


Combiner编程、reduce join、map join、mapreduce优化总结、通过自定义分区类避免数据倾斜、MapReduce自定义排序
Combiner编程

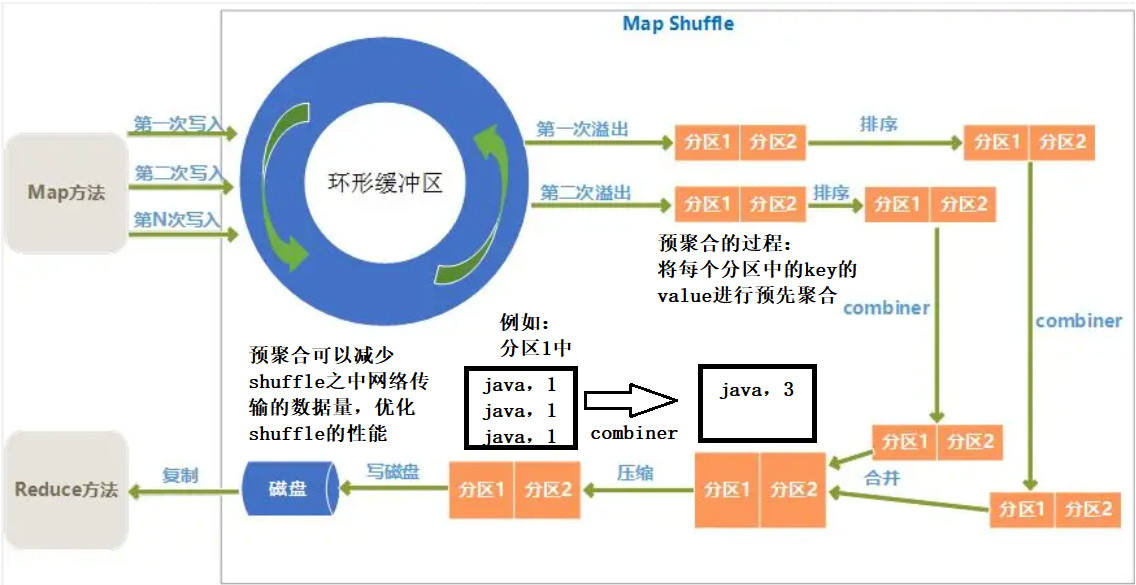
reduce join

map join

mapreduce优化总结

通过自定义分区类避免数据倾斜
#每一个reduce任务生成一个文件
package com.shujia.MapReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Demo10Partitioner {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String clazz = value.toString().split(",")[4];
context.write(new Text(clazz), value);
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
int cnt = 0;
for (Text value : values) {
context.write(key, value);
cnt += 1;
}
context.write(key, new Text(String.valueOf(cnt)));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("Demo10Partitioner");
job.setJarByClass(Demo10Partitioner.class);
// 自定义Reduce的数量
job.setNumReduceTasks(12);
// 使用自定义分区
job.setPartitionerClass(MyPartitioner.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 配置输入输出路径
FileInputFormat.addInputPath(job, new Path("/student/input"));
// 输出路径不需要提前创建,如果该目录已存在则会报错
// 通过HDFS的JavaAPI判断输出路径是否存在
Path outPath = new Path("/student/partition/output");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
// 等待job运行完成
job.waitForCompletion(true);
}
/**
* hadoop jar Hadoop-1.0.jar com.shujia.MapReduce.Demo10Partitioner
*/
}
class MyPartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int numPartitions) {
String clazz = key.toString();
int partition = 12;
switch (clazz) {
case "理科一班":
partition = 0;
break;
case "理科二班":
partition = 1;
break;
case "理科三班":
partition = 2;
break;
case "理科四班":
partition = 3;
break;
case "理科五班":
partition = 4;
break;
case "理科六班":
partition = 5;
break;
case "文科一班":
partition = 6;
break;
case "文科二班":
partition = 7;
break;
case "文科三班":
partition = 8;
break;
case "文科四班":
partition = 9;
break;
case "文科五班":
partition = 10;
break;
case "文科六班":
partition = 11;
break;
}
return partition;
}
}MapReduce自定义排序
package com.shujia.MapReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Demo11Sort {
// Map端
public static class MyMapper extends Mapper<LongWritable, Text, KeySort, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, KeySort, Text>.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
String id = split[0];
String name = split[1];
String clazz = split[2];
String score = split[3];
KeySort mapOutKey = new KeySort(clazz, Integer.valueOf(score));
context.write(mapOutKey, new Text(id + "," + name));
}
}
// Reduce端
public static class MyReducer extends Reducer<KeySort, Text, Text, Text> {
@Override
protected void reduce(KeySort key, Iterable<Text> values, Reducer<KeySort, Text, Text, Text>.Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(new Text(key.clazz + "," + key.score), value);
}
}
}
// Driver端
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("Demo11Sort");
job.setJarByClass(Demo11Sort.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(KeySort.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 配置输入输出路径
/**
* hdfs dfs -mkdir -p /student/sort/input
* hdfs dfs -put stuSumScore.txt.txt /student/sort/input
*/
FileInputFormat.addInputPath(job, new Path("/student/sort/input"));
// 输出路径不需要提前创建,如果该目录已存在则会报错
// 通过HDFS的JavaAPI判断输出路径是否存在
Path outPath = new Path("/student/sort/output");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
// 等待job运行完成
job.waitForCompletion(true);
}
/**
* hadoop jar Hadoop-1.0.jar com.shujia.MapReduce.Demo11Sort
*/
}
/**
* 自定义排序:实现WritableComparable接口
*/
class KeySort implements WritableComparable<KeySort> {
String clazz;
Integer score;
public KeySort() {
}
public KeySort(String clazz, Integer score) {
this.clazz = clazz;
this.score = score;
}
@Override
// 自定义排序规则
public int compareTo(KeySort o) {
// 首先按班级排序,然后在班级中按value排序
int clazzCompare = this.clazz.compareTo(o.clazz);
if (clazzCompare < 0) {
return -1;
} else if (clazzCompare > 0) {
return 1;
} else {
int scoreCompare = this.score - o.score;
if (scoreCompare < 0) {
return 1;
} else if (scoreCompare > 0) {
return -1;
} else {
return 0;
}
}
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(clazz);
out.writeInt(score);
}
@Override
public void readFields(DataInput in) throws IOException {
clazz = in.readUTF();
score = in.readInt();
}
}
