spark 算子
目录
- spark 算子的分类
- 程序示例
- transformations map、mapPartitions、mapPartitionsWithIndex
- transformations Filter
- transformations FlatMap
- transformations Sample
- Action 算子 foreach、saveAsTextFile、count、collect
- transformations groupBy、groupByKey
- transformations reduceByKey
- groupByKey、reduceByKey 底层原理图(面试常问)
- transformations union、distinct、intersection
- transformations join、leftOuterJoin、fullOuterJoin
- transformations mapValues
- transformations sortBy、sortByKey
- transformations aggregateByKey
- transformations cartesian
- transformations pipe
- Action reduce、sum; transformations reduceBykey
- Action take、first
- 练习
spark 算子的分类
转换算子
transformations 延迟执行--针对RDD的操作
操作算子
Action 触发执行
常用算子归纳

程序示例
transformations map、mapPartitions、mapPartitionsWithIndex
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo3Map {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("map")
.setMaster("local")
val sc = new SparkContext(conf)
/**
* 构建rdd的方法
* 1、读取文件
* 2、基于scala的集合构建rdd --- 用于测试
*/
//基于集合构建rdd
// Sequence -- Scala中所有集合的父类
val listRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 2)
println(listRDD.getNumPartitions)
/**
* map算子:
* 将rdd中的数据一条一条传递给后面的函数。将函数的返回值构建成一个新的rdd
* map不会产生shuffle,map之后rdd的分区数等于map之前rdd的分区数
*
* map是一个转换算子-- 懒执行, 需要一个action触发执行
* foreach: action算子
*
* 如果一个算子的返回值是一个新的rdd,那么这个算子就是转换算子
*
*
*/
val mapRDD: RDD[Int] = listRDD.map(i => {
println("map")
i * 2
})
//mapRDD.foreach(println)
/**
* mapPartitions : 将每一个分区的数据传递给后面的函数,后面的函数需要返回一个迭代器,再构建一个新的rdd
*
* 迭代器中是一个分区的数据
*
* mapPartitions: 懒执行,转换算子
*/
val mapPartitionsRDD: RDD[Int] = listRDD.mapPartitions((iter: Iterator[Int]) => {
val iterator: Iterator[Int] = iter.map(i => i * 2)
//最后一行作为返回值
iterator
}
)
//mapPartitionsRDD.foreach(println)
/**
* mapPartitionsWithIndex: 一次遍历一个分区,会多一个分区的下标
*
*/
val mapPartitionsWithIndexRDD: RDD[Int] = listRDD.mapPartitionsWithIndex((index: Int, iter: Iterator[Int]) => {
println(s"当前分区的编号:$index")
iter
})
mapPartitionsWithIndexRDD.foreach(println)
}
}
transformations Filter
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo4Filter {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("Demo4Filter")
.setMaster("local")
val sc = new SparkContext(conf)
//构建rdd
val listRDD: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8))
/**
* filter: 对rdd中的数据进行过滤,函数返回true保留数据,函数返回false过滤数据
*
* filter: 转换算子,懒执行
*/
val filterRDD: RDD[Int] = listRDD.filter(i => {
i % 2 == 1
})
filterRDD.foreach(println)
}
}
transformations FlatMap
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Demo5FlatMap {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("Demo5FlatMap")
.setMaster("local")
val sc = new SparkContext(conf)
val linesRDD: RDD[String] = sc.parallelize(List("java,spark,java", "spark,scala,hadoop"))
/**
* flatMap: 将rdd的数据一条一条传递给后面的函数,
* 后面的函数的返回值是一个集合,最后会将这个集合拆分出来构建成一个新的rdd
*
*/
val wordsRDD: RDD[String] = linesRDD.flatMap(line => {
val arr: Array[String] = line.split(",")
//返回值可以是一个数组,list,set map ,必须是scala中的集合
