


spark 缓存
spark 缓存
spark 比 MapReduce 快的一个原因
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Demo23Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo23Cache")
val sc = new SparkContext(conf)
val studentsRDD: RDD[String] = sc.textFile("data/students.txt")
//1、将数据拆分出来
val studentTupleRDD: RDD[(String, String, Int, String, String)] = studentsRDD.map(student => {
//这边打个标记,用来观察上面的代码是不是执行了两次
println("studentTupleRDD")
val split: Array[String] = student.split(",")
(split(0), split(1), split(2).toInt, split(3), split(4))
})
/**
* 当对同一个rdd多次使用的时候可以将这个rdd缓存起来
*
*/
//cache() 的缓存级别是 MEMORy_PNLY
//cache() 也是懒执行
//studentTupleRDD.cache()
//使用其它的缓存级别
studentTupleRDD.persist(StorageLevel.MEMORY_ONLY_SER)
/**
* 统计班级的人数
*
*/
//1、取出班级
val clazzRDD: RDD[(String, Int)] = studentTupleRDD.map {
//在这里case的字段我们只用到了一个clazz
//没有使用的列可以使用下划线占位,可以消除IDEA的警告
case (_: String, _: String, _: Int, _: String, clazz: String) =>
(clazz, 1)
}
//统计人数
//reduceByKey((x, y) => x + y)中的x和y我们都只用到了1次
//可以使用_来代替x和y,如下所示
//reduceByKey( _ + _ )
val clazzNumRDD: RDD[(String, Int)] = clazzRDD.reduceByKey((x, y) => x + y)
clazzNumRDD.foreach(println)
/**
* 统计性别的人数
*
*/
//1、取出性别
val genderRDD: RDD[(String, Int)] = studentTupleRDD.map {
///没有使用的列可以使用下划线占位
case (_: String, _: String, _: Int, gender: String, _: String) =>
(gender, 1)
}
//统计人数
val genderNumRDD: RDD[(String, Int)] = genderRDD.reduceByKey((x, y) => x + y)
genderNumRDD.foreach(println)
while (true) {
}
}
}
缓存流程图
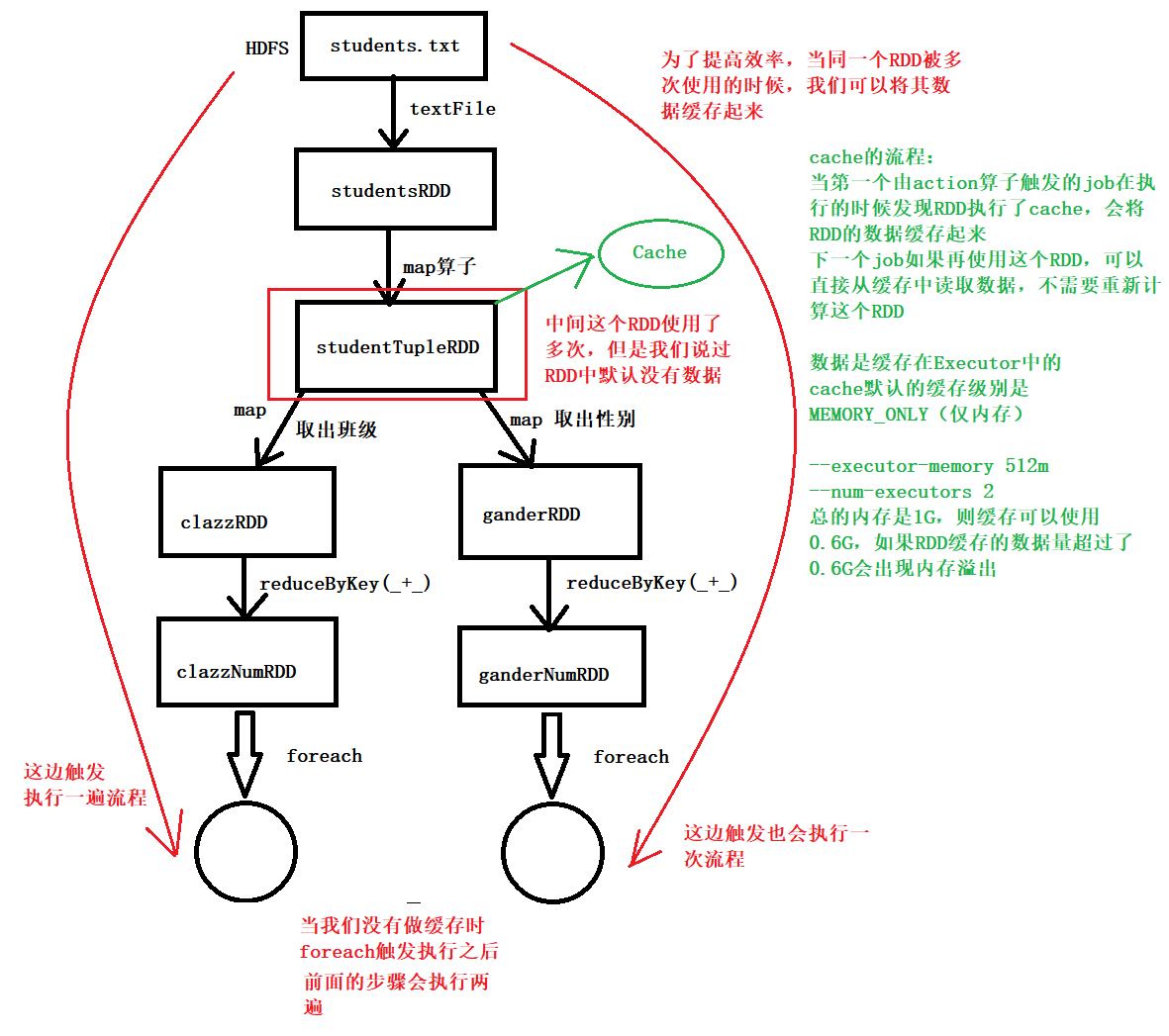
缓存策略


