spark 程序的执行架构、spark on yarn 中 client 模式和 cluster 模式提交任务(资源调度)的区别、宽依赖和窄依赖、spark 程序的结构、spark资源调度及任务调度原理图
目录
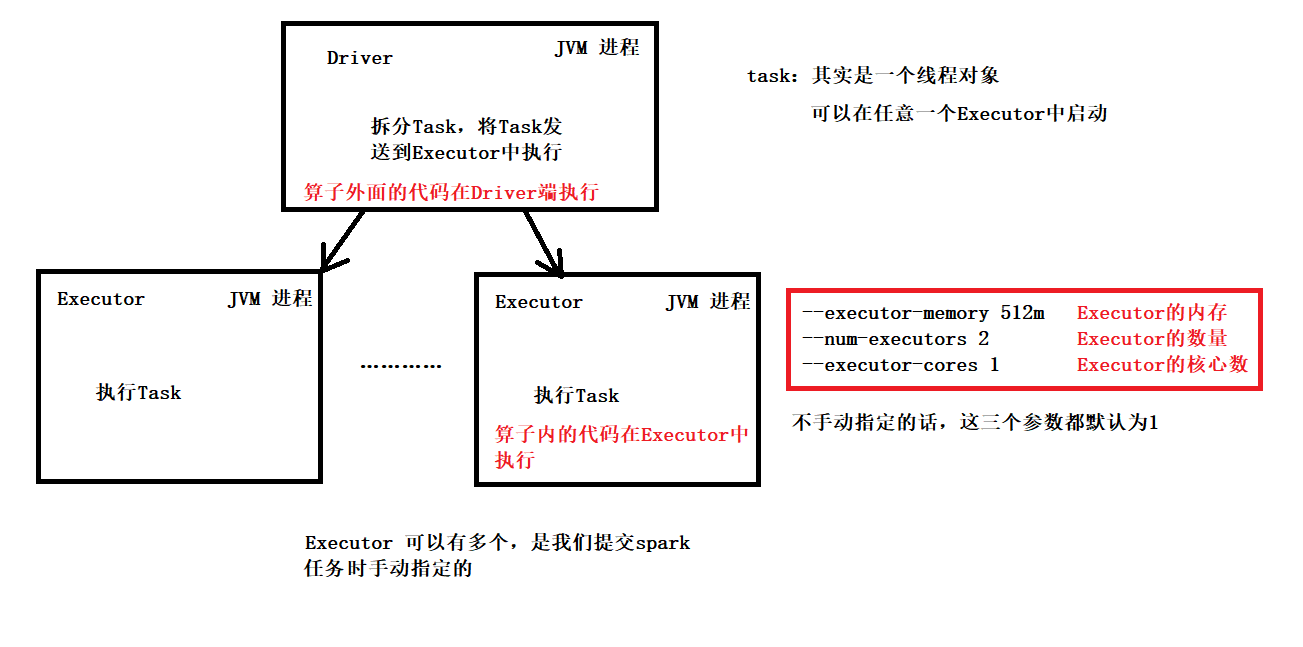
spark 程序的执行架构
任意的 spark 代码都可以分成两个部分 算子里面 和 算子外面
