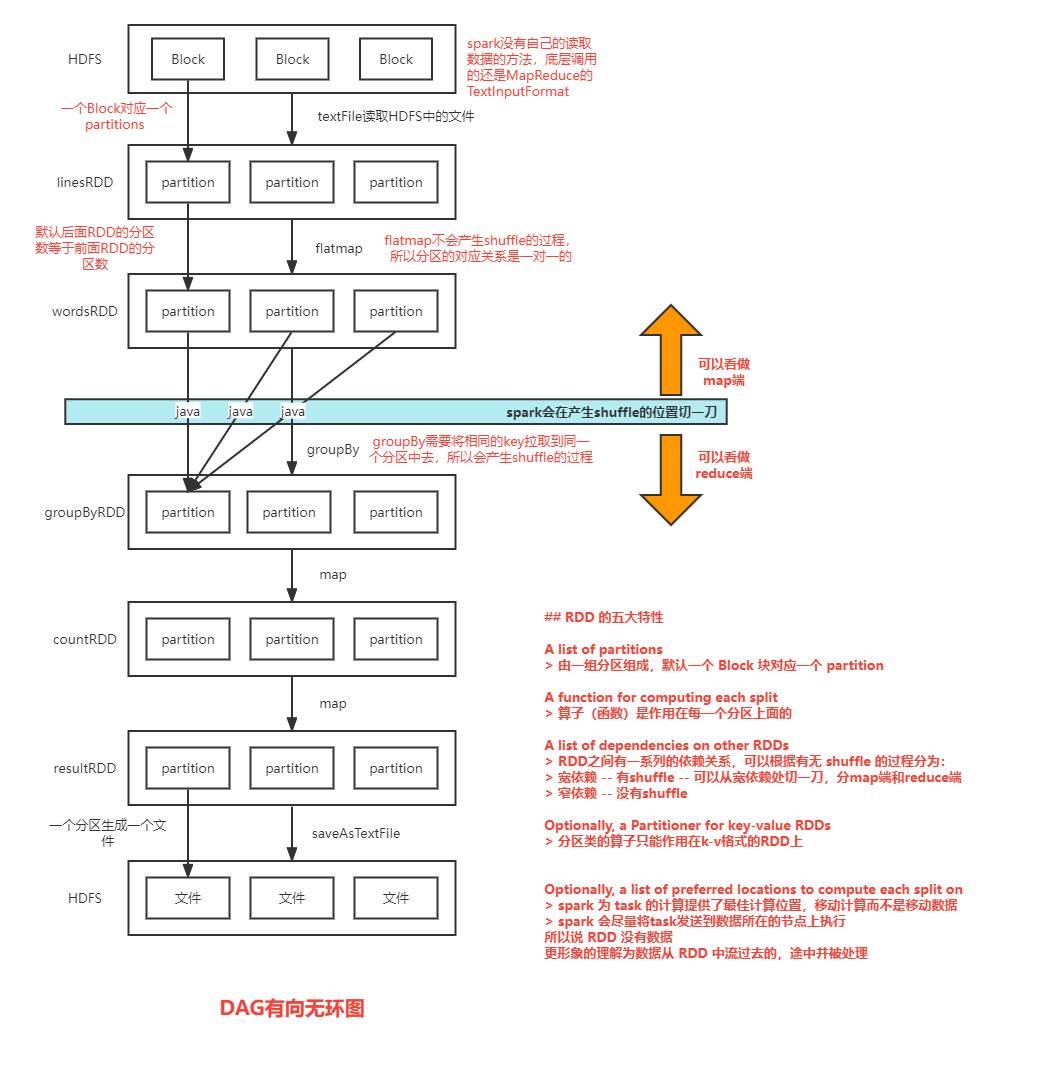
RDD的五大特性、spark WordCount 流程图
什么是 RDD
RDD 全称 ResilientDistributedDataset (弹性分布式数据集 )
RDD 仅为一个抽象的编程模型,RDD 默认没有数据
RDD 的五大特性
A list of partitions
由一组分区组成,默认一个 Block 块对应一个 partition
A function for computing each split
算子(函数)是作用在每一个分区上面的
A list of dependencies on other RDDs
RDD之间有一系列的依赖关系,可以根据有无 shuffle 的过程分为:
宽依赖 -- 有shuffle -- 可以从宽依赖处切一刀,分map端和reduce端
窄依赖 -- 没有shuffle
Optionally, a Partitioner for key-value RDDs
分区类的算子只能作用在k-v格式的RDD上
所有Bykey的算子
Optionally, a list of preferred locations to compute each split on
spark 为 task 的计算提供了最佳计算位置,移动计算而不是移动数据
spark 会尽量将task发送到数据所在的节点上执行
所以说 RDD 没有数据
更形象的理解为数据从 RDD 中流过去的,途中并被处理
spark WordCount 流程图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号