arr.toList
})
wordsRDD.foreach(println)
}
}
transformations Sample
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo6Sample {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("Demo5FlatMap")
.setMaster("local")
val sc = new SparkContext(conf)
val studentRDD: RDD[String] = sc.textFile("data/students.txt")
/**
* sample: 抽样, 不是精确抽样
* withReplacement: 是否放回
* fraction: 抽样比例(近似的)
*
*/
val sample: RDD[String] = studentRDD.sample(false, 0.1)
sample.foreach(println)
}
}
Action 算子 foreach、saveAsTextFile、count、collect
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo7Action {
def main(args: Array[String]): Unit = {
/**
* spark 任务的层级关系
* application --> job(每个Action 算子触发的任务) --> stage(类似MapReduce中的map端或者reduce端)--> task(每个分区中的task)
* 如果算子的返回值不是RDD,就是 Action 算子
*/
val conf: SparkConf = new SparkConf()
.setAppName("Demo5FlatMap")
.setMaster("local")
val sc = new SparkContext(conf)
/**
* action算子 -- 触发任务执行,每一个action算子都会触发一个job任务
* 1、foreach: 遍历rdd
* 2、saveAsTextFile : 保存数据
* 3、count : 统计rdd的行数
* 4、collect: 将rdd转换成scala的集合
*/
val studentsRDD: RDD[String] = sc.textFile("data/students.txt")
/**
* foreach: 一次遍历一条数据
* foreachPartition: 一次遍历一个分区
*
*/
studentsRDD.foreach(println)
studentsRDD.foreachPartition((iter: Iterator[String]) => println(iter.toList))
/**
* saveAsTextFile: 将数据保存到hdfs
* 1、输出目录不能存在
* 2、rdd一个分区对应一个文件
*
*/
//studentsRDD.saveAsTextFile("data/temp2")
/**
*count: 统计行数
*
*/
val count: Long = studentsRDD.count()
println(s"studentsRDD的行数:$count")
/**
* collect: 将rdd的数据拉取到内存中
* 如果数据量很大,会出现内存溢出
*
*/
val studentArr: Array[String] = studentsRDD.collect()
println(studentArr)
while (true) {
}
}
}
transformations groupBy、groupByKey
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo8GroupByKey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("groupByKey")
val sc = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("data/words.txt")
val wordsRDD: RDD[String] = linesRDD.flatMap(line => line.split(","))
//将rdd转换成kv格式
//Optionally, a Partitioner for key-value RDDs
//分区类的算子只能作用在k-v格式的RDD上
//所有Bykey的算子
val kvRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
/**
* groupByKey: 按照key进行分组,必须是kv格式的rdd, 将同一个key的value放到迭代器中
*
*/
val groupBykeyRDD: RDD[(String, Iterable[Int])] = kvRDD.groupByKey()
groupBykeyRDD.foreach(println)
val countRDD: RDD[(String, Int)] = groupBykeyRDD.map {
case (word: String, ints: Iterable[Int]) =>
val count: Int = ints.sum
(word, count)
}
countRDD.foreach(println)
/**
* groupBy: 指定一个分组的列,返回的rdd的value包含所有的数据
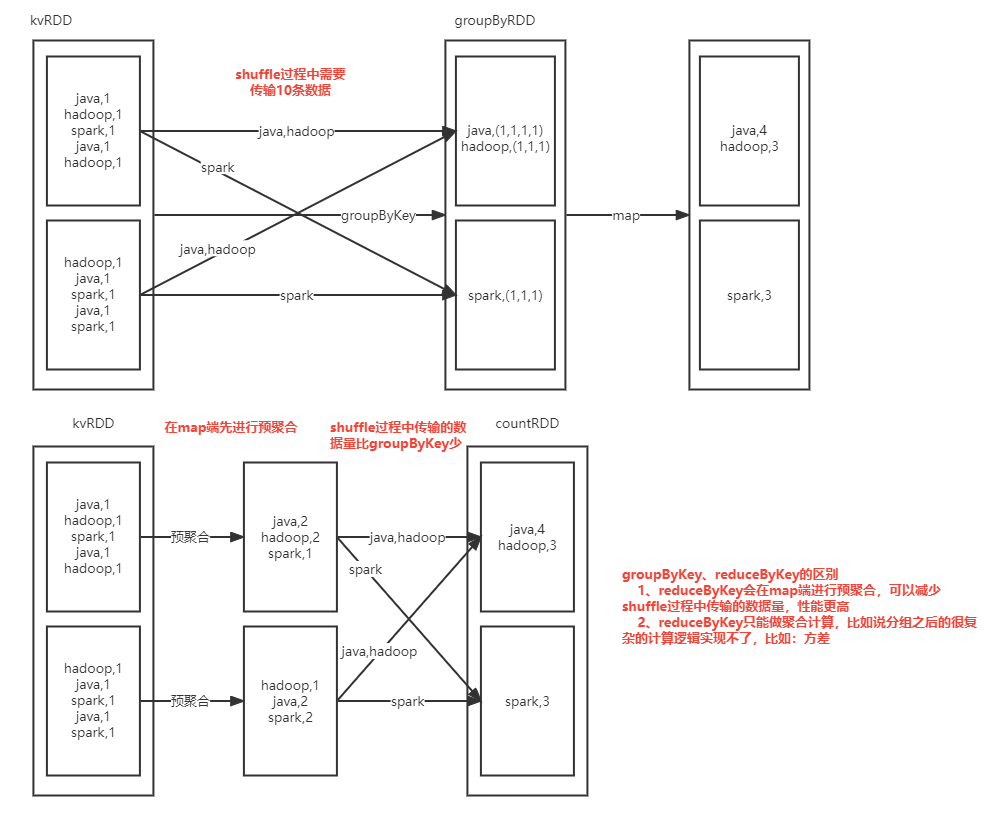
* shuffle过程中需要传输的数据量比groupBykey要多,性能要差一点
*
*/
val groupByRDD: RDD[(String, Iterable[(String, Int)])] = kvRDD.groupBy(kv => kv._1)
groupByRDD.foreach(println)
}
}
transformations reduceByKey
package com.shujia.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo9ReduceBykey {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("groupByKey")
val sc = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("data/words.txt")