算子里面 -- task -- 在Executor中执行
算子外面 -- 在Driver中执行
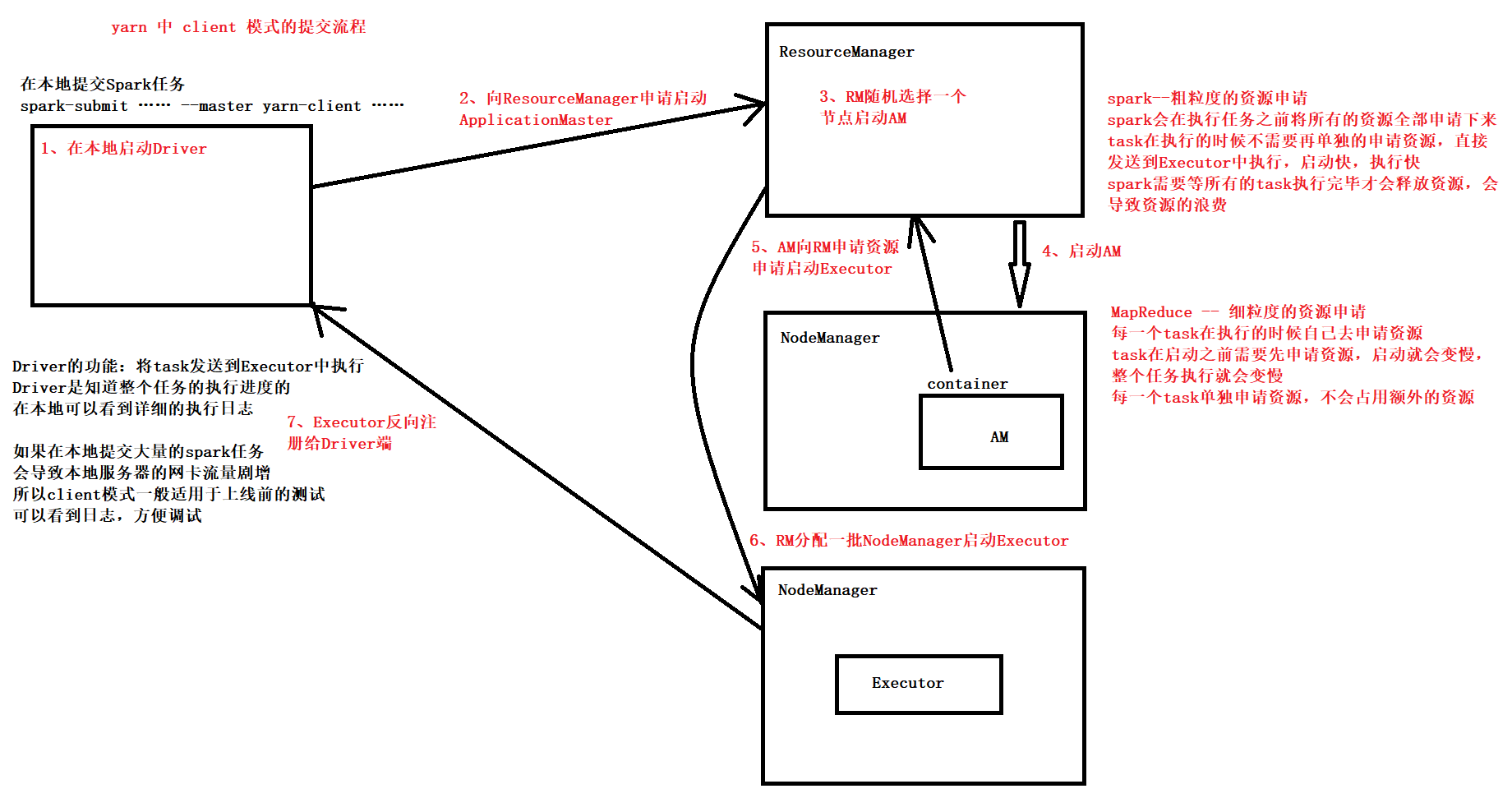
spark on yarn 中 client 模式和 cluster 模式提交任务(资源调度)的区别
Spark 比 MapReduce 快的一个原因
spark--粗粒度的资源申请
spark会在执行任务之前将所有的资源全部申请下来
