


MapReduce在Yarn上执行流程、Yarn核心组件功能、模拟ApplicationMaster发送Task、Map端的join
MapReduce在Yarn上执行流程
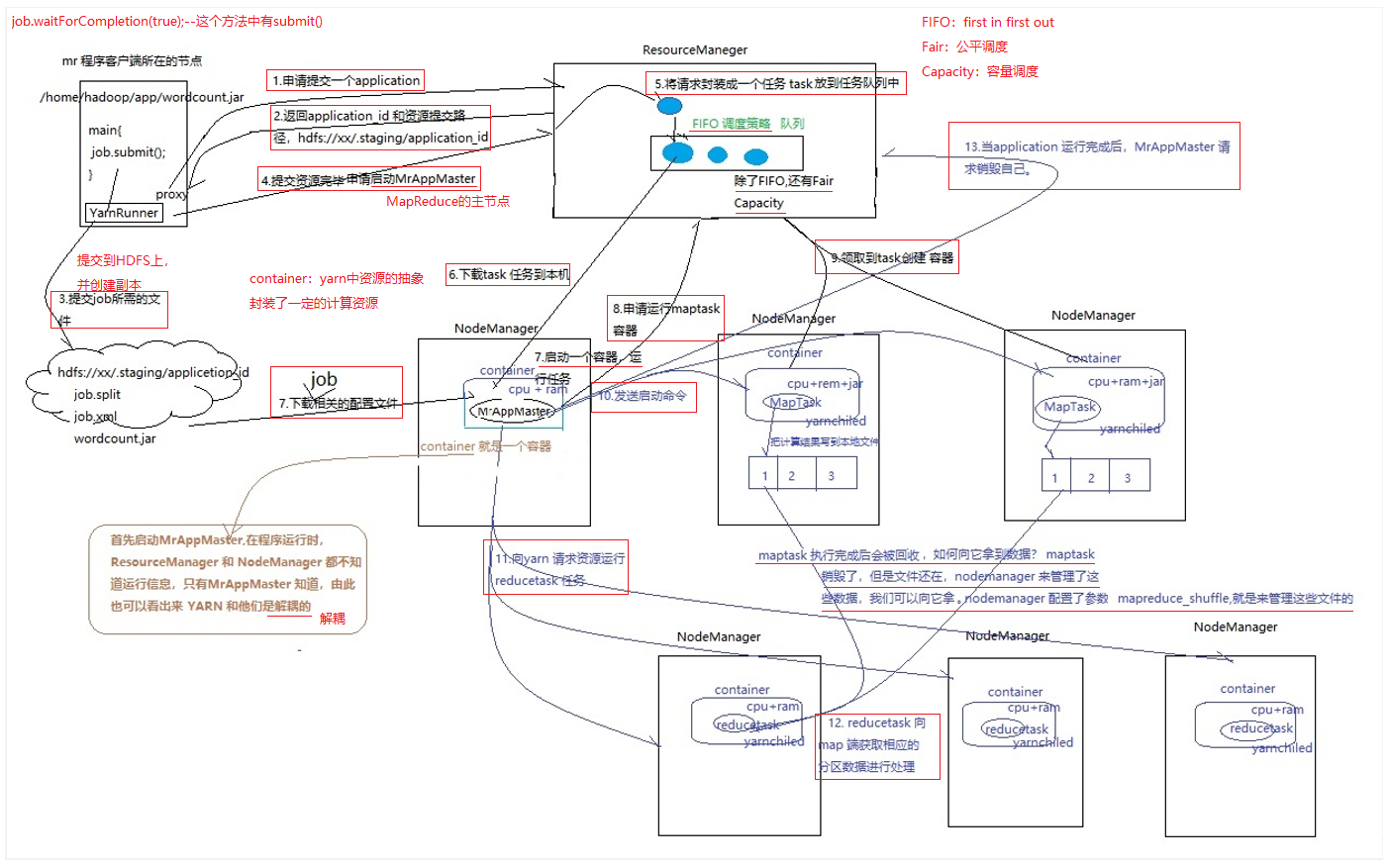
Yarn核心组件功能

模拟ApplicationMaster发送Task
在MR中,MapTask、ReduceTask
都是线程对象,因为需要在网络中传输,所以都实现了序列化接口
package com.shujia.MapReduce;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.io.Serializable;
import java.net.Socket;
public class Demo7MRAppMaster {
// 作为MR任务运行的AM,负责任务Task的分配与调度
public static void main(String[] args) throws IOException {
// 创建Socket客户端
Socket sk = new Socket("localhost", 8888);
// 创建Task任务,即将通过Socket发送给NM
Task task = new Task();
System.out.println("Task已构建,准备发送");
// 建立输出流
OutputStream outputStream = sk.getOutputStream();
// 将输出流转换为Object的输出流
ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);
// 直接将任务以Object的形式发送出去
objectOutputStream.writeObject(task);
objectOutputStream.flush();
System.out.println("Task已发送成功");
//关闭连接
objectOutputStream.close();
outputStream.close();
sk.close();
}
}
/**
* 在MR中,MapTask、ReduceTask
* 都是线程对象,因为需要在网络中传输,所以都实现了序列化接口
* 分区、分组、排序等其他功能由MR框架提供
*/
class Task extends Thread implements Serializable {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
System.out.println(i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("Task执行完毕");
}
}package com.shujia.MapReduce;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class Demo8NodeManager {
// 接收AM发送过来的Task并执行
public static void main(String[] args) throws IOException, ClassNotFoundException {
// 创建Socket服务端
ServerSocket serverSocket = new ServerSocket(8888);
System.out.println("NodeManager已经启动,等待接收任务");
// 建立Socket连接
Socket socket = serverSocket.accept();
// 创建输入流
InputStream inputStream = socket.getInputStream();
// 将输入流转换为Object输入流
ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);
// 直接从Object输入流获取Object对象
Object taskObj = objectInputStream.readObject();
System.out.println("接收到了AM发送的Task");
// 将Object对象转换为Task对象
Task task = (Task) taskObj;
System.out.println("正在执行Task");
// 执行Task
task.start();
// 关闭流,断开连接
objectInputStream.close();
inputStream.close();
socket.close();
serverSocket.close();
}
}Map端的join
#适用于 大表 关联 小表
#原理:将小表广播
