


Redis集群的概述及其搭建
一、主从复制
1.介绍
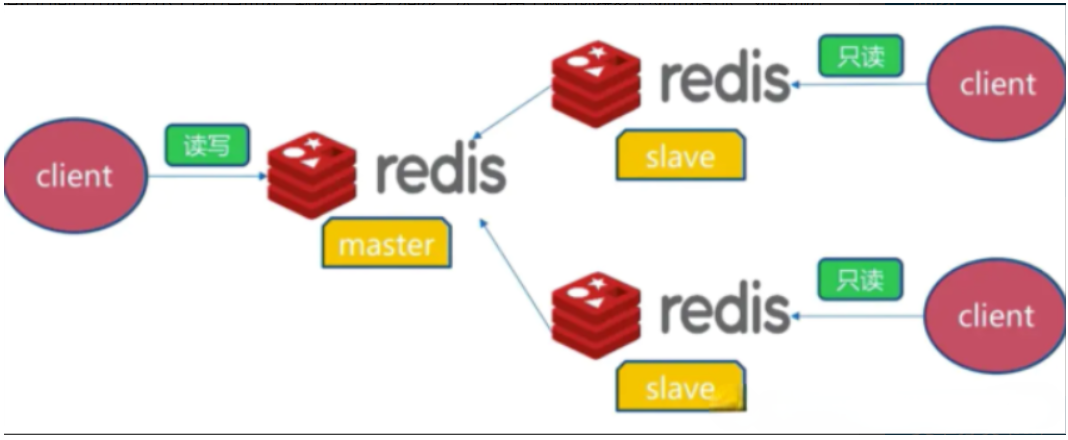
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器,主从是哨兵和集群模式能够实施的基础。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有零个或多个从节点(0+个从节点),但一个从节点只能有一个主节点。一般主节点负责接收写请求,从节点负责接收读请求,从而实现读写分离。
主从一般部署在不同机器上,复制时存在网络延时问题,使用参数repl-disable-tcp-nodelay选择是否关闭TCP_NODELAY,默认为关闭:
-
关闭:无论数据大小都会及时同步到从节点,占带宽,适用于主从网络好的场景;
-
开启:主节点每隔指定时间合并数据为TCP包节省带宽,默认为40毫秒同步一次,适用于网络环境复杂或带宽紧张,如跨机房
2.作用
-
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
-
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
-
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务,分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
-
读写分离:主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量;
-
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础。
-
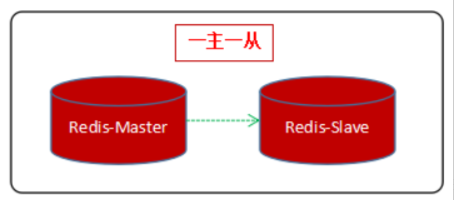
一主一从
