HDFS的shell命令
大数据中入门程序--wordcount
在我们学一个编程语言的时候,我们首先会去写他的入门程序--HelloWorld
而在我们大数据中入门程序叫做 wordcount(用于统计单词出现的次数)
在Hadoop中自带了一些示例程序
例如:hadoop-mapreduce-examples-2.7.6.jar
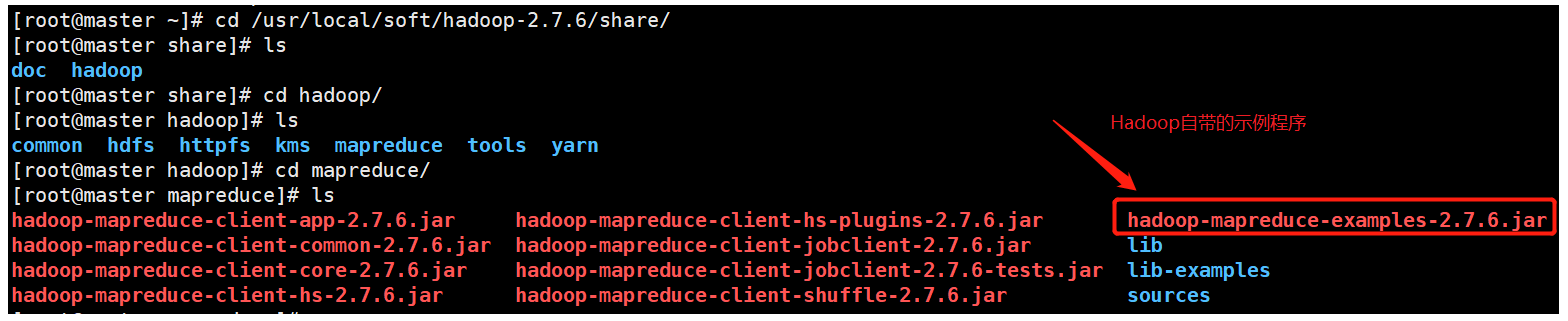
然后我们创建一个文件向里面添加一些数据并上传至Hadoop平台

通过命令运行wordcount程序
hadoop jar hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount inputpath outpath
inputpath : 是指hdfs上输入文件路径
outpath : 是指hdfs上程序运行输出结果所在路径
#注意
inputpath 指定到目录
outpath 不需要提前创建,若输出路径存在则会报错
这个时候我们发现
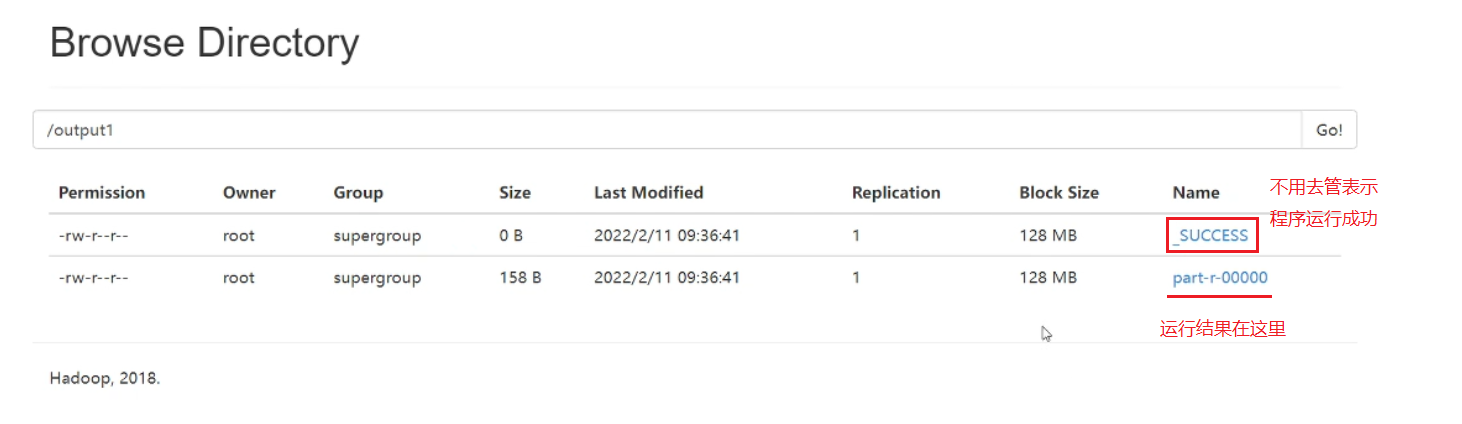
运行完毕之后查看程序运行结果有两种方式
--通过HDFS的web界面查看
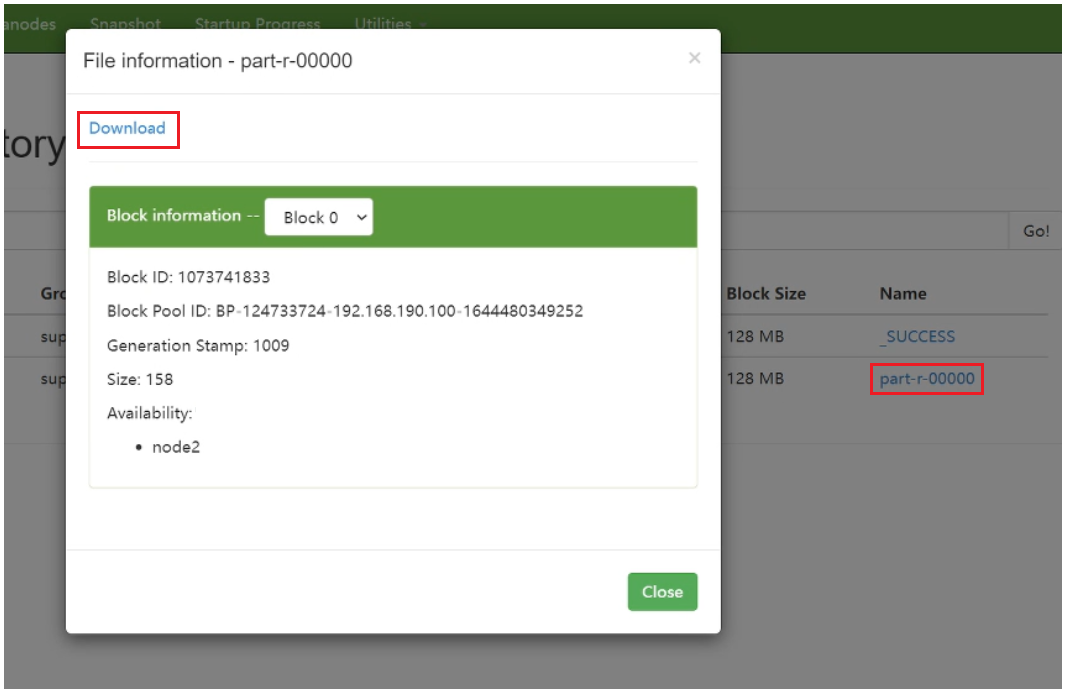
--在Linux上通过命令查看(下载get/查看cat)
HDFS的常用shell命令
大多数 HDFS 的 Shell 命令和对应的 Linux 的 Shell 命令类似。
HDFS的shell命令-格式
hdfs dfs -xxx
#或者
hadoop fs -xxx 不常用文件夹目录操作
查看目录
# 显示目录结构
hdfs dfs -ls <path>
# 以人性化的方式递归显示目录结构
hdfs dfs -ls -R -h <path>
# 显示根目录下内容
hdfs dfs -ls /
# 查看HDFS目录“/tmp/{test}/hdfs_data”的内容。
hadoop fs -ls /tmp/{test}/hdfs_data
创建目录
# 创建目录
hdfs dfs -mkdir <path>
# 递归创建目录
hdfs dfs -mkdir -p <path>
# 在HDFS上创建目录“/tmp/{test}/hdfs_data”。
hadoop fs -mkdir -p /tmp/{test}/hdfs_data
# 一般在hdfs上都有的需要处理的数据目录
hdfs dfs -mkdir /input
# 一般在hdfs上都有的处理的结果数据目录
hdfs dfs -mkdir /output
删除目录
# 删除空文件夹
hdfs dfs -rmdir <path>
# 递归删除目录和文件
hdfs dfs -rm -r <path>
文件操作
查看文件信息
# 二选一执行即可
hdfs dfs -cat <path>
#将HDFS中文件以文本形式输出(包括zip包,jar包等形式)
hdfs dfs -text <path>
hdfs dfs -tail <path>
#和Unix中tail -f命令类似,当文件内容更新时,输出将会改变,具有实时性
hdfs dfs -tail -f <path>
