
HBase过滤器
HBase过滤器
添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.4.6</version>
</dependency>
</dependencies>
过滤器
HBase 的基本 API,包括增、删、改、查等。
增、删都是相对简单的操作,与传统的 RDBMS 相比,这里的查询操作略显苍白,只能根据特性的行键进行查询(Get)或者根据行键的范围来查询(Scan)。
HBase 不仅提供了这些简单的查询,而且提供了更加高级的过滤器(Filter)来查询。
过滤器的两类参数
过滤器可以根据列族、列、版本等更多的条件来对数据进行过滤,
基于 HBase 本身提供的三维有序(行键,列,版本有序),这些过滤器可以高效地完成查询过滤的任务,带有过滤器条件的 RPC 查询请求会把过滤器分发到各个 RegionServer(这是一个服务端过滤器),这样也可以降低网络传输的压力。
使用过滤器至少需要两类参数:
一类是抽象的操作符,另一类是比较器
作用
- 过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端
- 过滤器的类型很多,但是可以分为两大类:
- 比较过滤器:可应用于rowkey、列簇、列、列值过滤器
- 专用过滤器:只能适用于特定的过滤器
比较过滤器
比较运算符
- LESS <
- LESS_OR_EQUAL <=
- EQUAL =
- NOT_EQUAL <>
- GREATER_OR_EQUAL >=
- GREATER >
- NO_OP 排除所有
- MUST_PASS_ALL ===> and
- MUST_PASS_ONE ===> or
常见的六大比较过滤器
BinaryComparator
按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator
通BinaryComparator,只是比较左端前缀的数据是否相同
NullComparator
判断给定的是否为空
BitComparator
按位比较
RegexStringComparator
提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator
判断提供的子串是否出现在中
示例代码
rowKey过滤器:RowFilter
通过RowFilter与BinaryComparator过滤比rowKey 1500100010小的所有值出来
@Test
// 通过RowFilter过滤比rowKey 1500100010 小的所有值出来
public void BinaryComparatorFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
BinaryComparator binaryComparator = new BinaryComparator(Bytes.toBytes(1500100010));
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.LESS, binaryComparator);
Scan scan = new Scan();
scan.setFilter(rowFilter);
ResultScanner scanner = students.getScanner(scan);
Result rs = scanner.next();
while (rs != null) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
int age = Bytes.toInt(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "\t" + name + "\t" + age + "\t" + gender + "\t" + clazz + "\t");
rs = scanner.next();
}
}
列簇过滤器:FamilyFilter
通过FamilyFilter与SubstringComparator查询列簇名包含in的所有列簇下面的数据
@Test
// 通过FamilyFilter查询列簇名包含in的所有列簇下面的数据
public void SubstringComparatorFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
SubstringComparator substringComparator = new SubstringComparator("in");
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, substringComparator);
Scan scan = new Scan();
scan.setFilter(familyFilter);
ResultScanner scanner = students.getScanner(scan);
Result rs = scanner.next();
while (rs != null) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
int age = Bytes.toInt(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "\t" + name + "\t" + age + "\t" + gender + "\t" + clazz + "\t");
rs = scanner.next();
}
}
通过FamilyFilter与 BinaryPrefixComparator 过滤出列簇以info开头的列簇下的所有数据
// 通过FamilyFilter与 BinaryPrefixComparator 过滤出列簇以info开头的所有列簇下的所有数据
@Test
public void BinaryPrefixComparatorFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
// 二进制前缀比较器
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("info".getBytes());
// FamilyFilter 作用于列簇的过滤器
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, binaryPrefixComparator);
Scan scan = new Scan();
scan.withStartRow("1500100001".getBytes());
scan.withStopRow("1500100011".getBytes());
