RDD 分区数的设置、访问 spark web界面,查看任务运行状态
RDD 分区数的设置
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo2Partition {
def main(args: Array[String]): Unit = {
/**
* 创建上下文对象
*
*/
val conf: SparkConf = new SparkConf()
.setAppName("partition")
.setMaster("local")
//设置spark 默认分区数 (spark.default.parallelism(默认并行度)), 只在shuffle之后生效
conf.set("spark.default.parallelism", "3")
val sc = new SparkContext(conf)
/**
* data/words 下有三个文件
*
* 1、读取文件的时候控制分区数
*
* linesRDD分区数据默认等于block的数量
*
* textFile 中的默认参数 minPartitions:用于控制读取文件得到的 RDD 的分区数
*
* 默认的 minPartitions 不是 2 就是 1
*
* 分区数越多:task越多,任务越快,但是不能太多,因为task启动也需要时间
*
* 保证每一个分区处理的数据量在128M左右
*
* minPartitions : 只能用于增加分区不能用于减少分区
*
* 为了分区的时候每个文件的数据能均匀分配,所以分区的时候spark会去计算 文件的倍数 与 minPartitions 的关系
* 让 文件的倍数 >= minPartitions 即可,例如 文件数为3,设置 minPartitions=4 ,则 3*2 >= 4
* 即 分区时 让每个文件都分一下
*/
val linesRDD: RDD[String] = sc.textFile("data/words", 4)
// getNumPartitions -- 获取 RDD 的分区数
println(s"linesRDD分区数:${linesRDD.getNumPartitions}")
/**
* 窄依赖关系: 后面RDD的分区数等于前一个RDD的分区数
* 分区对应关系是一对一的关系
*
*/
val wordsRDD: RDD[String] = linesRDD.flatMap(line => line.split(","))
println(s"wordsRDD分区数:${wordsRDD.getNumPartitions}")
/**
* 宽依赖的算子产生的RDD的分区数默认等于前一个RDD的分区数
* 所有会产生shuffle的算子都可以手动指定分区数
*
* 如果分区之后数据量减少了,可以减少分区,保证每一个分区的数据量在128M左右
*
* shuffle之后分区数优先级
* 手动指定分区数 > spark.default.parallelism(默认并行度) > 依赖上一个RDD
