


通过rz实现Xftp的功能、如何查看该进程是什么进程、Hive的架构图、Hive的8道小练习、在hive中操作hdfs的命令格式、Hive中的数据在hdfs上的默认存储位置
通过rz实现Xftp的功能
yum install lrzsz安装完毕之后就可以直接拖文件进Linux了
如何查看该进程是什么进程
ps -aux | grep 进程号Hive的架构图
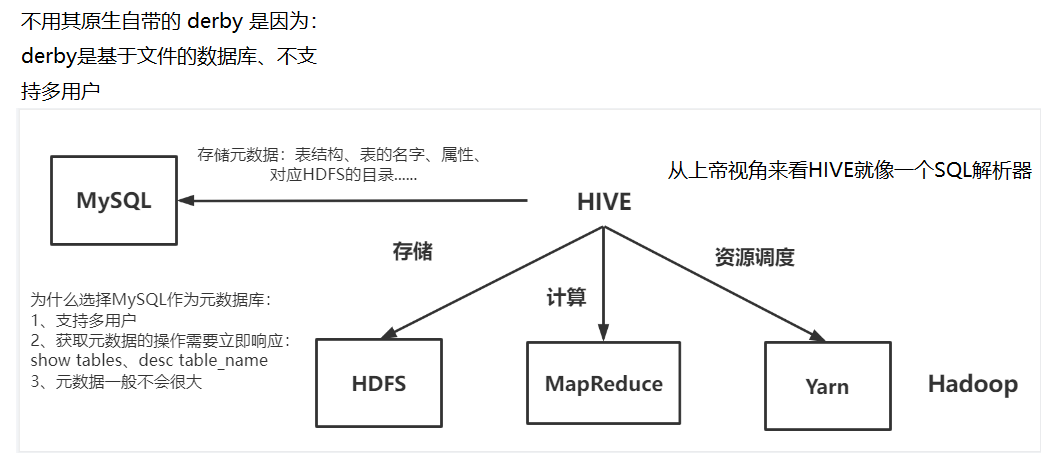
Hive的8道小练习
#写在hive中的SQL最好都要带上limit,因为是大数据嘛
#如果有分组,那么select中的字段必须要出现在group by中(分组之后查询的字段:分组字段、聚合函数)
#做除法的时候,要考虑结果会不会出现小数
1、模仿建表语句,创建subject表,并使用hdfs dfs -put 命令加载数据
create table subject(
subject_id bigint comment '科目id',
subject_name string comment '科目名称'
) comment '科目表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
2、查询学生分数(输出:学号,姓名,班级,科目id,科目名称,成绩)
select t1.id
,t1.name
,t1.clazz
,t2.score_id
,t3.subject_name
,t2.score
from students t1
left join score t2
on t1.id = t2.id
left join subject t3
on t2.score_id = t3.subject_id
limit 10
;
3、查询学生总分(输出:学号,姓名,班级,总分)
// 第一种方式
select t1.id
,t1.name
,t1.clazz
,sum(t2.score) as sum_score
from students t1
left join score t2
on t1.id = t2.id
group by t1.id,t1.name,t1.clazz
limit 10;
// 第二种方式 -- 逻辑更优
select t1.id
,t1.name
,t1.clazz
,t2.sum_score
from students t1
left join (
select id
,sum(score) as sum_score
from score
group by id
) t2 on t1.id = t2.id
limit 10;
4、查询全年级总分排名前三(不分文理科)的学生(输出:学号,姓名,班级,总分)
select t1.id
,t1.name
,t1.clazz
,t2.sum_score
from students t1
left join (
select id
,sum(score) as sum_score
from score
group by id
) t2 on t1.id = t2.id
order by t2.sum_score desc
limit 3;
5、查询文科一班学生总分排名前10的学生(输出:学号,姓名,班级,总分)
select t1.id
,t1.name
,'文科一班' as clazz
,t2.sum_score
from (
select id
,name
from students
where clazz = '文科一班'
) t1 left join (
select id
,sum(score) as sum_score
from score
group by id
) t2 on t1.id = t2.id
order by t2.sum_score desc
limit 10;
6、查询每个班级学生总分的平均成绩(输出:班级,平均分)
--做除法的时候,要考虑结果会不会出现小数
select t1.clazz
,round(avg(t2.sum_score),2) as clazz_avg_sum_score
from students t1
left join (
select id
,sum(score) as sum_score
from score
group by id
) t2 on t1.id = t2.id
group by t1.clazz
;
7、查询每个班级的最高总分(输出:班级,总分)
select t1.clazz
,max(t2.sum_score) as clazz_max_sum_score
from students t1
left join (
select id
,sum(score) as sum_score
from score
group by id
) t2 on t1.id = t2.id
group by t1.clazz
;
8、(思考)查询每个班级总分排名前三的学生(输出:学号,姓名,班级,总分)
窗口函数(开窗函数):row_number()
select tt1.id
,tt1.name
,tt1.clazz
,tt1.sum_score
,tt1.rn
from (
select t1.id
,t1.name
,t1.clazz
,t2.sum_score
,row_number() over (partition by clazz order by t2.sum_score desc) as rn
from students t1
left join (
select id
,sum(score) as sum_score
from score
group by id
) t2 on t1.id = t2.id
) tt1 where tt1.rn <= 3;在hive中操作hdfs的命令格式
#在hive中可以直接操作hdfs
#格式 -- 将hdfs的shell命令格式中的hdfs去掉即可
dfs -xxx;
#在hive中的命令与MySQL的类似,都是以 ; 表示一条命令的结束Hive中的数据在hdfs上的默认存储位置
/user/hive/warehouse/