// 通过setFilter方法设置过滤器
scan.setFilter(familyFilter);
ResultScanner scanner = students.getScanner(scan);
printRS(scanner);
}
列过滤器:QualifierFilter
通过QualifierFilter与SubstringComparator查询列名包含in的列的值
public void printRS(ResultScanner scanner) throws IOException {
for (Result rs : scanner) {
String rowkey = Bytes.toString(rs.getRow());
System.out.println("当前行的rowkey为:" + rowkey);
for (Cell cell : rs.listCells()) {
String family = Bytes.toString(CellUtil.cloneFamily(cell));
String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell));
byte[] bytes = CellUtil.cloneValue(cell);
if ("age".equals(qualifier)) {
int value = Bytes.toInt(bytes);
System.out.println(family + ":" + qualifier + "的值为" + value);
} else {
String value = Bytes.toString(bytes);
System.out.println(family + ":" + qualifier + "的值为" + value);
}
}
}
}
@Test
// 通过FamilyFilter查询列簇名包含in的所有列簇下面的数据
public void SubstringComparatorFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
SubstringComparator substringComparator = new SubstringComparator("in");
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL, substringComparator);
Scan scan = new Scan();
scan.setFilter(familyFilter);
ResultScanner scanner = students.getScanner(scan);
Result rs = scanner.next();
while (rs != null) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
int age = Bytes.toInt(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "\t" + name + "\t" + age + "\t" + gender + "\t" + clazz + "\t");
rs = scanner.next();
}
}
过滤出 列的名字 中 包含 "am" 所有的列 及列的值
// 过滤出 列的名字 中 包含 "am" 所有的列 及列的值
@Test
public void SubstringComparatorQualifierFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
SubstringComparator substringComparator = new SubstringComparator("am");
// 作用在列名上的过滤器
QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL, substringComparator);
Scan scan = new Scan();
scan.withStartRow("1500100001".getBytes());
scan.withStopRow("1500100011".getBytes());
// 通过setFilter方法设置过滤器
scan.setFilter(qualifierFilter);
ResultScanner scanner = students.getScanner(scan);
printRS(scanner);
}
列值过滤器:ValueFilter
通过ValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "张" 开头的学生
@Test
// 通过ValueFilter与BinaryPrefixComparator过滤出所有的cell中值以 "张" 开头的学生
public void BinaryPrefixComparatorFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
BinaryPrefixComparator binaryPrefixComparator = new BinaryPrefixComparator("张".getBytes());
ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, binaryPrefixComparator);
Scan scan = new Scan();
scan.setFilter(valueFilter);
ResultScanner scanner = students.getScanner(scan);
printRS(scanner);
}
过滤出文科的学生,只会返回clazz列,其他列的数据不符合条件,不会返回
// 过滤出文科的学生
// 只会返回clazz列,其他列的数据不符合条件,不会返回
@Test
public void RegexStringComparatorFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
// 使用正则表达式比较器
RegexStringComparator regexStringComparator = new RegexStringComparator("^文科.*");
// ValueFilter 会返回符合条件的cell,并不会返回整条数据
ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL, regexStringComparator);
Scan scan = new Scan();
scan.withStartRow("1500100001".getBytes());
