Hive 中的wordCount、Hive 开窗函数
Hive 中的wordCount、Hive 开窗函数
- Hive 中的wordCount、Hive 开窗函数
- Hive 中的wordCount
- Hive 开窗函数
- 测试数据
- 建表语句
- 1、row_number:无并列排名
- 2、dense_rank:有并列排名,并且依次递增
- 3、rank:有并列排名,不依次递增
- 4、percent_rank:(rank的结果-1)/(分区内数据的个数-1)
- 5、cume_dist:计算某个窗口或分区中某个值的累积分布。
- 6、NTILE(n):对分区内数据再分成n组,然后打上组号
- 7、max、min、avg、count、sum:基于每个partition分区内的数据做对应的计算
- 8、窗口帧:用于从分区中选择指定的多条记录,供窗口函数处理
- 用法示例
- 9、LAG(col,n):往前第n行数据
- 10、LEAD(col,n):往后第n行数据
- 11、FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
- 12、LAST_VALUE:取分组内排序后,截止到当前行,最后一个值,对于并列的排名,取最后一个
- 用法示例
Hive 中的wordCount
create table words(
words string
)row format delimited fields terminated by '|';
// 数据
hello,java,hello,java,scala,python
hbase,hadoop,hadoop,hdfs,hive,hive
hbase,hadoop,hadoop,hdfs,hive,hive
select word,count(*) from (select explode(split(words,',')) word from words) a group by a.word;
// 结果
hadoop 4
hbase 2
hdfs 2
hello 2
hive 4
java 2
python 1
scala 1
Hive 开窗函数
好像给每一份数据 开一扇窗户 所以叫开窗函数
在sql中有一类函数叫做聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时我们便引入了窗口函数.
over (partition by … order by … )中的 partition by 分区并不是hive中分区表中的分区,他只是将select语句查询的结果做一个分区处理
测试数据
111,69,class1,department1
112,80,class1,department1
113,74,class1,department1
114,94,class1,department1
115,93,class1,department1
121,74,class2,department1
122,86,class2,department1
123,78,class2,department1
124,70,class2,department1
211,93,class1,department2
212,83,class1,department2
213,94,class1,department2
214,94,class1,department2
215,82,class1,department2
216,74,class1,department2
221,99,class2,department2
222,78,class2,department2
223,74,class2,department2
224,80,class2,department2
225,85,class2,department2
建表语句
create table new_score(
id int
,score int
,clazz string
,department string
) row format delimited fields terminated by ",";
1、row_number:无并列排名
用法: select xxxx, row_number() over(partition by 分组字段 order by 排序字段 desc) as rn from tb group by xxxx
2、dense_rank:有并列排名,并且依次递增
3、rank:有并列排名,不依次递增
4、percent_rank:(rank的结果-1)/(分区内数据的个数-1)
5、cume_dist:计算某个窗口或分区中某个值的累积分布。
假定升序排序,则使用以下公式确定累积分布: 小于等于当前值x的行数 / 窗口或partition分区内的总行数。其中 x 等于 order by 子句中指定的列的当前行中的值。
6、NTILE(n):对分区内数据再分成n组,然后打上组号
按照给定的 n 进行分组,每个组分一个数据直到分完
7、max、min、avg、count、sum:基于每个partition分区内的数据做对应的计算

8、窗口帧:用于从分区中选择指定的多条记录,供窗口函数处理
Hive 提供了两种定义窗口帧的形式:
ROWS和RANGE。两种类型都需要配置上界和下界。例如,
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW表示选择分区起始记录到当前记录的所有行;