package com.shujia.MapReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Hashtable;
// 实现MapJoin
public class Demo9MapJoin {
// Map端
public static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Hashtable<String, String> sumScoreHTable = new Hashtable<>();
// 每个Map任务会执行一次
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException {
// 获取”小表“的数据,构建Hashtable
URI[] cacheFiles = context.getCacheFiles();
// 获取”小表“的路径
URI uri = cacheFiles[0];
// 根据uri读取小表的数据
FileSystem fs = FileSystem.get(context.getConfiguration());
FSDataInputStream open = fs.open(new Path(uri.toString()));
BufferedReader br = new BufferedReader(new InputStreamReader(open));
String line;
while ((line = br.readLine()) != null) {
if (line.contains("\t")) {
String[] sumScoreSplit = line.split("\t");
String id = sumScoreSplit[0];
String sumScore = sumScoreSplit[1];
// 以id作为key,总分sumScore作为value 构建HashTable
sumScoreHTable.put(id, sumScore);
}
}
}
@Override
// 处理”大表“的数据
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String[] stuSplits = value.toString().split(",");
String id = stuSplits[0];
String name = stuSplits[1];
String clazz = stuSplits[4];
// 根据学生id从HashTable中获取学生总分
String sumScore = sumScoreHTable.getOrDefault(id, "0");
// 将id、name、clazz、sumScore拼接并直接由Map端输出到HDFS
String outKey = id + "," + name + "," + clazz + "," + sumScore;
context.write(new Text(outKey), NullWritable.get());
}
}
// Driver端
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("Demo9MapJoin");
job.setJarByClass(Demo9MapJoin.class);
// 配置Map端
job.setMapperClass(MyMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 配置输入输出路径
// 将 ”大表“的数据作为输入路径,小表不需要作为输入路径,待会可以广播
FileInputFormat.addInputPath(job, new Path("/student/input"));
// 输出路径不需要提前创建,如果该目录已存在则会报错
// 通过HDFS的JavaAPI判断输出路径是否存在
Path outPath = new Path("/student/mapjoin/output");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
// 将”小表“的数据 添加到MR的CacheFile中
job.addCacheFile(new URI("hdfs://cluster/student/score/output/part-r-00000"));
// 将任务提交并等待完成
job.waitForCompletion(true);
/**
* hadoop jar Hadoop-1.0.jar com.shujia.MapReduce.Demo9MapJoin
*/
}
}查看MapReduce任务输出日志