scan.withStopRow("1500100011".getBytes());
// 通过setFilter方法设置过滤器
scan.setFilter(valueFilter);
ResultScanner scanner = students.getScanner(scan);
printRS(scanner);
}
专用过滤器
单列值过滤器:SingleColumnValueFilter
SingleColumnValueFilter会返回满足条件的cell所在行的所有cell的值(即会返回一行数据)
通过SingleColumnValueFilter与查询文科班所有学生信息
@Test
// 通过SingleColumnValueFilter与查询文科班所有学生信息
public void RegexStringComparatorFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"info".getBytes(),
"clazz".getBytes(),
CompareFilter.CompareOp.EQUAL,
new RegexStringComparator("^文科.*")
);
Scan scan = new Scan();
scan.setFilter(singleColumnValueFilter);
ResultScanner scanner = students.getScanner(scan);
Result rs = scanner.next();
while (rs != null) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
int age = Bytes.toInt(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "\t" + name + "\t" + age + "\t" + gender + "\t" + clazz + "\t");
rs = scanner.next();
}
}
列值排除过滤器:SingleColumnValueExcludeFilter
与SingleColumnValueFilter相反,会排除掉指定的列,其他的列全部返回
通过SingleColumnValueExcludeFilter与BinaryComparator查询文科一班所有学生信息,最终不返回clazz列
@Test
// 通过SingleColumnValueExcludeFilter与BinaryComparator查询文科一班所有学生信息,最终不返回clazz列
public void RegexStringComparatorExcludeFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter(
"info".getBytes(),
"clazz".getBytes(),
CompareFilter.CompareOp.EQUAL,
new BinaryComparator("文科一班".getBytes())
);
Scan scan = new Scan();
scan.setFilter(singleColumnValueExcludeFilter);
ResultScanner scanner = students.getScanner(scan);
Result rs = scanner.next();
while (rs != null) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
int age = Bytes.toInt(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
// clazz列为空
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "\t" + name + "\t" + age + "\t" + gender + "\t" + clazz + "\t");
rs = scanner.next();
}
}
rowkey前缀过滤器:PrefixFilter
通过PrefixFilter查询以150010008开头的所有前缀的rowkey
@Test
// 通过PrefixFilter查询以150010008开头的所有前缀的rowkey
public void PrefixFilterFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
PrefixFilter prefixFilter = new PrefixFilter("150010008".getBytes());
Scan scan = new Scan();
scan.setFilter(prefixFilter);
ResultScanner scanner = students.getScanner(scan);
Result rs = scanner.next();
while (rs != null) {
String id = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
int age = Bytes.toInt(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
// clazz列为空
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(id + "\t" + name + "\t" + age + "\t" + gender + "\t" + clazz + "\t");
rs = scanner.next();
}
}
分页过滤器PageFilter
通过PageFilter查询第三页的数据,每页10条
使用PageFilter分页效率比较低,每次都需要扫描前面的数据,直到扫描到所需要查的数据
可设计一个合理的rowkey来实现分页需求
@Test
// 通过PageFilter查询第三页的数据,每页10条
public void PageFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
int PageNum = 3;
int PageSize = 10;
Scan scan = new Scan();
if (PageNum == 1) {
scan.withStartRow("".getBytes());
//使用分页过滤器,实现数据的分页
PageFilter pageFilter = new PageFilter(PageSize);
scan.setFilter(pageFilter);
