
HDFS高可用的搭建、通过IDEA中的Zookeeper插件查看Zookeeper的数据、使用高可用时HDFS的shell命令中涉及到hdfs的路径要写全
HDFS高可用的搭建(HA比较吃资源、一般不用)
##搭建规划

ZK--Zookeeper
NN--NameNode
DN--DataNode
RM--ResourceManager
NM--NodeManager
JN--JournalNode
ZKFC--ZookeeperFailoverController1、关闭防火墙
关闭防火墙:systemctl stop firewalld
查看防火墙状态:systemctl status firewalld
取消防火墙自启:systemctl disable firewalld2、时间同步
ntpdate ntp.aliyun.com
#如果虚拟机中没有ntp
yum install ntp3、免密登录
#因为做高可用要用两台主节点,一台激活状态、一台备用状态
#所以两台主节点都需要配置免密登录
#master-->master,node1,node2
#node1-->master,node1,node2
# 1、生成密钥
ssh-keygen -t rsa
# 2、配置免密登录(需要配置两台)
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
# 3、测试免密登录
ssh node14、修改hadoop配置文件
#停止HDFS集群
stop-dfs.sh
#切换目录
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
#替换 core-site.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,node1:2181,node2:2181</value>
</property>
</configuration>
#替换 hdfs-site.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/namenode</value>
</property>
<!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/datanode</value>
</property>
<!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //////////////以下为HDFS HA的配置////////////// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- 指定cluster的两个namenode的名称分别为nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置nn1,nn2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>node1:8020</value>
</property>
<!-- 配置nn1,nn2的http通信端口 -->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>node1:50070</value>
</property>
<!-- 指定namenode元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;node1:8485;node2:8485/cluster</value>
</property>
<!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/journal</value>
</property>
<!-- 指定HDFS客户端连接active namenode的java类 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
#将配置文件同步到其它节点(没必要同步整个Hadoop)
scp ./* node1:`pwd`
scp ./* node2:`pwd`5、删除hadoop数据存储目录下的文件 每个节点都需要删除(可选操作)
rm -rf /usr/local/soft/hadoop-2.7.6/tmp6、启动zookeeper 三台都需要启动
#启动
zkServer.sh start
#查看状态
zkServer.sh status
#关闭
zkServer.sh stop7、启动JN 存储hdfs元数据
#三台都需要执行 启动命令:
/usr/local/soft/hadoop-2.7.6/sbin/hadoop-daemon.sh start journalnode8、格式化
#在一台NN上执行,这里选择master
hdfs namenode -format
#在当前节点启动NN(激活状态)
hadoop-daemon.sh start namenode9、执行同步
#没有格式化的 NN 上执行 在另外一个备用的 namenode 上面执行 这里选择 node1(备用状态)
/usr/local/soft/hadoop-2.7.6/bin/hdfs namenode -bootstrapStandby10、格式化ZK
#在master上面执行 因为zk是去中心化架构
#!!一定要先把zk集群正常启动起来
/usr/local/soft/hadoop-2.7.6/bin/hdfs zkfc -formatZK11、启动hdfs集群,在master上执行
start-dfs.sh为了方便我们查看ZK的数据
我们可以在IDEA上下载一个Zookeeper插件
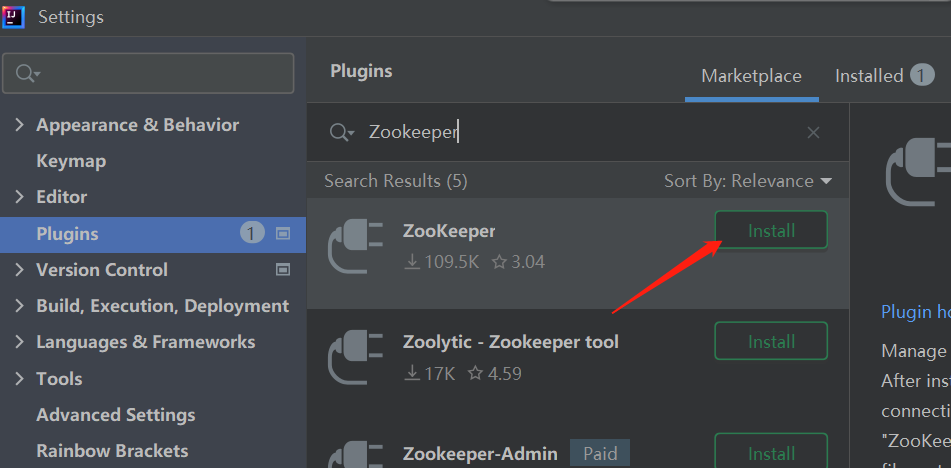
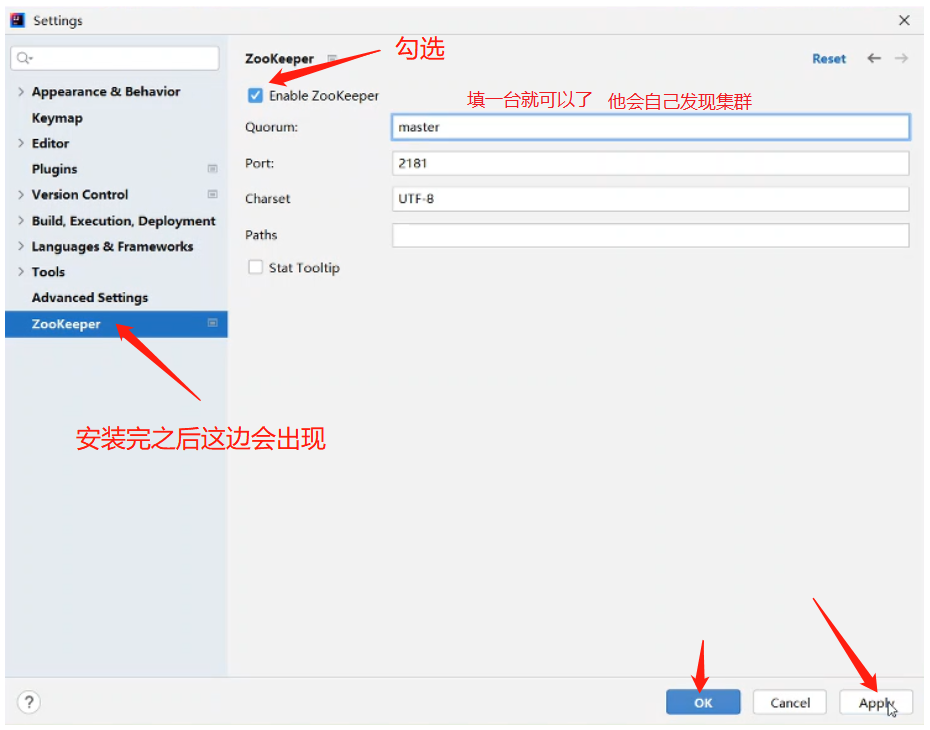
之后在最左侧的侧边栏上会多出一个Zookeeper的按钮,通过这个可以查看ZK的数据
#注意
#在使用高可用时,HDFS的shell命令中涉及到hdfs的路径要写全
#例如
hdfs dfs -put text hdfs://master:8020/