task在执行的时候不需要再单独的申请资源,直接发送到Executor中执行,启动快,执行快
spark需要等所有的task执行完毕才会释放资源,会导致资源的浪费
MapReduce -- 细粒度的资源申请
每一个task在执行的时候自己去申请资源
task在启动之前需要先申请资源,启动就会变慢,整个任务执行就会变慢
每一个task单独申请资源,不会占用额外的资源
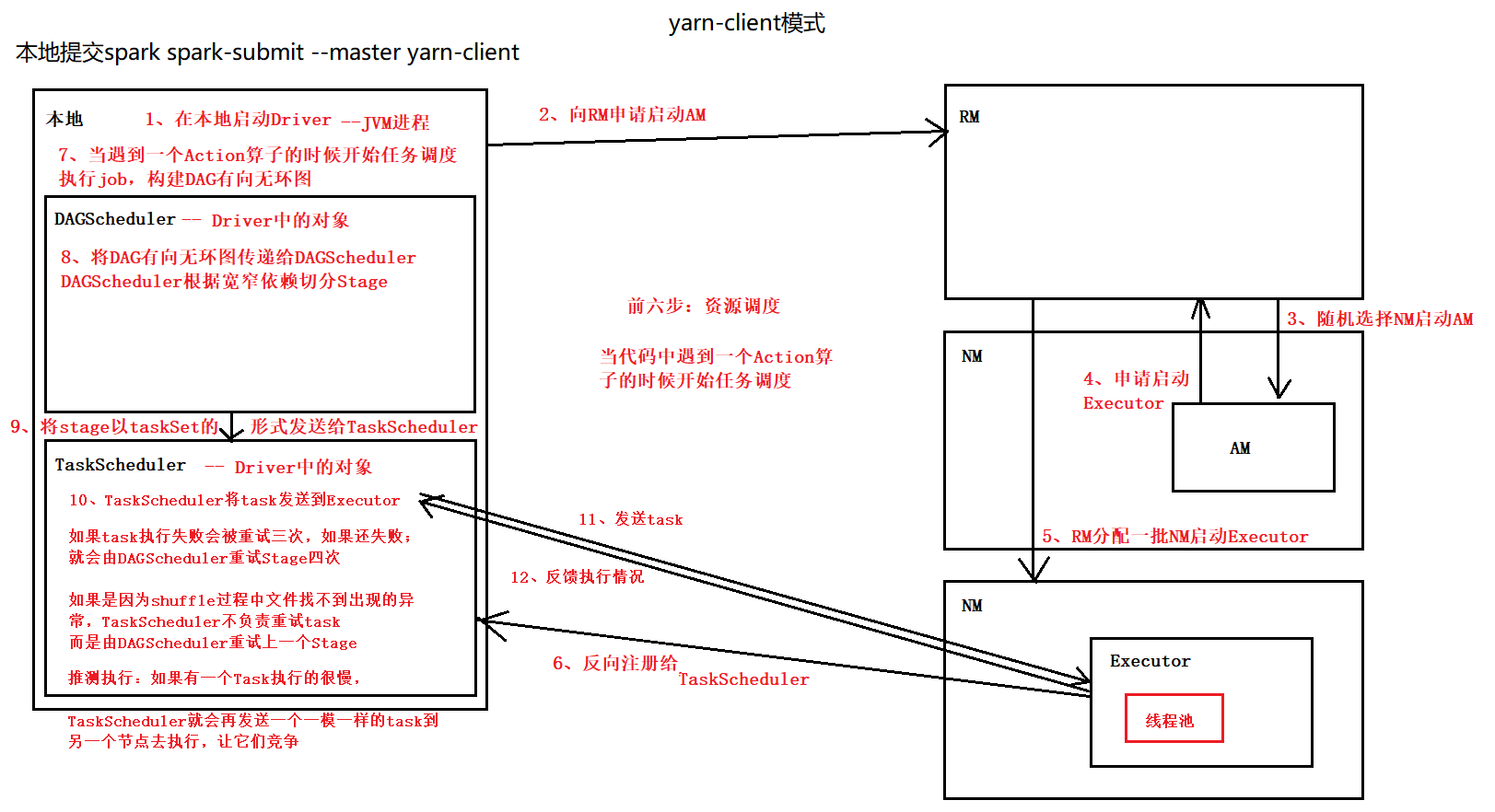
yarn client 模式提交任务的流程
yarn cluster 模式提交任务的流程
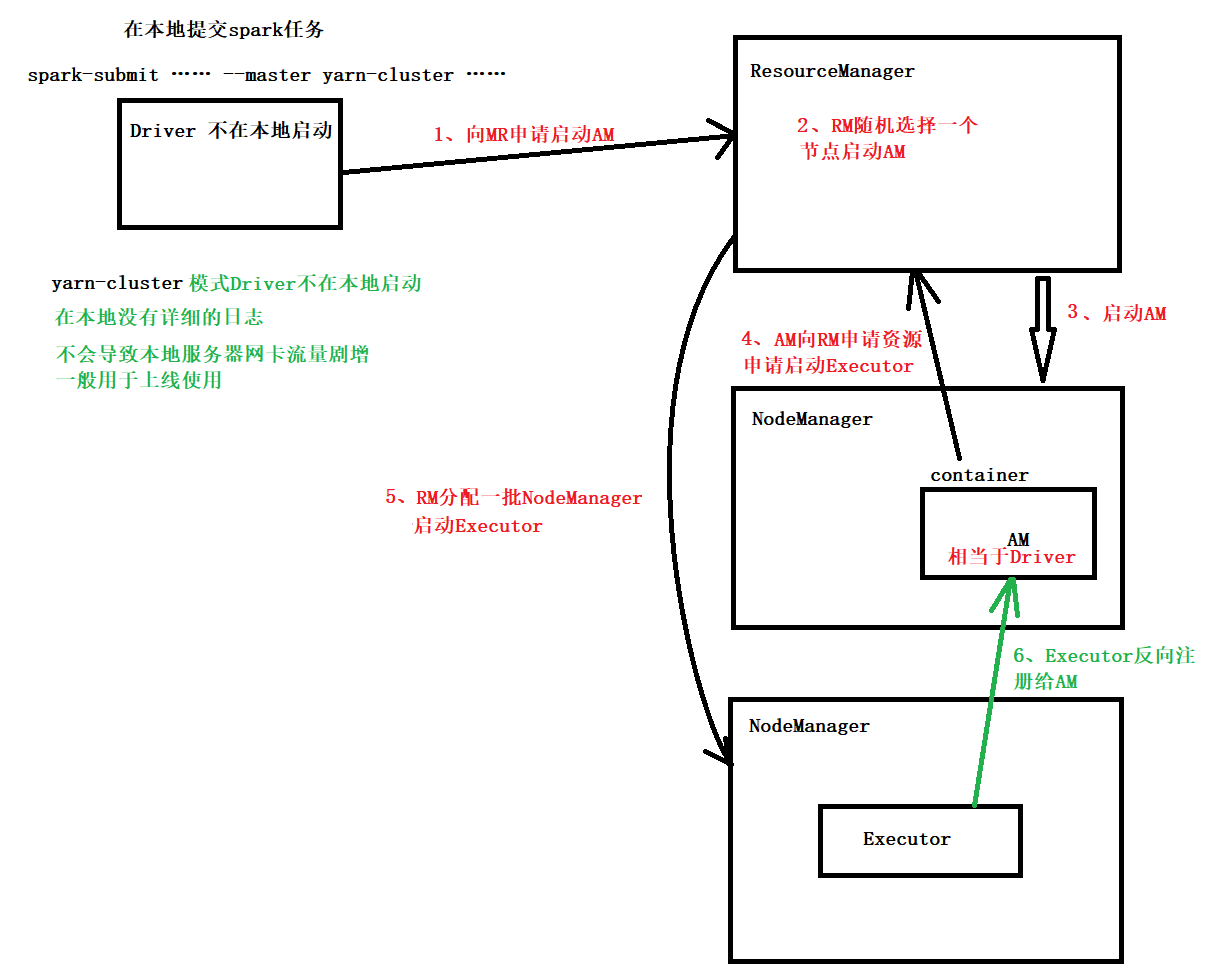
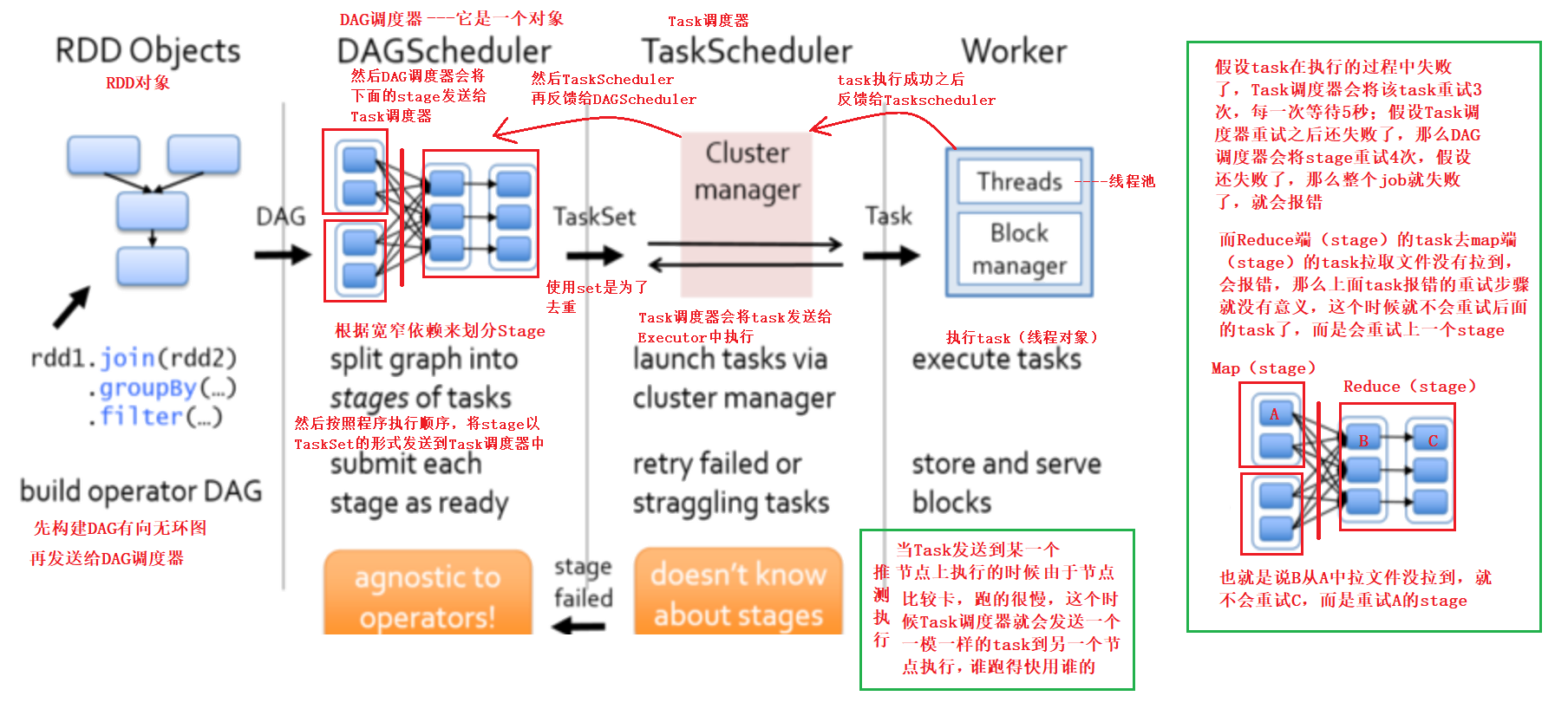
资源调度和任务调度
大数据引擎的执行过程
1、资源调度(申请资源,CPU+内存+Executor的数量)