ResultScanner scanner = students.getScanner(scan);
printRS(scanner);
} else {
String current_page_start_rows = "";
int scanDatas = (PageNum - 1) * PageSize + 1;
PageFilter pageFilter = new PageFilter(scanDatas);
scan.setFilter(pageFilter);
ResultScanner scanner = students.getScanner(scan);
for (Result rs : scanner) {
current_page_start_rows = Bytes.toString(rs.getRow());
}
scan.withStartRow(current_page_start_rows.getBytes());
PageFilter pageFilter1 = new PageFilter(PageSize);
scan.setFilter(pageFilter1);
ResultScanner scanner1 = students.getScanner(scan);
printRS(scanner1);
}
}
通过合理的设置rowkey来实现分页功能
@Test
// 通过合理的设置rowkey来实现分页功能,提高效率
public void PageFilterTest2() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
int PageSize = 10;
int PageNum = 3;
int baseId = 1500100000;
int start_row = baseId + (PageNum - 1) * PageSize + 1;
int end_row = start_row + PageSize;
Scan scan = new Scan();
scan.withStartRow(String.valueOf(start_row).getBytes());
scan.withStopRow(String.valueOf(end_row).getBytes());
ResultScanner scanner = students.getScanner(scan);
printRS(scanner);
}
多过滤器综合查询
查询文科班中的学生中学号以150010008开头并且年龄小于23的学生信息
@Test
// 查询文科班中的学生中学号以150010008开头并且年龄小于23的学生信息
public void FilterListFilter() throws IOException {
Table students = conn.getTable(TableName.valueOf("students"));
Scan scan = new Scan();
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(
"info".getBytes()
, "clazz".getBytes()
, CompareFilter.CompareOp.EQUAL
, new RegexStringComparator("^文科.*"));
PrefixFilter prefixFilter = new PrefixFilter("150010008".getBytes());
SingleColumnValueFilter singleColumnValueFilter1 = new SingleColumnValueFilter(
"info".getBytes()
, "age".getBytes()
, CompareFilter.CompareOp.LESS
, new BinaryComparator(Bytes.toBytes(23)));
FilterList filterList = new FilterList();
filterList.addFilter(singleColumnValueFilter);
filterList.addFilter(prefixFilter);
filterList.addFilter(singleColumnValueFilter1);
scan.setFilter(filterList);
ResultScanner scanner = students.getScanner(scan);
printRS(scanner);
}
HBase过滤器 需求示例
开发中常用:
BinaryComparator:二进制比较器
BinaryPrefixComparator:前缀二进制比较器
RegexStringComparator :支持正则表达式的值比较
SubStringComparator:用于监测一个子串是否存在于值中,并且不区分大小写
rowKey过滤器:RowFilter
单列值过滤器:SingleColumnValueFilter
rowkey前缀过滤器:PrefixFilter
多过滤器综合查询:FilterList
package com.shujia;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class Demo04Filter {
Connection conn;
Table stu;
public ResultScanner getScannerWithFilter(Filter filter) throws IOException {
Scan scan = new Scan();
scan.setFilter(filter);
return stu.getScanner(scan);
}
public void printScanner(Filter filter) throws IOException {
for (Result rs : getScannerWithFilter(filter)) {
String rk = Bytes.toString(rs.getRow());
String name = Bytes.toString(rs.getValue("info".getBytes(), "name".getBytes()));
String age = Bytes.toString(rs.getValue("info".getBytes(), "age".getBytes()));
String gender = Bytes.toString(rs.getValue("info".getBytes(), "gender".getBytes()));
String clazz = Bytes.toString(rs.getValue("info".getBytes(), "clazz".getBytes()));