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -cat /wordcount/input/aaa.txt
[biubiubiu@hadoop01 ~]$ hdfs dfs -text /wordcount/input/aaa.txt
[biubiubiu@hadoop01 ~]$ hdfs dfs -tail /input/hello.txt
修改文件的权限、所有者
# 权限控制和Linux上使用方式一致
# 变更文件或目录的所属群组。 用户必须是文件的所有者或超级用户。
hdfs dfs -chgrp [-R] GROUP URI [URI ...]
# 修改文件或目录的访问权限 用户必须是文件的所有者或超级用户。
hdfs dfs-chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
# 修改文件的拥有者 用户必须是超级用户。
hdfs dfs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -chmod -R 774 /tmp
[biubiubiu@hadoop01 ~]$ hdfs dfs -chown -R biubiubiu:hadoopenv /tmp
[biubiubiu@hadoop01 ~]$ hdfs dfs -chgrp -R test /tmp
[biubiubiu@hadoop01 ~]$ hdfs dfs -chmod 777 /input/hello.txt
[biubiubiu@hadoop01 ~]$ hdfs dfs -chown 1111:1111 /input/hello.txt
统计文件信息
# 统计目录下各文件大小
hdfs dfs -du [-s] [-h] URI [URI ...]
-s : 显示所有文件大小总和
-h : 将以更友好的方式显示文件大小(例如 64.0m 而不是 67108864)
# 统计文件系统的可用空间
hdfs dfs -df -h /
-h : 将以更友好的方式显示文件大小(例如 64.0m 而不是 67108864)
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -du /wordcount
55524 /wordcount/input
0 /wordcount/biubiubiu1
37 /wordcount/biubiubiu_mv
[biubiubiu@hadoop01 ~]$ hdfs dfs -du -h /wordcount
54.2 K /wordcount/input
0 /wordcount/biubiubiu1
37 /wordcount/biubiubiu_mv
[biubiubiu@hadoop01 ~]$ hdfs dfs -du -h -s /wordcount
54.3 K /wordcount
修改文件的副本数
#更改文件的复制因子。如果 path 是目录,则更改其下所有文件的复制因子
hdfs dfs -setrep [-w] <numReplicas> <path>
-w : 标志的请求,命令等待复制完成。这有可能需要很长的时间。