2、任务调度(执行task)
宽依赖和窄依赖
宽依赖含有shuffle的过程
窄依赖没有shuffle的过程
可以在宽依赖处切一刀划分Stage
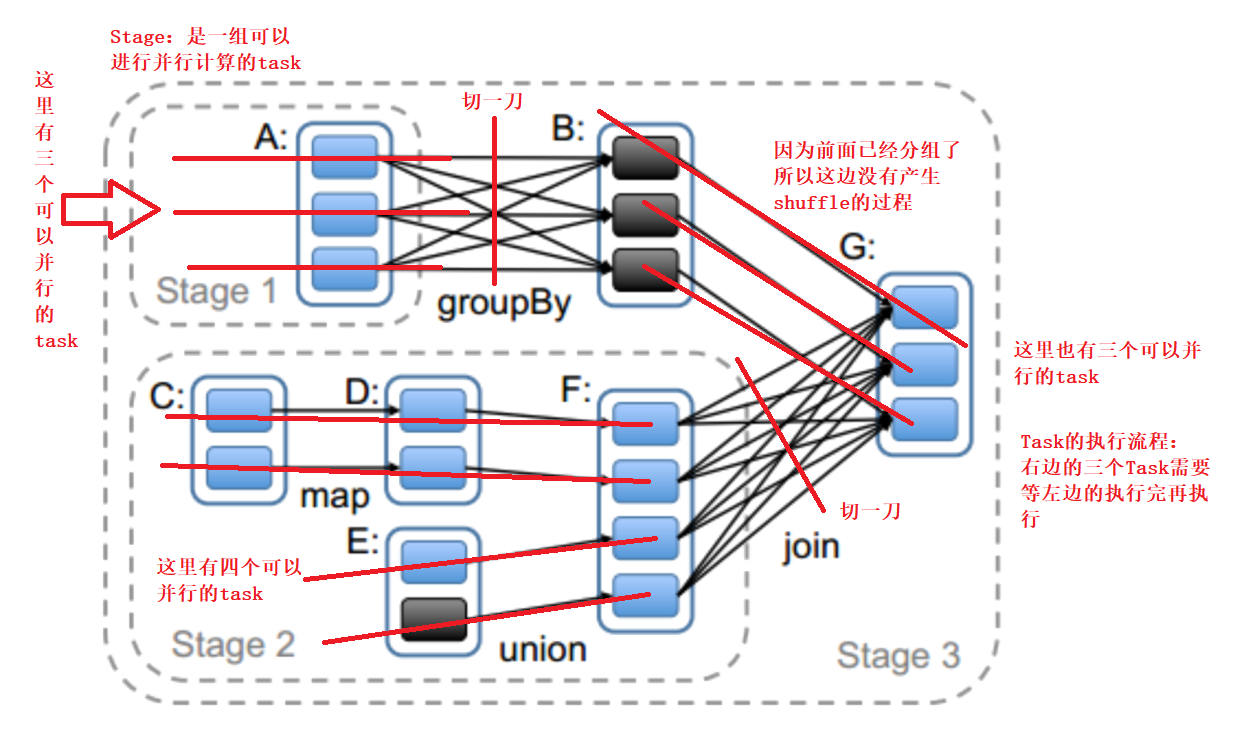
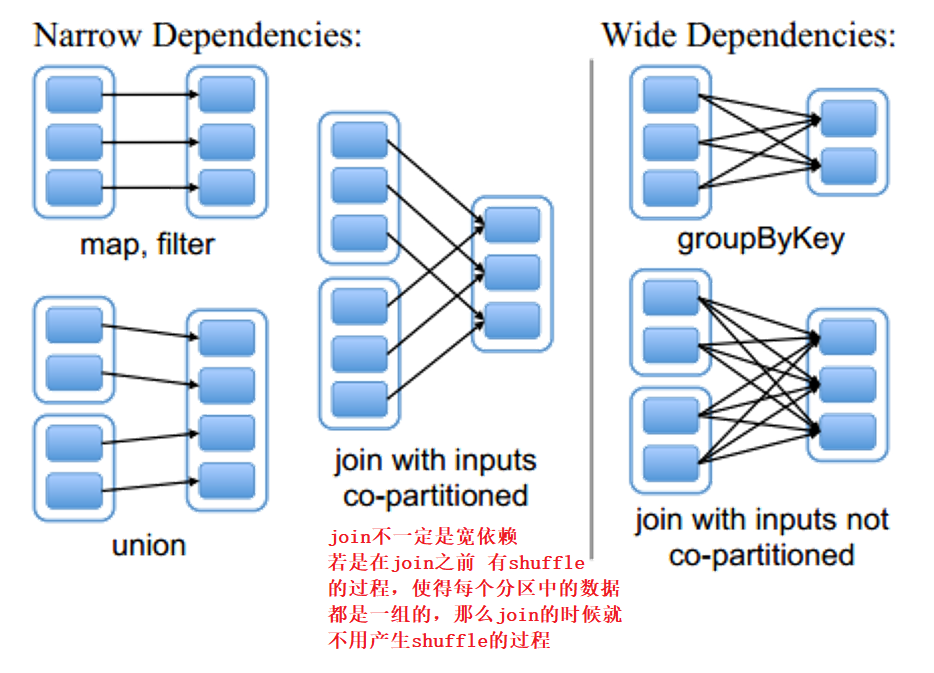
spark 程序的结构
1、Application :应用程序
基于Spark的应用程序,包含了driver程序和 集群上的executor
2、job :由action算子触发
一个Action算子触发一个job
3、stage :由在宽依赖处切分得到
Stage 是一组可以并行计算的task
4、task :线程对象,task中封装了算子的代码逻辑
被送到某个executor上的执行单元
task 的数量是由 分区数 和 shuffle的数量 决定的
spark资源调度及任务调度原理图