accCount.add(1)
})
//3、在Driver端读取累加结果
val studentCount: Long = accCount.value
println(s"studentCount:$studentCount")
}
}
广播变量
package com.shujia.spark
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo25Bro {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo23Cache")
val sc = new SparkContext(conf)
val studentsRDD: RDD[String] = sc.textFile("data/students.txt")
/**
* 取出集合中的所有学生的信息
*
*/
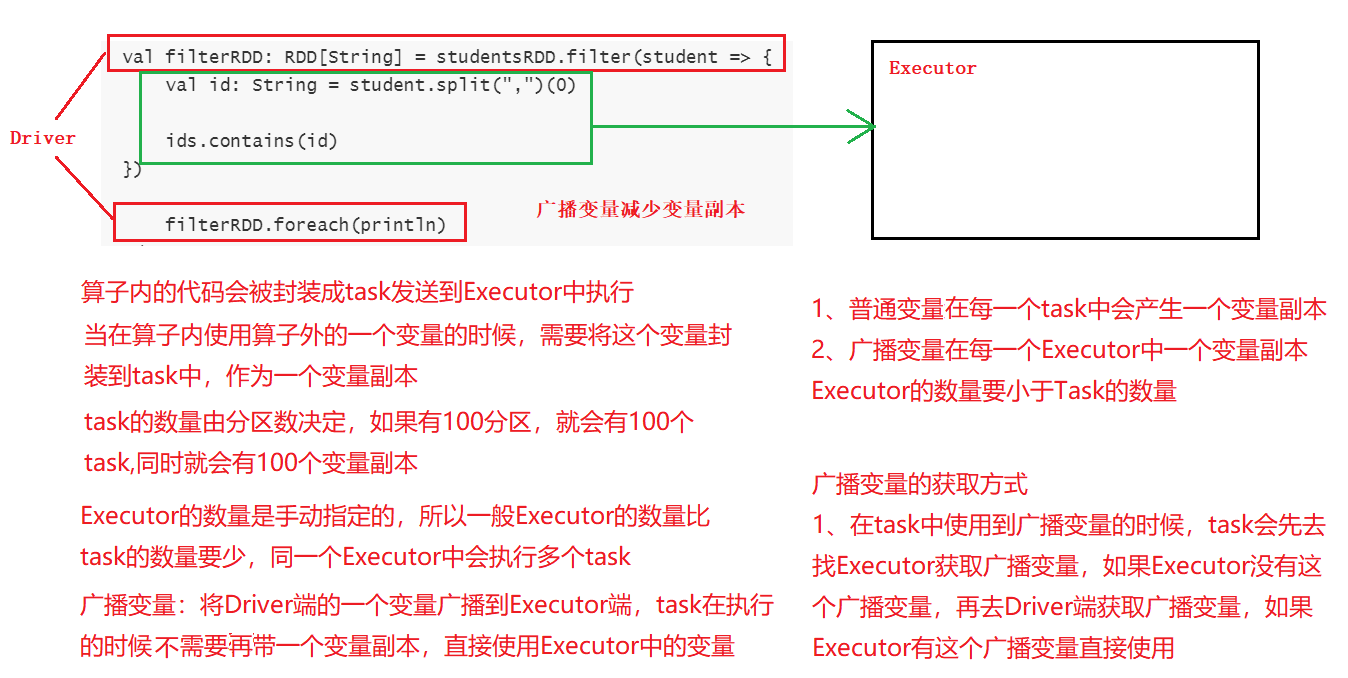
val ids = List("1500100006", "1500100011", "1500100016", "1500100041")
/*
val filterRDD: RDD[String] = studentsRDD.filter(student => {
val id: String = student.split(",")(0)
ids.contains(id)
})
filterRDD.foreach(println)
*/
/**
* 使用广播变量
*
*/
//1、将Driver端的一个变量广播出去 broadcast(ids)
val broIds: Broadcast[List[String]] = sc.broadcast(ids)
val filterRDD: RDD[String] = studentsRDD.filter(student => {
val id: String = student.split(",")(0)
//2、在task中获取广播变量 broIds.value
val value: List[String] = broIds.value
value.contains(id)
})
filterRDD.foreach(println)
}
}
Executor 的结构