val wordsRDD: RDD[String] = linesRDD.flatMap(line => line.split(","))
//将rdd转换成kv格式
val kvRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
/**
* reduceByKey: 按照key分组并将value进行聚合计算,聚合的方式由传入的函数来定
* 按照key进行聚合计算,会在Map端进行预聚合,所以reduceByKey的性能要比groupByKey更好
* 只能做简单的聚合计算
* 聚合的过程是一个一个的进行的
* 例如:(A,1)和(A,1)聚合完之后形成(A,2),(A,2)再和下一个(A,1)聚合形成(A,3),……
*/
//统计单词的数量
val countRDD: RDD[(String, Int)] = kvRDD.reduceByKey((x: Int, y: Int) => x + y)
countRDD.foreach(println)
}
}
groupByKey、reduceByKey 底层原理图(面试常问)
transformations union、distinct、intersection
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo10Union {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo10Union")
val sc = new SparkContext(conf)
// makeRDD:将集合构建成RDD
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8))
val rdd2: RDD[Int] = sc.makeRDD(List(4, 5, 6, 7, 8, 9, 10))
/**
* union:合并两个rdd, 两个rdd的数据类型要一致,默认不去重
* union只是逻辑层面(代码层面)的合并,在物理层面并没有合并
* union 不会产生shuffle
*
*/
val unionRDD: RDD[Int] = rdd1.union(rdd2)
unionRDD.foreach(println)
/**
* distinct: 去重
* distinct: 会产生shuffle
* distinct: 会先在map端局部去重,再到reduce端全局去重
*/
val distinctRDD: RDD[Int] = unionRDD.distinct()
distinctRDD.foreach(println)
/**
* 所有会产生shuffle的算子都可以指定shuffle后的分区域数
* distinct也可以指定shuffle后的分区域数
*/
/**
* intersection: 取两个rdd的交集
* 可以指定shuffle后的分区数 -- 会有shuffle的过程
*/
val intersectionRDD: RDD[Int] = rdd1.intersection(rdd2)
intersectionRDD.foreach(println)
}
}
transformations join、leftOuterJoin、fullOuterJoin
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo11Join {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo10Union")
val sc = new SparkContext(conf)
val namesRDD: RDD[(String, String)] = sc.makeRDD(List(("001", "张三"), ("002", "李四")))
val agesRDD: RDD[(String, Int)] = sc.makeRDD(List(("002", 24), ("003", 25)))
/**
* inner join; 通过rdd的key进行关联
*
*/
val innerJoinRDD: RDD[(String, (String, Int))] = namesRDD.join(agesRDD)
//关联之后整理数据
val rdd1: RDD[(String, String, Int)] = innerJoinRDD.map {
case (id: String, (name: String, age: Int)) =>
(id, name, age)
}
//rdd1.foreach(println)
/**
* left join : 以左表为主,关联之后如果右表对应位置没有数据,则为null
* Option: 是一个可选的值 (有值:Some , 没有值:None)
*/
val leftJoinRDD: RDD[(String, (String, Option[Int]))] = namesRDD.leftOuterJoin(agesRDD)
//整理数据
val rdd2: RDD[(String, String, Int)] = leftJoinRDD.map {
//匹配关联成功的数据
case (id: String, (name: String, Some(age))) =>
(id, name, age)
//匹配没有关联成功的数据
case (id: String, (name: String, None)) =>
//没有关联可以给一个默认值0
(id, name, 0)
}
// rdd2.foreach(println)
/**
* full join: 两表关联时两边都可能出现关联不上,关联不上则补null
*
*/
val fullJOinRDD: RDD[(String, (Option[String], Option[Int]))] = namesRDD.fullOuterJoin(agesRDD)
//整理数据
val rdd3: RDD[(String, String, Int)] = fullJOinRDD.map {
case (id: String, (Some(name), Some(age))) =>
(id, name, age)
case (id: String, (None, Some(age))) =>
(id, "默认值", age)
case (id: String, (Some(name), None)) =>
(id, name, 0)
}
rdd3.foreach(println)
}
}
transformations mapValues
