
spark简介、spark local 运行模式 环境搭建
目录
spark 的简介
什么是 spark ?
spark 与 MapReduce
spark 是 一个计算引擎,是用来代替 MapReduce 的
MapReduce 的优点:稳定
spark 的优点:快
Apache Spark is an open source cluster computing system that aims to make data analytics fast
both fast to run and fast to write
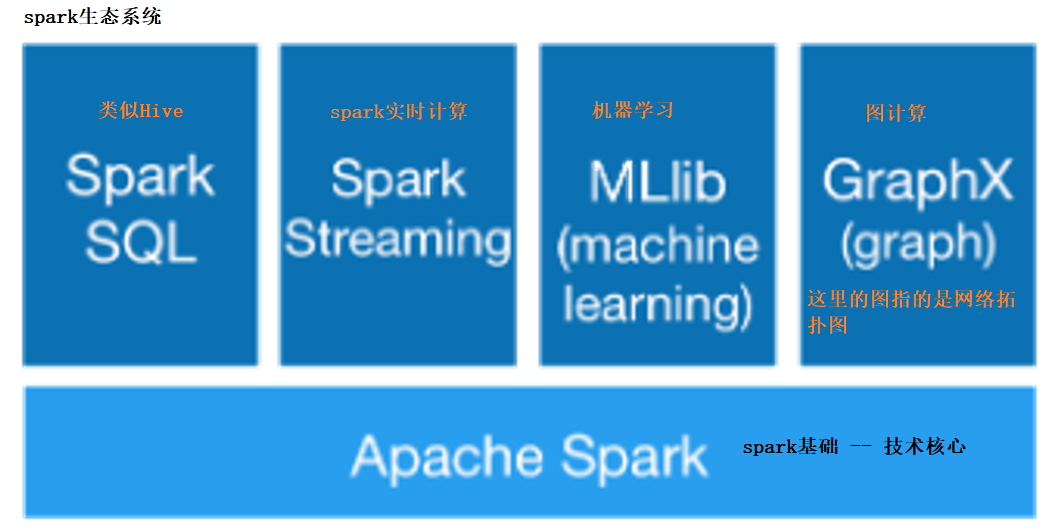
spark 技术栈
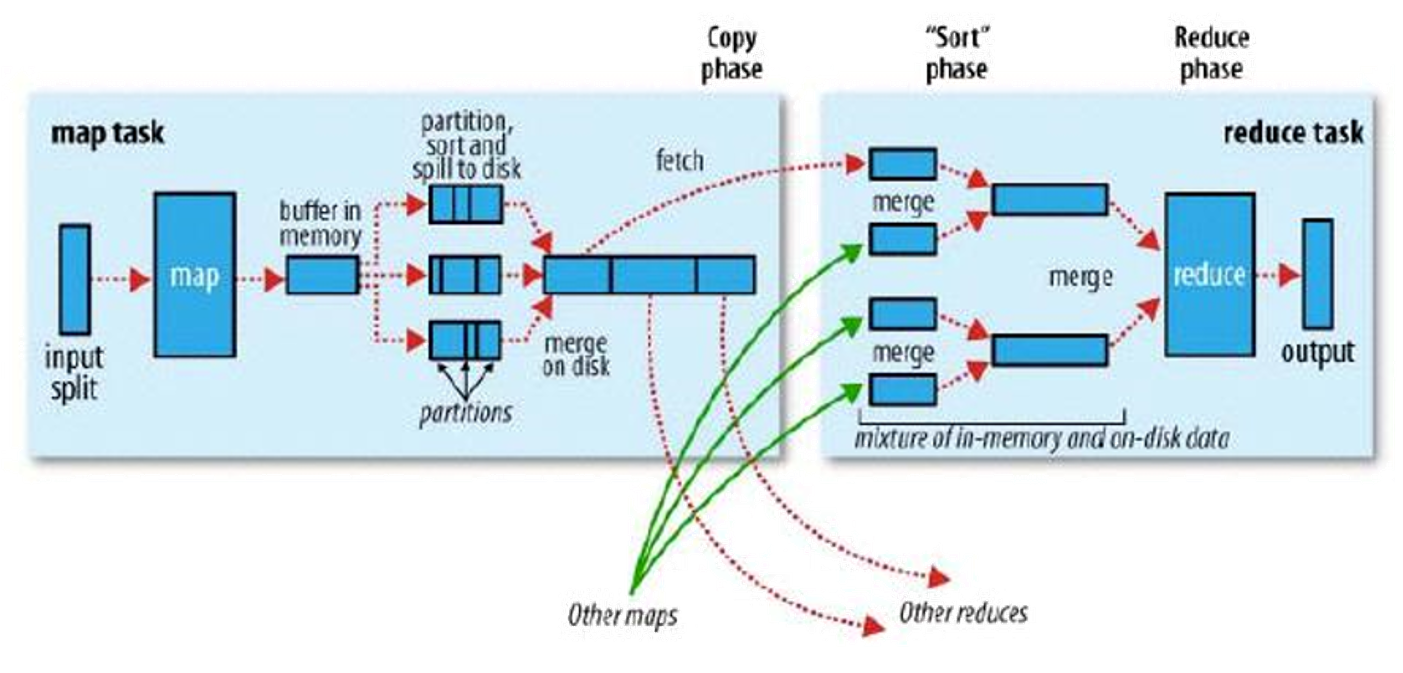
回顾 MapReduce 模型
spark 其实也是 MapReduce 的模型,但是 spark 在 MapReduce 之上做了很多的优化
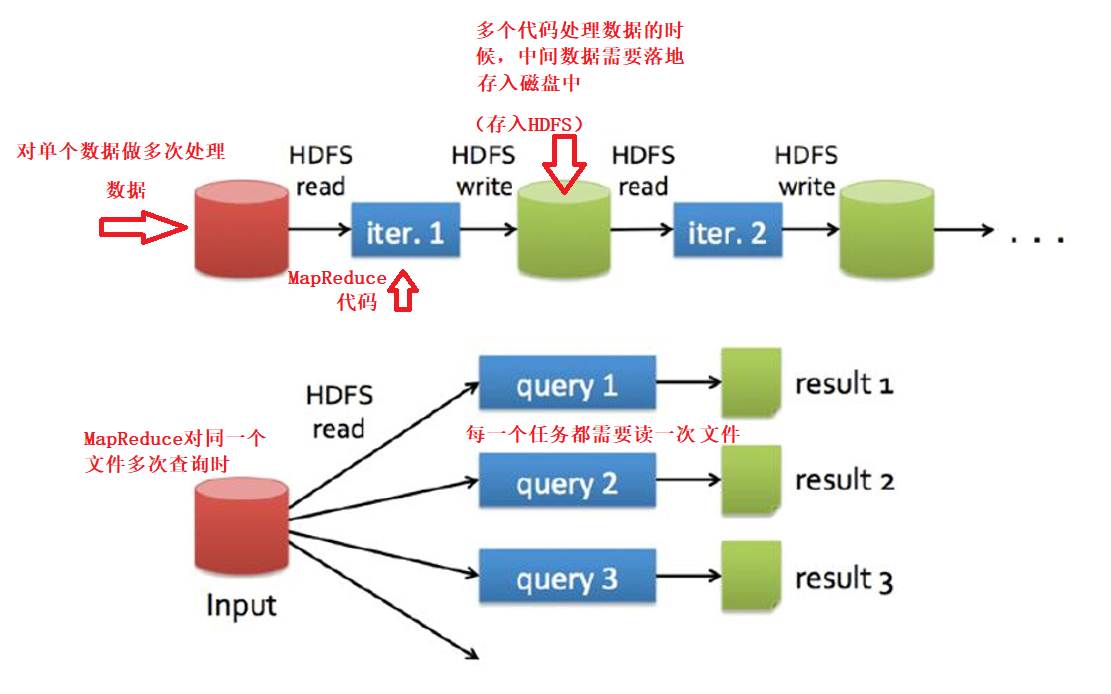
MapReduce 的共享数据慢
为什么慢???