最基础的主从复制模型,主节点负责处理写请求,从节点负责处理读请求,主节点使用RDB持久化模式,从节点使用AOF持久化模式
-
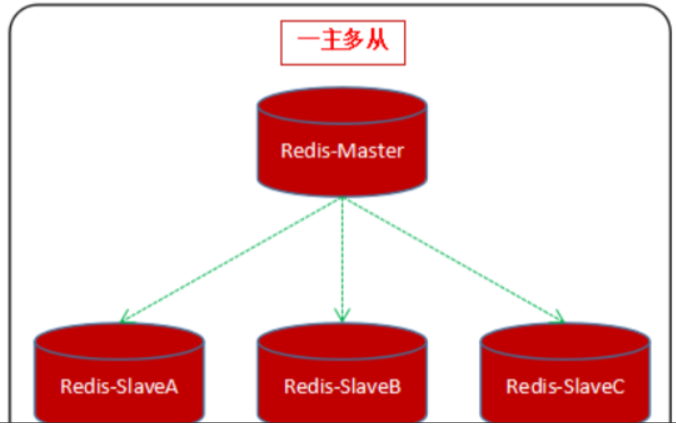
一主多从
一个主节点可以有多个从节点,但每个从节点只能有一个主节点。一主多从适用于写少读多的场景,多个从节点可以分担读请求负载,提升并发
-
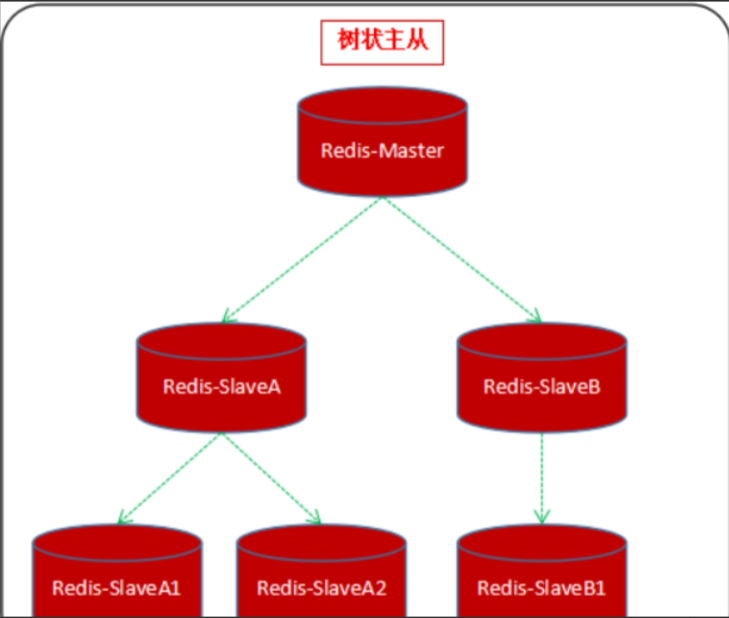
树状主从
上面的一主多从可以实现读请求的负载均衡,但当从节点数量多的时候,主节点的同步压力也是线性提升的,因此可以使用树状主从来分担主节点的同步压力
4.复制原理
主从复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段。
在从节点执行 slaveof 命令后,复制过程便开始按下面的流程运作:
-
1.保存主节点信息:配置slaveof之后会在从节点保存主节点的信息。
-
2.主从建立socket连接:定时发现主节点以及尝试建立连接。
-
3.发送ping命令:从节点定时发送ping给主节点,主节点返回PONG。若主节点没有返回PONG或因阻塞无法响应导致超时,则主从断开,在下次定时任务时会从新ping主节点。
-
4.权限验证:若主节点开启了ACL或配置了requirepass参数,则从节点需要配置masteruser和masterauth才能保证主从正常连接。
-
5.同步数据集:首次连接,全量同步。
-
6.命令持续复制:全量同步完成后,保持增量同步。
二、哨兵
1.介绍
哨兵(sentinel),用于对主从结构中的每一台服务器进行监控,当主节点出现故障后通过投票机制来挑选新的主节点,并且将所有的从节点连接到新的主节点上。前面的主从是最基础的提升Redis服务器稳定性的一种实现方式,但我们可以看到master节点仍然是一台,若主节点宕机,所有从服务器都不会有新的数据进来,如何让主节点也实现高可用,当主节点宕机的时候自动从从节点中选举一台节点提升为主节点就是哨兵实现的功能。