package com.shujia.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo12MapValues {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo10Union")
val sc = new SparkContext(conf)
val agesRDD: RDD[(String, Int)] = sc.makeRDD(List(("002", 24), ("003", 25)))
// map
val mapRDD: RDD[(String, Int)] = agesRDD.map {
case (name: String, age: Int) =>
(name, age + 1)
}
mapRDD.foreach(println)
/**
* mapValues: 和map差不多,但只对 value 做处理,key不变
*
*/
val mapValuesRDD: RDD[(String, Int)] = agesRDD.mapValues(v => v + 1)
mapValuesRDD.foreach(println)
}
}
transformations sortBy、sortByKey
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo13Sort {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo10Union")
val sc = new SparkContext(conf)
val studentRDD: RDD[String] = sc.textFile("data/students.txt")
/**
*
* sortBy: 指定一个排序的列,默认是升序
* ascending 控制排序方式
*/
// 指定降序 ascending = false
val sortByRDD: RDD[String] = studentRDD.sortBy(student => {
val age: Int = student.split(",")(2).toInt
age
}, ascending = false)
sortByRDD.foreach(println)
/**
* sortByKey: 通过key进行排序,默认是升序
* 要求 k-v 的RDD
*/
val agesRDD: RDD[(Int, String)] = sc.makeRDD(List((24, "002"), (25, "003")))
val sortByKeyRDD: RDD[(Int, String)] = agesRDD.sortByKey()
sortByKeyRDD.foreach(println)
}
}
transformations aggregateByKey
package com.shujia.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo14Agg {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo14Agg")
val sc = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("data/words.txt")
val wordsRDD: RDD[String] = linesRDD.flatMap(line => line.split(","))
//将rdd转换成kv格式
val kvRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
/**
* reduceByKey: 会再map进行预聚合,后面的聚合函数会应用在map端和reduce端(聚合函数会应用在分区内的聚合和分区间的聚合)
*
*/
val reduceRDD: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
reduceRDD.foreach(println)
/**
* aggregateByKey: 按照key进行聚合,需要传入两个聚合函数,一个是map端的聚合,一个是reduce端的聚合
*
*/
// (0) -- 指定初始值(在map端聚合时的初始值)
val aggRDD: RDD[(String, Int)] = kvRDD.aggregateByKey(0)(
(u: Int, i: Int) => u + i, //分区内的聚合函数(map端的聚合函数)
(u1: Int, u2: Int) => u1 + u2 // 分区间的聚合函数(reduce端的聚合函数)
)
aggRDD.foreach(println)
}
}
计算班级的平均年龄
使用groupByKey实现
使用aggregateByKey实现
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo15AggAvgAge {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo14Agg")
val sc = new SparkContext(conf)
/**
* 计算班级的平均年龄
*
*/
val studentsRDD: RDD[String] = sc.textFile("data/students.txt")
//先取出班级和年龄
val clazzAndAge: RDD[(String, Double)] = studentsRDD.map(student => {
val split: Array[String] = student.split(",")
(split(4), split(2).toDouble)
})
/**
* 1、使用groupByKey实现
*
*/
val groupByRDD: RDD[(String, Iterable[Double])] = clazzAndAge.groupByKey()
//计算平均年龄
val avgAgeRDD: RDD[(String, Double)] = groupByRDD.map {
case (clazz: String, ages: Iterable[Double]) =>
val avgAge: Double = ages.sum / ages.size
(clazz, avgAge)
}
avgAgeRDD.foreach(println)
/**
* 在大数据计算中shuffle是最耗时间的,因为shuffle过程中的数据是需要落地到磁盘的
*
* 高性能算子
* aggregateByKey: 会先在map端做预聚合,性能高, 可以减少shuffle过程中的数据量