System.out.println(rk + "," + name + "," + age + "," + gender + "," + clazz);
}
}
// 使用CellUtil进行打印
public void printScannerWithCellUtil(Filter filter) throws IOException {
for (Result rs : getScannerWithFilter(filter)) {
for (Cell cell : rs.listCells()) {
String rowkey = Bytes.toString(CellUtil.cloneRow(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(rowkey + "," + value);
}
}
}
@Before
public void init() throws IOException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");
conn = ConnectionFactory.createConnection(conf);
stu = conn.getTable(TableName.valueOf("stu"));
}
@Test
// 过滤出Rowkey(id)中 包含8的数据
public void RowFilterWithSubString() throws IOException {
SubstringComparator comparator = new SubstringComparator("8");
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, comparator);
printScanner(rowFilter);
}
@Test
// 过滤出 列簇名为cf2下的所有列的数据
public void FamilyFilterWithCom() throws IOException {
Scan scan = new Scan();
FamilyFilter familyFilter = new FamilyFilter(CompareFilter.CompareOp.EQUAL,
new BinaryComparator("cf2".getBytes()));
scan.setFilter(familyFilter);
Table test2 = conn.getTable(TableName.valueOf("test2"));
ResultScanner sc = test2.getScanner(scan);
for (Result rs : sc) {
for (Cell cell : rs.listCells()) {
String rowkey = Bytes.toString(CellUtil.cloneRow(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println(rowkey + "," + value);
}
}
}
@Test
// stu表中列名包含a的所有的列的数据,使用正则比较器
public void QualifierFilterWithRegex() throws IOException {
QualifierFilter qualifierFilter = new QualifierFilter(CompareFilter.CompareOp.EQUAL,
new RegexStringComparator(".*a.*"));
printScannerWithCellUtil(qualifierFilter);
}
@Test
// 过滤出 数据中包含 文 的所有数据
public void ValueFilterWithSubString() throws IOException {
ValueFilter valueFilter = new ValueFilter(CompareFilter.CompareOp.EQUAL,
new SubstringComparator("文"));
printScannerWithCellUtil(valueFilter);
}
@Test
// 过滤出班级是 文科班 的学生的所有信息
public void SingleColumnValueFilterWithBinaryPrefix() throws IOException {
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("info".getBytes()
, "clazz".getBytes()
, CompareFilter.CompareOp.EQUAL
, new BinaryPrefixComparator("文科".getBytes()));
printScanner(singleColumnValueFilter);
}
@Test
// 过滤出班级是 文科班 的学生的所有信息,最终结果没有 clazz 列
public void SingleColumnValueExcludeFilterWithBinaryPrefix() throws IOException {
SingleColumnValueExcludeFilter singleColumnValueExcludeFilter = new SingleColumnValueExcludeFilter("info".getBytes()
, "clazz".getBytes()
, CompareFilter.CompareOp.EQUAL
, new BinaryPrefixComparator("文科".getBytes()));
printScanner(singleColumnValueExcludeFilter);
}
@Test
// 过滤出年龄是 奇数 的学生的所有信息
public void SingleColumnValueFilterWithRegex() throws IOException {
SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter("info".getBytes()
, "age".getBytes()
, CompareFilter.CompareOp.EQUAL
, new RegexStringComparator("^[0-9]{0,1}[13579]$"));
printScanner(singleColumnValueFilter);
}
@Test
// 查询以150010008开头的所有前缀的rowkey
public void PrefixFilter() throws IOException {
// 第一种方式