[biubiubiu@hadoop01 ~]$ hdfs dfs -setrep 2 /input/hello.txt
[biubiubiu@hadoop01 ~]$ hdfs dfs -setrep -w 5 /input/bbb.txt
删除文件
# 删除文件
hdfs dfs -rm <path>
[biubiubiu@hadoop01 ~]$ hdfs dfs -rm /input/hello.txt
本地与集群的操作
将Linux本地的文件上传到集群(本地文件存在)
# 二选一执行即可
hdfs dfs -put <localsrc> <dst>
hdfs dfs -copyFromLocal <localsrc> <dst>
-f :当文件存在时,进行覆盖
-p :将权限、所属组、时间戳、ACL以及XATTR等也进行拷贝
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -put ./hello.txt /input
[biubiubiu@hadoop01 ~]$ hdfs dfs -copyFromLocal ./hi.txt /input
[biubiubiu@hadoop01 ~]$ hdfs dfs -put -f -p ~/bbb.txt /biubiubiu/bbb.txt
将Linux本地的文件剪切到集群(本地文件不存在)
hdfs dfs -moveFromLocal <localsrc> <dst>
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -moveFromLocal ./hello.txt /input
[biubiubiu@hadoop01 ~]$ hdfs dfs -moveFromLocal ~/biubiubiu.txt /input
将Linux本地的文件追加到集群文件
集群文件不能随机修改,只能追加。
注意:这是大数据,数据量很大,跟传统的文件不同,不会修改一两条什么的,品,你细品。
hdfs dfs -appendToFile <localsrc> ... <dst>
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -appendToFile ./test_1.txt /input/aaa.txt
# 多个文件用空格隔开
[biubiubiu@hadoop01 ~]$ hdfs dfs -appendToFile ./test_1.txt ./test_2.txt /input/aaa.txt
将集群文件下载到Linux本地
# 二选一执行即可
hdfs dfs -get <src> <localdst>
hdfs dfs -copyToLocal <src> <localdst>
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -get /input/hello.txt ./receive/
[biubiubiu@hadoop01 ~]$ hdfs dfs -copyToLocal /input/hi.txt ./receive/
[biubiubiu@hadoop01 ~]$ hdfs dfs -get /input/biubiubiu.txt ./