额外的复制,序列化,磁盘IO开销
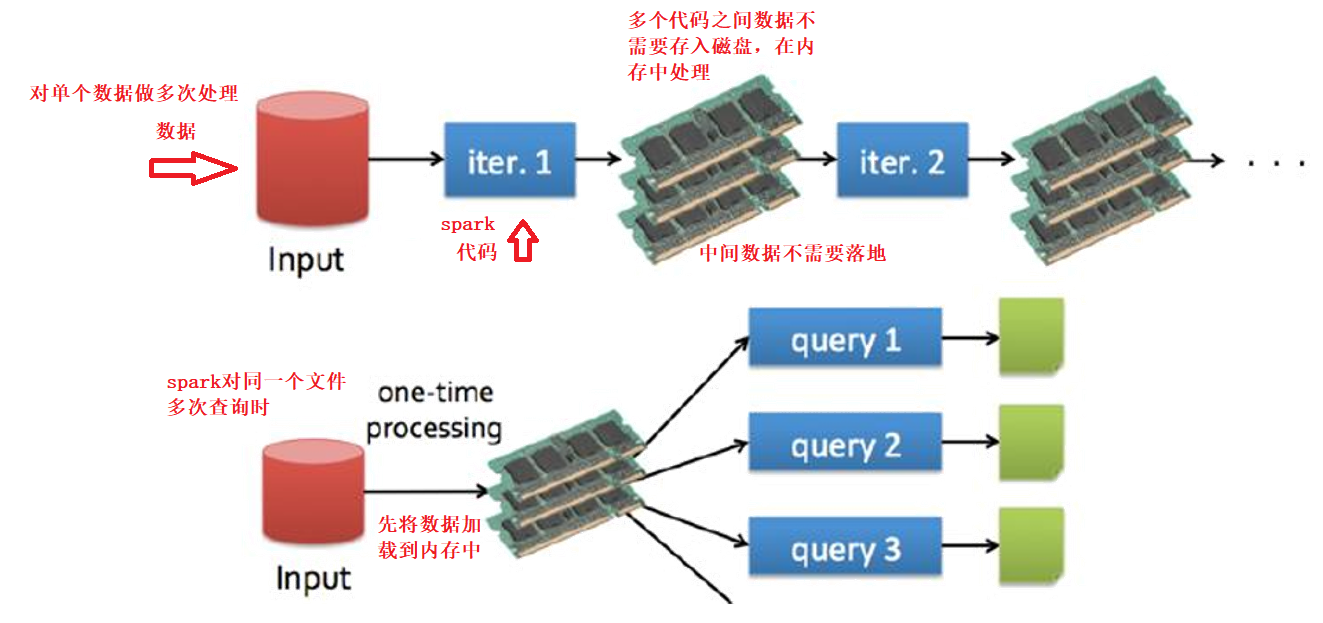
Spark的共享数据快
快只是因为内存计算?
当然还有DAG
Spark API
支持3种语言的API
Scala(很好)
Python(不错)
Java(...)
spark 的运行模式
有4种模式可以运行
Local -- 在IDEA中运行 -- 多用于测试
Standalone -- 独立集群模式 -- 独立的为 spark 搭建一个集群,运行 spark
Mesos -- 也是一个资源管理框架 -- 现在用的不多
YARN -- 最具前景
spark local 运行模式 环境搭建
新建一个 Maven 项目,项目名为 spark
添加 依赖 和 插件
在项目的 pom.xml 文件中添加
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
local 模式的代码示例 -- WordCount
package com.shujia.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 1、创建spark上下文环境
* SparkContext是spark代码的入口
* 这个步骤是固定的
*/
//spark配置文件对象,指定spark 运行常用的配置
val conf = new SparkConf()
//任务名
conf.setAppName("Demo1WordCount")
//指定运行模式,local:本地运行
conf.setMaster("local")
//创建上下文对象
val sc = new SparkContext(conf)
/**
* 1、读取文件, 读取hdfs中的文件
* textFile
* RDD: 弹性的分布式数据集 -- 可以理解为一个分布式的List集合
*
*/
val linesRDD: RDD[String] = sc.textFile("data/words")
/**
* 2、统计单词的数量
*
* flatMap: 在spark中叫做 算子 ,返回一个新的 RDD
*
*/
//1、将一行拆分成多行
val wordsRDD: RDD[String] = linesRDD.flatMap((line: String) => line.split(","))
/**
* groupBy: 按照指定的key分组 -- 在执行的底层会产生shuffle
*
* 迭代器和集合的区别
* 1、迭代器只能遍历一次
* 2、迭代器的数据没有完全在内存中,集合的数据完全保存在内存中
* 迭代器是一个拿取数据的入口,你边迭代的时候它边去取数据
*/
//3、按照单词分组
val groupByRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy((word: String) => word)
//4、统计单词的数量
val countRDD: RDD[(String, Int)] = groupByRDD.map {
case (word: String, words: Iterable[String]) =>
//单词的数量
val count: Int = words.size
//返回数据
(word, count)
}
//5、整理数据
val resultRDD: RDD[String] = countRDD.map {
case (word: String, count: Int) =>
s"$word\t$count"
}
/**
* 3、保存数据
*
* 指定的路径是一个目录,里面文件的数量和reduce的数量有关(和MapReduce一样)
* 输出路径不能存在
* 保存数据这一步需要在本地配置一下 Hadoop 的环境,不然这一步跑不了
*/
resultRDD.saveAsTextFile("data/word_count")
}
}
在本地配置 Hadoop 的环境
1、在任意盘符下解压 Hadoop 的安装包(hadoop-2.7.6.tar.gz)
我这里选择的是 F盘(我的软件安装盘符)
2、将 winutils.exe 工具放在解压完之后 Hadoop 的 bin 目录下
3、配置一下 Hadoop bin 目录的环境变量
winutils.exe 可以在 Windows 上提供 spark local 运行模式下所需的 Hadoop 虚拟环境
4、重启 IDEA

