
操作HBase的方式、HBase Shell的常用基本操作、hbase在hdfs上的数据存储位置、hbase中的regions(分区)、hbase中的数据存放顺序
操作HBase的方式
HBase 自带的 shell
Hive 中使用外部表
MapReduce
Phoenix
Java API -- 最常用
HBase shell 的常用基本操作
// 进入
hbase shell
// 退出
exit在 HBase shell 中一行命令的结束不需要以 ; 结尾,这一点和 MySQL、hive 不同
在 HBase shell 中 Backspace 键是删除光标后面的,想要删除光标前面的需要使用
Ctrl+Backspacehttps://blog.csdn.net/vbirdbest/article/details/88236575 -- HBaseShell命令大全
创建表
create '表名','列族名'建表时指定命名空间 -- 在表名前指定,以 : 分隔
例如 'namespace:表名'
可以模仿列族的格式(通过 desc 查看表结构),在建表的时候添加对列族的设置
例如 在建表的时候添加 版本属性
create '表名',{NAME => '列族名',VERSIONS => '版本数'}若在建表的时候需要指定多个列族,多个列族之间用 , 隔开
如果 '表名' 中 不指定命名空间,则默认在default命名空间
示例 创建一个User表,并且有一个info列族
create 'User','info'
查看所有表
listlist可以查看除 hbase 命名空间 下的所有表
或者使用 HBASE 的 web 界面
查看所有的命名空间(类似 show databases )
命名空间类似于之前的数据库的概念
list_namespace
创建命名空间(类似 create database )
create_namespace '库名'
查看命名空间下的表
list_namespace_tables '库名'
删除表
因为在hbase中表是有状态的
在删除表之前需要先禁用表
disable '库名:表名'同理 开启表
enable '库名:表名'删除表
drop '库名:表名'
向表中插入数据
语法:put 'namespace:table','rowkey','列族:列名','value'向 hbase 中插入中文的话会出现乱码,因为 hbase 存储数据是按照
byte[]去存的所以 hbase 中 可以存储 任意类型
例如
put 'test','000','info:name','zhaosi'
查询表中数据
语法:get '表名','rowkey'get 查看的是最新的数据
例如
get 'test','001'
在 hbase 中每个数据有多个版本
查看数据的多个版本
get '表名','rowkey',{COLUMN => '列族名',VERSIONS => 版本数}如何区分表中有多少数据 -- 根据 rowkey
修改表中数据
再插入一次数据进行覆盖即可
帮助命令
命令 help
查看命令如何使用
查看表结构
desc '表名'主要查看列族
删除表中数据
delete '表名','rowkey','列族:列名'如果不指定列名,会将列族中所有数据都删除
如果指定 rowkey 中的某个列的数据有几次修改,它会删除最近的一次修改
注意在hbase中删除数据的时候,其实HBase不是真的直接把数据删除掉,而是给某个列设置一个标志,然后查询数据的时候,有这个标志的数据,就不显示出来,
清空表
truncate '表名'会导致表的预分区被重置成一个分区
删除指定的列族
alter '表名','delete' => '列族名'
执行此命令 会更新所有的
regions(分区)
增加新的列族
alter '表名', NAME => '列族名'
扫描所有数据
在 hbase 中查看数据有两种方式
get -- 获取指定rowkey的数据
scan -- 获取指定rowkey范围的数据、或全表的数据
扫描全表数据
scan '表名'注意 在 hbase中 的数据通常都非常大,不建议全表扫描
扫描指定rowkey范围的数据
scan '表名', {STARTROW => '开始rowkey', ENDROW => '结束rowkey'}scan中也可以使用limit
例如
scan '表名',{LIMIT => 显示数量}
统计表中数据量
count '表名'其中有两个参数
count '表名', {INTERVAL => intervalNum, CACHE => cacheNum}INTERVAL设置多少行显示一次及对应的rowkey,默认1000
CACHE每次去取的缓存区大小,默认是10
调整该参数可提高查询速度
查看表是否存在
exists '表名'
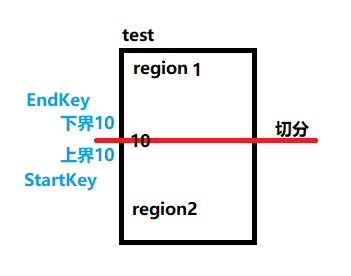
手动切分表来生成多个regions
split '表名','rowkey'就会按照 指定的 rowkey 切分这张表
例如 split 'test','10'
将 test 表 按10 切分,生成两个region
hbase:meta --- 存储表的元数据的 例如 region 的范围
hbase:namespace --- 存储命名空间的
hbase 在 hdfs 上的数据存储位置
默认在 hdfs
/hbase/data/下
hbase 中的 regions(分区)
hbase 中的表 默认 只有 一个 region
region 其实就是 保存一段连续的 rowkey
当表达到一定大小的时候就会将表进行切分,将之变成两个分区
为什么要进行切分呢??
可以将数据放在不同的 HRegionServer 上面 ,实现负载均衡
hbase 中的 数据存放 顺序
按照 rowkey 字典升序
在hbase中有个概念叫三维有序
第一维 -- rowkey 字典升序
第二维 -- 列族名+列名 字典升序
第三维 -- 按照版本的时间戳 自然降序