合并下载多个文件到本地Linux
hdfs dfs -getmerge [-nl] <src> <localdst>
[biubiubiu@hadoop01 ~]$ hdfs dfs -getmerge /input/* data.txt(合并再下载)
# 案例 将HDFS上的wordcount_input.txt和aaa.txt合并后下载到本地的当前用户家目录的merge.txt
[biubiubiu@hadoop01 ~]$ hdfs dfs -getmerge /input/wordcount_input.txt /wordcount/input/aaa.txt ~/merge.txt
-nl 在每个文件的末尾添加换行符(LineFeed)
-skip-empty-file 跳过空文件
集群内文件的操作
集群内文件的复制
#该命令允许多个来源,但此时目标必须是一个目录
hdfs dfs -cp [-f] [-p] <src> <dst>
-f :当文件存在时,进行覆盖
-p :将权限、所属组、时间戳、ACL以及XATTR等也进行拷贝
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -cp /input/hello.txt /input/cptest
[biubiubiu@hadoop01 ~]$ hdfs dfs -cp -f -p /biubiubiu/bbb.txt /wordcount/input/bbb.txt
集群内文件的剪切(移动操作,重命名)
#命令允许多个来源,但此时目的地需要是一个目录。跨文件系统移动文件是不允许的
hdfs dfs -mv <src> <dst>
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -mv /input/hi.txt /input/mvtest
# 剪切移动
[biubiubiu@hadoop01 ~]$ hdfs dfs -mv /biubiubiu /biubiubiu1 /wordcount
# 重名名
[biubiubiu@hadoop01 ~]$ hdfs dfs -mv /input/biubiubiu /input/biubiubiu_mv
文件检测
hdfs dfs -test -[defsz] URI
-d:如果路径是目录,返回 0
-e:如果路径存在,则返回 0
-f:如果路径是文件,则返回 0
-s:如果路径不为空,则返回 0
-r:如果路径存在且授予读权限,则返回 0
-w:如果路径存在且授予写入权限,则返回 0
-z:如果文件长度为零,则返回 0
#案例
[biubiubiu@hadoop01 ~]$ hdfs dfs -test -d /input/biubiubiu && echo "true"
查看DataNode存储的数据块信息位置
/opt/model/hadoop-2.7.7/dfs/datanode/current/BP-1209817470-192.168.159.151-1609489880182/current/finalized/subdir0/subdir0
如果另有需要可以去百度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号