* 1、初始值,初始值可以有多个
* 2、map端的聚合函数
* 3、reduce端的聚合函数
*/
val aggRDD: RDD[(String, (Double, Int))] = clazzAndAge.aggregateByKey((0.0, 0))(
(u: (Double, Int), age: Double) => (u._1 + age, u._2 + 1), //map端的聚合函数
(u1: (Double, Int), u2: (Double, Int)) => (u1._1 + u2._1, u1._2 + u2._2) //reduce端的聚合函数
)
//计算平均年龄
val avgAgeRDD2: RDD[(String, Double)] = aggRDD.map {
case (clazz: String, (sumAge: Double, num: Int)) =>
(clazz, sumAge / num)
}
avgAgeRDD2.foreach(println)
while (true){
}
}
}
transformations cartesian
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo16cartesian {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo14Agg")
val sc = new SparkContext(conf)
val namesRDD: RDD[(String, String)] = sc.makeRDD(List(("001", "张三"), ("002", "李四")))
val agesRDD: RDD[(String, Int)] = sc.makeRDD(List(("002", 24), ("003", 25)))
/**
* 笛卡尔积 -- cartesian
* 很少用,性能非常差
*/
val cartesianRDD: RDD[((String, String), (String, Int))] = namesRDD.cartesian(agesRDD)
cartesianRDD.foreach(println)
}
}
transformations pipe
在spark代码中调用外部脚本的方法 -- 很少用
常用于和第三方整合
Action reduce、sum; transformations reduceBykey
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo17Reduce {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo14Agg")
val sc = new SparkContext(conf)
val listRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9))
/**
* sum 求和,Action算子 只能用于int,double,long类型的求和
*
*/
val sum: Double = listRDD.sum()
println(sum)
/**
* reduce: 全局聚合 action算子
* reduceBykYe 通过key进行聚合 transformations 算子
*/
val reduce: Int = listRDD.reduce((x, y) => x + y)
println(reduce)
}
}
Action take、first
package com.shujia.spark
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo18Take {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo14Agg")
val sc = new SparkContext(conf)
val studentsRDD: RDD[String] = sc.textFile("data/students.txt")
/**
* take: 取top,是一个 action 算子
*
*/
// 取 前100条
val top100: Array[String] = studentsRDD.take(100)
top100.foreach(println)
//first -- 获取第一条数据 Action 算子
val first: String = studentsRDD.first()
println(first)
}
}
练习
统计总分大于年级平均分的学生
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo19Student1 {
def main(args: Array[String]): Unit = {
/**
* 统计总分大于年级平均分的学生
*/
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("Demo14Agg")
val sc = new SparkContext(conf)
val scoreRDD: RDD[String] = sc.textFile("data/score.txt")
val idAndScoreRDD: RDD[(String, Double)] = scoreRDD.map(s => {
val split: Array[String] = s.split(",")
(split(0), split(2).toDouble)
})
//1、计算学生的总分
val stuSumSocreRDD: RDD[(String, Double)] = idAndScoreRDD.reduceByKey((x, y) => x + y)
//所有的总分
val scores: RDD[Double] = stuSumSocreRDD.map(kv => kv._2)
//计算平均分
val avgSco: Double = scores.sum() / scores.count()
println(s"年级平均分:$avgSco")
//取出总分打印平均分的学生
val filterRDD: RDD[(String, Double)] = stuSumSocreRDD.filter {
case (id: String, sco: Double) =>
sco > avgSco
}
filterRDD.foreach(println)
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号