2.作用
-
监控:监控主从节点运行情况。
-
通知:当监控节点出现故障,哨兵之间进行通讯。
-
自动故障转移:当监控到主节点宕机后,断开与宕机主节点连接的所有从节点,然后在从节点中选取一个作为主节点,将其他的从节点连接到这个最新的主节点。最后通知客户端最新的服务器地址。
哨兵也是一台redis服务器,只是不对外提供任何服务,redis的bin目录下的redis-sentinel其实就是redis-server的软连接。
哨兵节点最少三台且必须为单数。这个与其他分布式框架如zookeeper类似,如果是双数,在选举的时候就会出现平票的情况,所以必须是三台及以上的单数。
3.原理
哨兵之间会有通讯,哨兵和主从节点之间也有监控,基于这些信息同步和状态监控实现Redis的故障转移:
-
哨兵和哨兵之间以及哨兵和Redis主从节点之间每隔一秒发送ping监控它们的健康状态;
-
哨兵向Redis主从节点每隔10秒发送一次info保存节点信息;
-
哨兵向Redis主节点每隔2秒发送一次hello,直到哨兵报出sdown,代表主节点失联,然后通知其余哨兵尝试连接该主节点;
Redis主节点下线的情况分为主观下线和客观下线:
主观下线(sdown):单独一个哨兵发现master故障了。 客观下线(odown):半数哨兵都认为master节点故障就会触发故障转移。
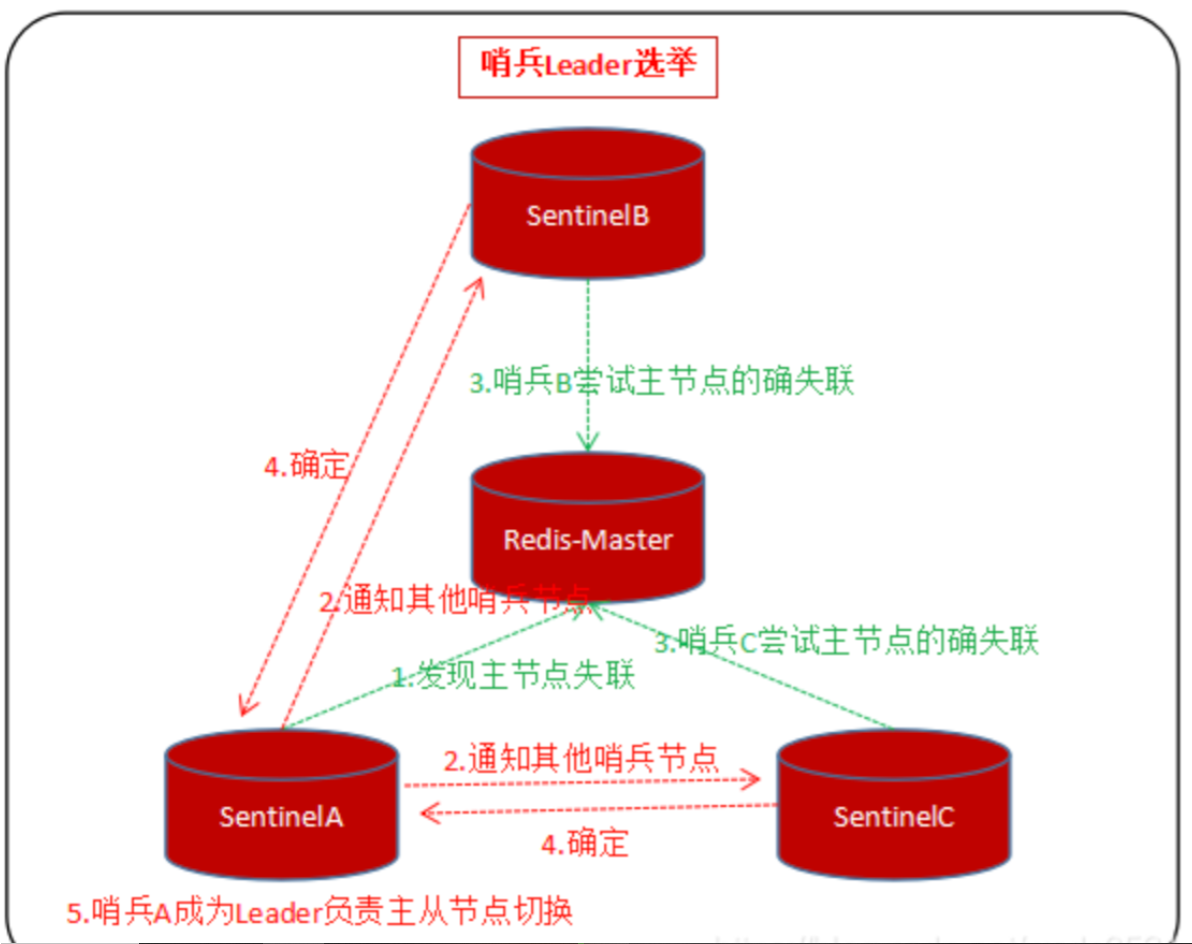
4.哨兵Leader选举:
一般情况下当哨兵发现主节点sdown之后 该哨兵节点会成为领导者负责处理主从节点的切换工作:
-
哨兵A发现Redis主节点失联;
-
哨兵A报出sdown,并通知其他哨兵,发送指令sentinel is-master-down-by-address-port给其余哨兵节点;
-
其余哨兵接收到哨兵A的指令后尝试连接Redis主节点,发现主节点确实失联;
-
哨兵返回信息给哨兵A,当超过半数的哨兵认为主节点下线后,状态会变成odown;