*
*/
// 若函数中传入多个参数,则参数需要加上类型
// 这里手动指定 shuffle 之后分区数
val groupByRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy((word: String) => word, 10)
println(s"groupByRDD分区数:${groupByRDD.getNumPartitions}")
groupByRDD.saveAsTextFile("data/temp")
// 在这加上死循环,为了来观察spark的web页面
// 因为只有在任务执行过程中才能访问,任务结束之后就访问不了了
while (true) {
}
}
}
访问 spark web界面,查看任务运行状态
在 IDEA 下面输出的日志中可以找到 spark 的端口
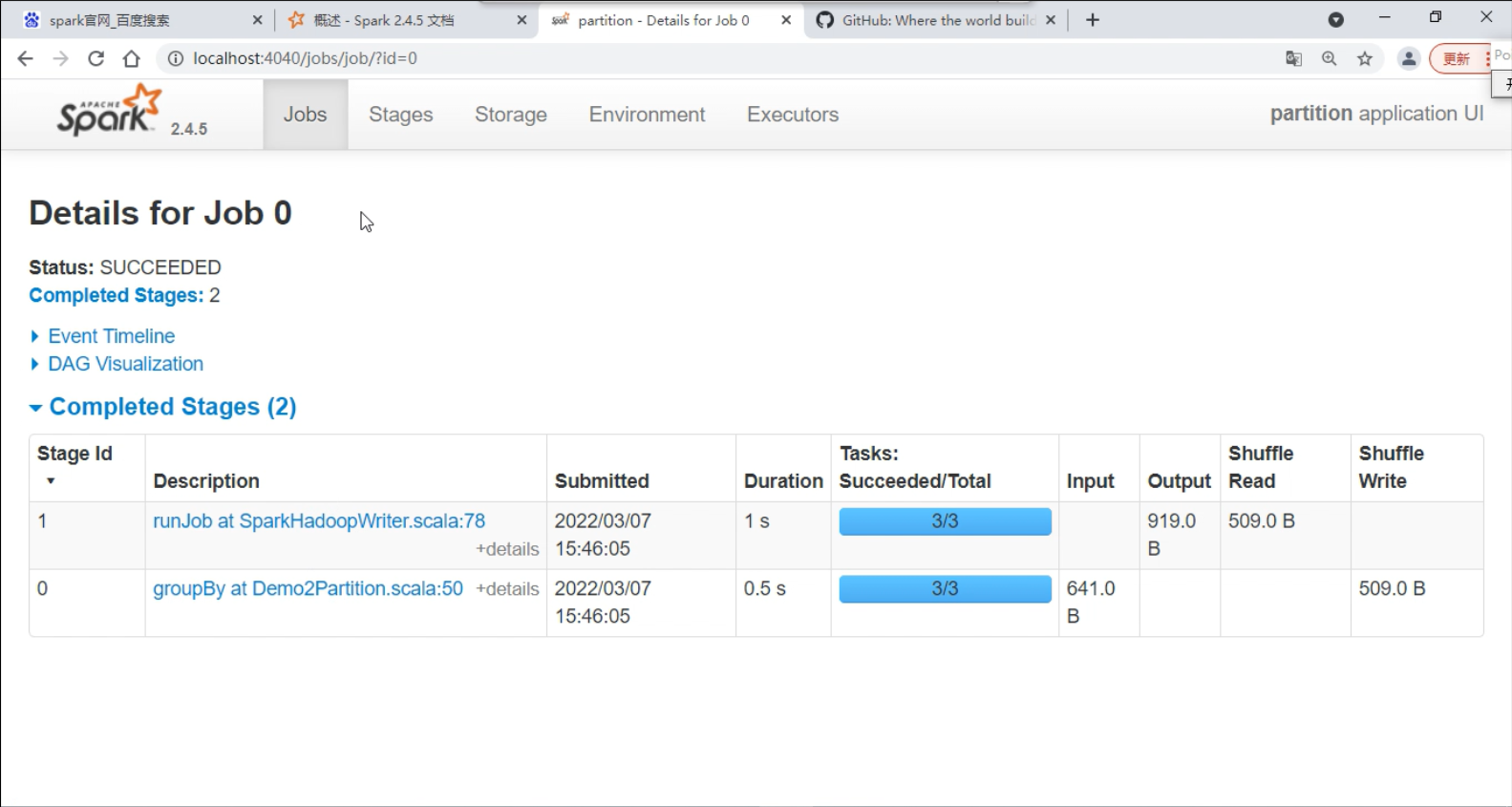
在浏览器中输入 localhost:4040 查看
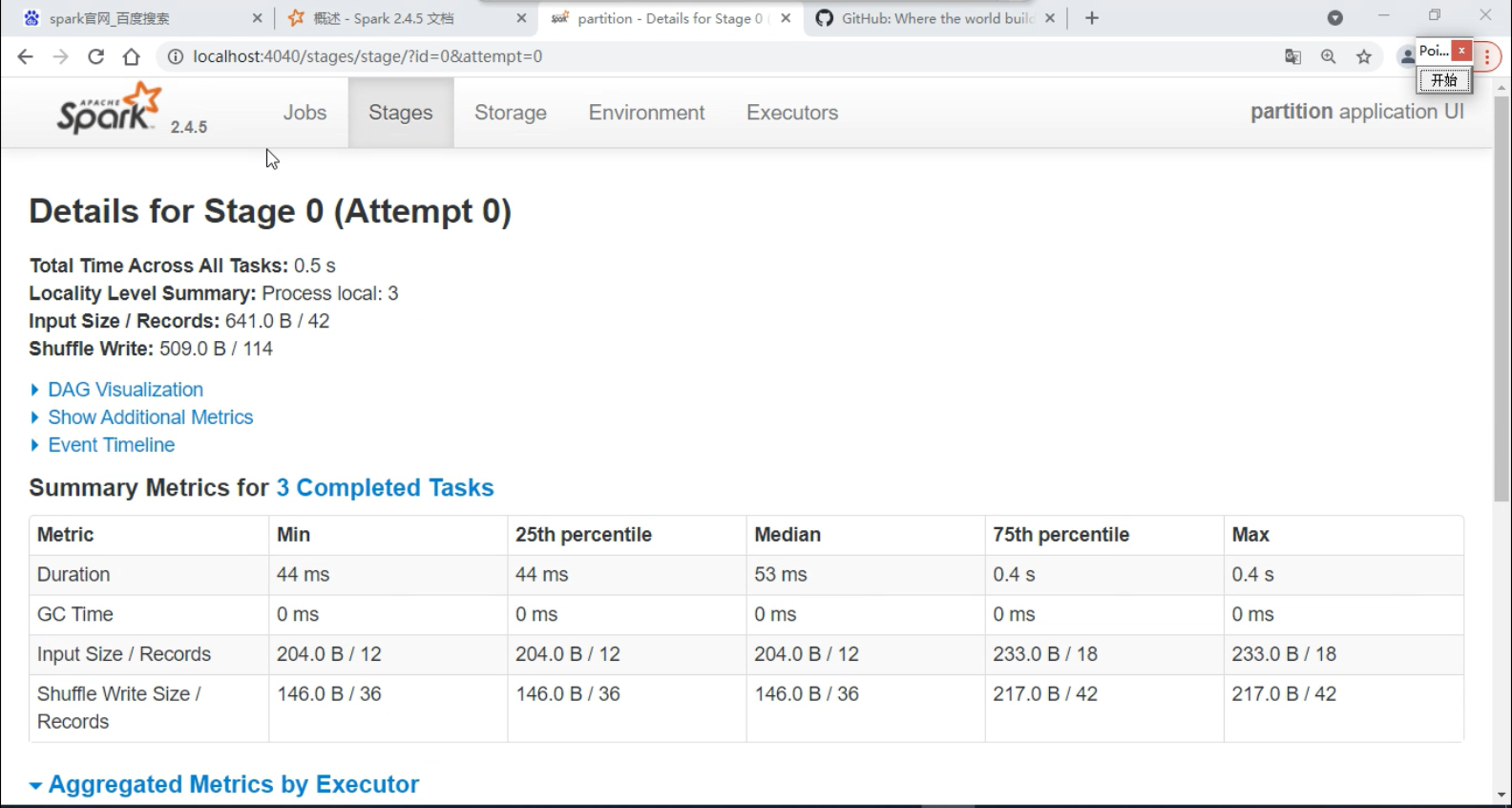
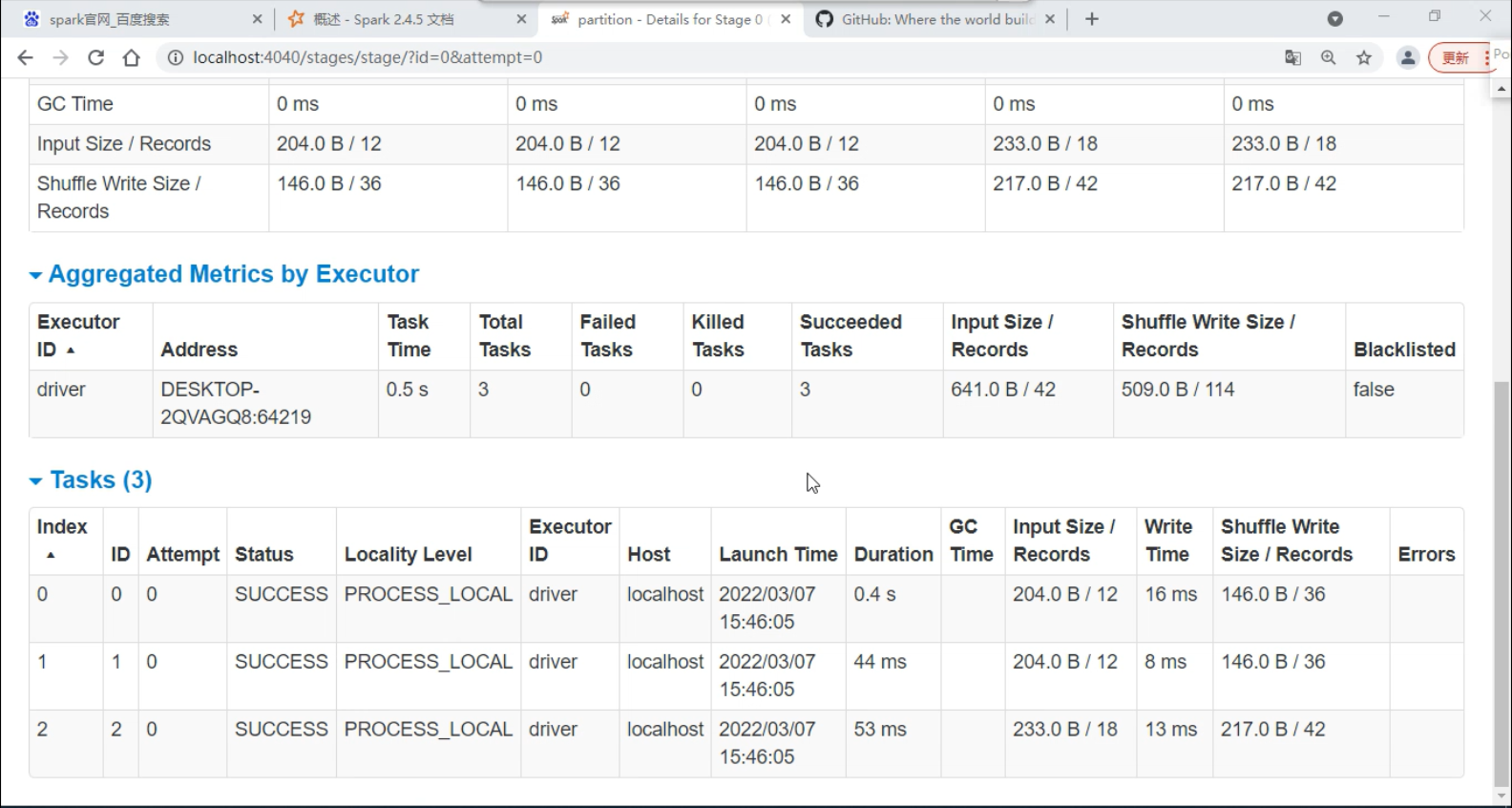
Stage -- 相当于MapReduce中的 map 端和 Reduce 端,只是在 spark 中叫做Stage
在 shuffle 过程中数据会落地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号