PrefixFilter prefixFilter = new PrefixFilter("150010008".getBytes());
printScanner(prefixFilter);
System.out.println("**********************************");
// 第二种方式
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL,
new BinaryPrefixComparator("150010008".getBytes()));
printScanner(rowFilter);
}
@Test
// 过滤出 理科班 中的 女生 年龄为奇数 的学生的所有信息
public void CombineFilter() throws IOException {
SingleColumnValueFilter filter1 = new SingleColumnValueFilter("info".getBytes()
, "clazz".getBytes()
, CompareFilter.CompareOp.EQUAL
, new BinaryPrefixComparator("理科".getBytes()));
SingleColumnValueExcludeFilter filter2 = new SingleColumnValueExcludeFilter("info".getBytes()
, "gender".getBytes()
, CompareFilter.CompareOp.EQUAL
, "女".getBytes());
SingleColumnValueFilter filter3 = new SingleColumnValueFilter("info".getBytes()
, "age".getBytes()
, CompareFilter.CompareOp.EQUAL
, new RegexStringComparator("^[0-9]{0,1}[13579]$"));
/**
* MUST_PASS_ALL ===> and
* MUST_PASS_ONE ===> or
*/
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ONE);
filterList.addFilter(filter1);
filterList.addFilter(filter2);
filterList.addFilter(filter3);
printScanner(filterList);
}
@After
public void close() throws IOException {
conn.close();
}
}
Bloom Filter 布隆过滤器
通过 时间复杂度 和 空间复杂度 来判断一个算法的好坏
Bloom Filter 有一个特点,能100%确定一个元素不在一个集合中,但是不能100%确定一个元素在一个集合中
Bloom Filter(布隆过滤器)是1970年由布隆提出的。它实际上是一个很长的二进制向量(说白了就是一个byte[])和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
它的用法其实是很容易理解的,我们拿个HBase中应用的例子来说下,我们已经知道rowKey存放在HFile中,那么为了从一系列的HFile中查询某个rowkey,我们就可以通过 Bloom Filter 快速判断 rowkey 是否在这个HFile中,从而过滤掉大部分的HFile,减少需要扫描的Block。
Bloom Filter 工作原理
BloomFilter对于HBase的随机读性能至关重要,对于get操作以及部分scan操作可以剔除掉不会用到的HFile文件,减少实际IO次数,提高随机读性能。在此简单地介绍一下Bloom Filter的工作原理,Bloom Filter使用位数组来实现过滤,初始状态下位数组每一位都为0,如下图所示:

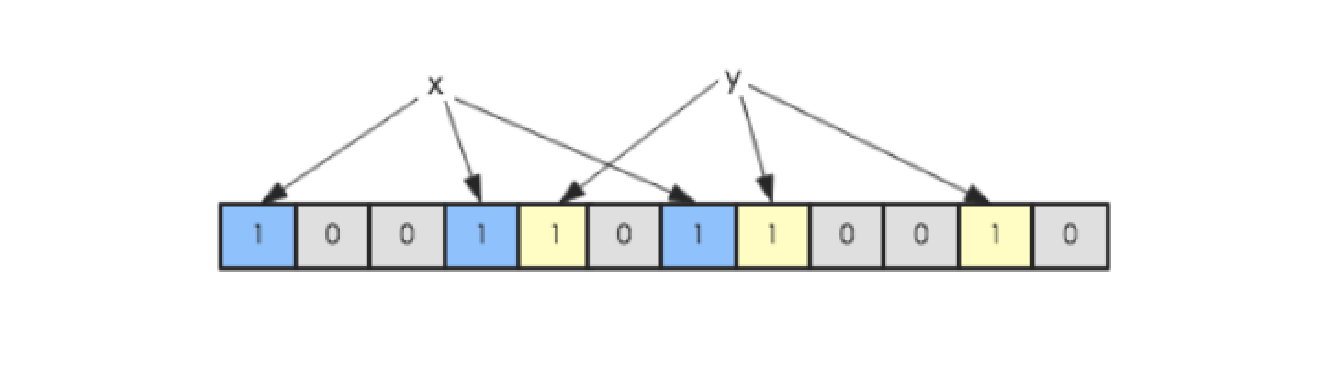
假如此时有一个集合S = {x1, x2, … xn},Bloom Filter使用k个独立的hash函数,分别将集合中的每一个元素映射到{1,…,m}的范围(这里的m是上面byte[]的长度,这个映射的过程就相当于hash取余)。对于任何一个元素,被映射到的数字作为对应的位数组的索引,该位会被置为1。比如元素x1被hash函数映射到数字8,那么位数组的第8位就会被置为1。下图中集合S只有两个元素x和y,分别被3个hash函数进行映射,映射到的位置分别为(0,3,6)和(4,7,10),对应的位会被置为1:
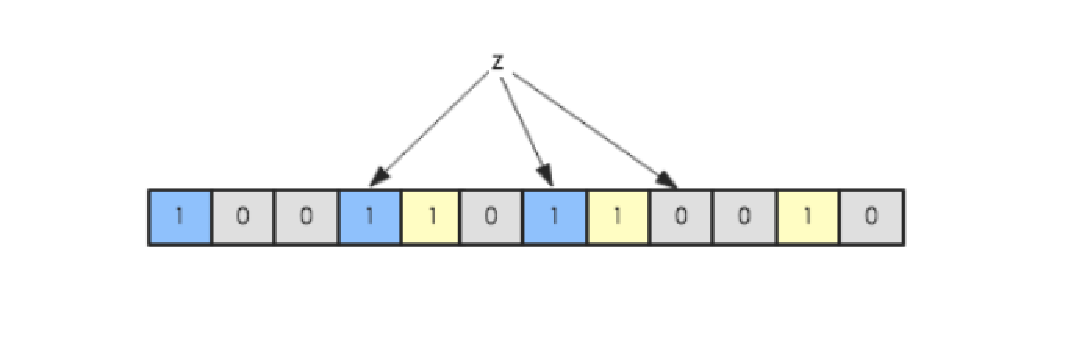
现在假如要判断另一个元素是否是在此集合中,只需要被这3个hash函数进行映射,查看对应的位置是否有0存在,如果有的话,表示此元素肯定不存在于这个集合,否则有可能存在。下图所示就表示z肯定不在集合{x,y}中:
从上面的内容我们可以得知,Bloom Filter有两个很重要的参数
哈希函数个数
位数组的大小
Bloom Filter 在HBase中的应用
HFile 中和 Bloom Filter 相关的Block,
Scanned Block Section(扫描HFile时被读取):Bloom Block
Bloom Block -其实就是- 二进制字节数组
Load-on-open-section(regionServer启动时加载到内存):BloomFilter Meta Block、Bloom Index Block
-
Bloom Block:Bloom数据块,存储Bloom的位数组
-
Bloom Index Block:Bloom数据块的索引
-
BloomFilter Meta Block:从HFile角度看bloom数据块的一些元数据信息,大小个数等等。
HBase中每个HFile都有对应的位数组,KeyValue在写入HFile时会先经过几个hash函数的映射,映射后将对应的数组位改为1,get请求进来之后再进行hash映射,如果在对应数组位上存在0,说明该get请求查询的数据不在该HFile中。
HFile中的Bloom Block中存储的就是上面说得位数组,当HFile很大时,Data Block 就会很多,同时KeyValue也会很多,需要映射入位数组的rowKey也会很多,所以为了保证准确率,位数组就会相应越大,那Bloom Block也会越大,为了解决这个问题就出现了Bloom Index Block,一个HFile中有多个Bloom Block(位数组),根据rowKey拆分,一部分连续的Key使用一个位数组。这样查询rowKey就要先经过Bloom Index Block(在内存中)定位到Bloom Block,再把Bloom Block加载到内存,进行过滤。