SUM(close) RANGE BETWEEN 100 PRECEDING AND 200 FOLLOWING则通过 字段差值 来进行选择。如当前行的 close 字段值是 200,那么这个窗口帧的定义就会选择分区中 close 字段值落在 100 至 400 区间的记录。
以下是所有可能的窗口帧定义组合。
如果没有定义窗口帧,则默认为
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。只能运用在max、min、avg、count、sum、FIRST_VALUE、LAST_VALUE这几个窗口函数上
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING) (ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING) (ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING range between 3 PRECEDING and 11 FOLLOWING//窗口帧的另一种写法 SELECT id ,score ,clazz ,SUM(score) OVER w as sum_w ,round(avg(score) OVER w,3) as avg_w ,count(score) OVER w as cnt_w FROM new_score WINDOW w AS (PARTITION BY clazz ORDER BY score rows between 2 PRECEDING and 2 FOLLOWING);111 69 class1 217 72.333 3 113 74 class1 297 74.25 4 216 74 class1 379 75.8 5 112 80 class1 393 78.6 5 215 82 class1 412 82.4 5 212 83 class1 431 86.2 5 211 93 class1 445 89.0 5 115 93 class1 457 91.4 5 213 94 class1 468 93.6 5 114 94 class1 375 93.75 4 214 94 class1 282 94.0 3 124 70 class2 218 72.667 3 121 74 class2 296 74.0 4 223 74 class2 374 74.8 5 222 78 class2 384 76.8 5 123 78 class2 395 79.0 5 224 80 class2 407 81.4 5 225 85 class2 428 85.6 5 122 86 class2 350 87.5 4 221 99 class2 270 90.0 3
用法示例
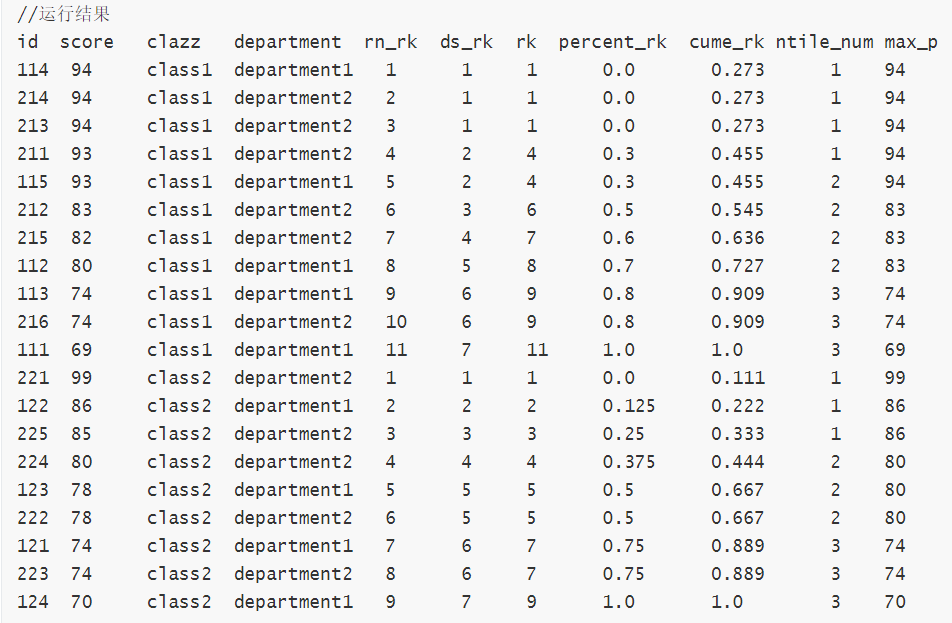
select id
,score
,clazz
,department
,row_number() over (partition by clazz order by score desc) as rn_rk
,dense_rank() over (partition by clazz order by score desc) as dense_rk
,rank() over (partition by clazz order by score desc) as rk
,percent_rank() over (partition by clazz order by score desc) as percent_rk
,round(cume_dist() over (partition by clazz order by score desc),3) as cume_rk
,NTILE(3) over (partition by clazz order by score desc) as ntile_num
,max(score) over (partition by clazz order by score desc range between 3 PRECEDING and 11 FOLLOWING) as max_p
from new_score;
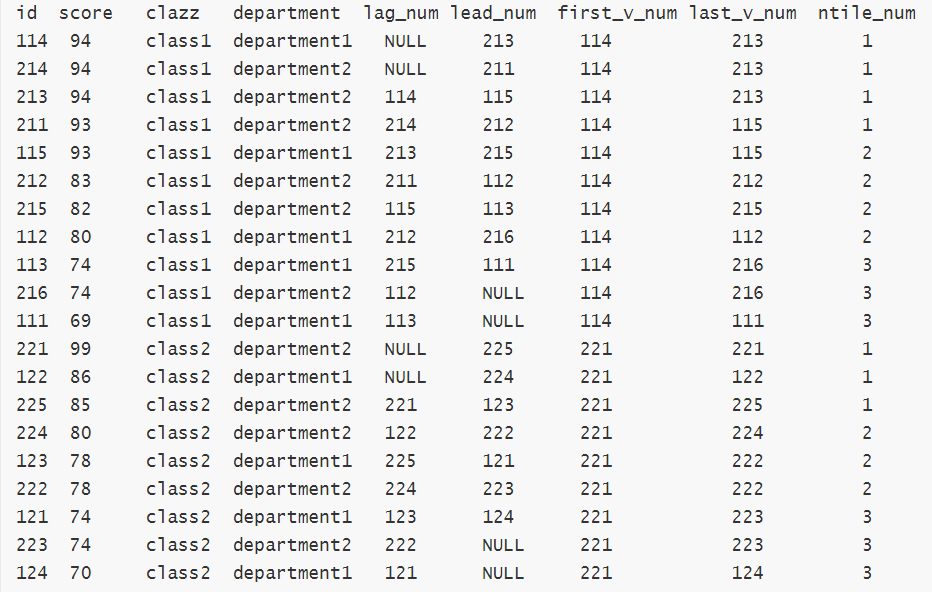
9、LAG(col,n):往前第n行数据
10、LEAD(col,n):往后第n行数据
11、FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
12、LAST_VALUE:取分组内排序后,截止到当前行,最后一个值,对于并列的排名,取最后一个
用法示例
select id
,score
,clazz
,department
,lag(id,2) over (partition by clazz order by score desc) as lag_num
,LEAD(id,2) over (partition by clazz order by score desc) as lead_num
,FIRST_VALUE(id) over (partition by clazz order by score desc) as first_v_num
,LAST_VALUE(id) over (partition by clazz order by score desc) as last_v_num
,NTILE(3) over (partition by clazz order by score desc) as ntile_num
from new_score;