-
最先发现主节点下线的哨兵A会成为哨兵领导者负责这次的主从节点的切换工作;
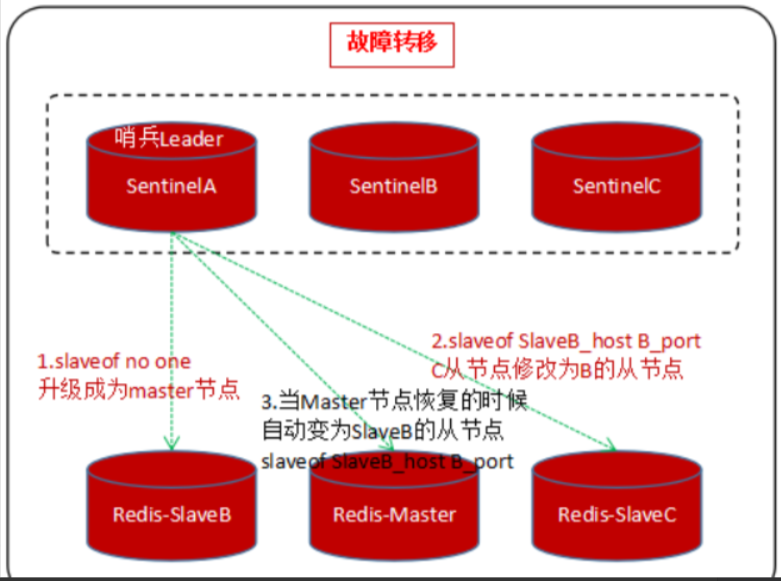
5.故障转移:
当哨兵发现主节点下线之后经过上面的哨兵选举机制,选举出本次故障转移工作的哨兵节点完成本次主从节点切换的工作:
-
哨兵Leader 根据一定规则从各个从节点中选择出一个节点升级为主节点;
-
其余从节点修改对应的主节点为新的主节点;
-
当原主节点恢复启动的时候,变为新的主节点的从节点
哨兵Leader选择新的主节点遵循下面几个规则:
健康度:从节点响应时间快;
完整性:从节点消费主节点的offset偏移量尽可能的高;
稳定性:若仍有多个从节点,则根据从节点的创建时间选择最有资历的节点升级为主节点;
三、集群
1.介绍
Redis集群(Redis Cluster)是从 Redis 3.0 开始引入的分布式存储方案。集群由多个节点(Node)组成,Redis 的数据分布在这些节点中。集群中的节点分为主节点和从节点,只有主节点负责读写请求和集群信息的维护,从节点只进行主节点数据和状态信息的复制。
2.作用
Redis集群的作用有下面几点:
-
数据分区:突破单机的存储限制,将数据分散到多个不同的节点存储;
-
负载均衡:每个主节点都可以处理读写请求,提高了并发能力;
-
高可用:集群有着和哨兵模式类似的故障转移能力,提升集群的稳定性;
3.原理
3.1 数据分区
衡量数据分区方法的标准有两个重要因素:
1) 是否均匀分区; 2) 增减节点对数据分布的影响;
由于哈希算法具有随机性,可以保证数据均匀分布,因此Redis集群采用哈希分区的方式对数据进行分区,哈希分区就是对数据的特征值进行哈希,然后根据哈希值决定数据放在哪里。
3.2 常见的哈希分区有:
-
哈希取余:
计算key的hash值,对节点数量做取余计算,根据结果将数据映射到对应节点;但当节点增减时,系统中所有数据都需要重新计算映射关系,引发大量数据迁移;
-
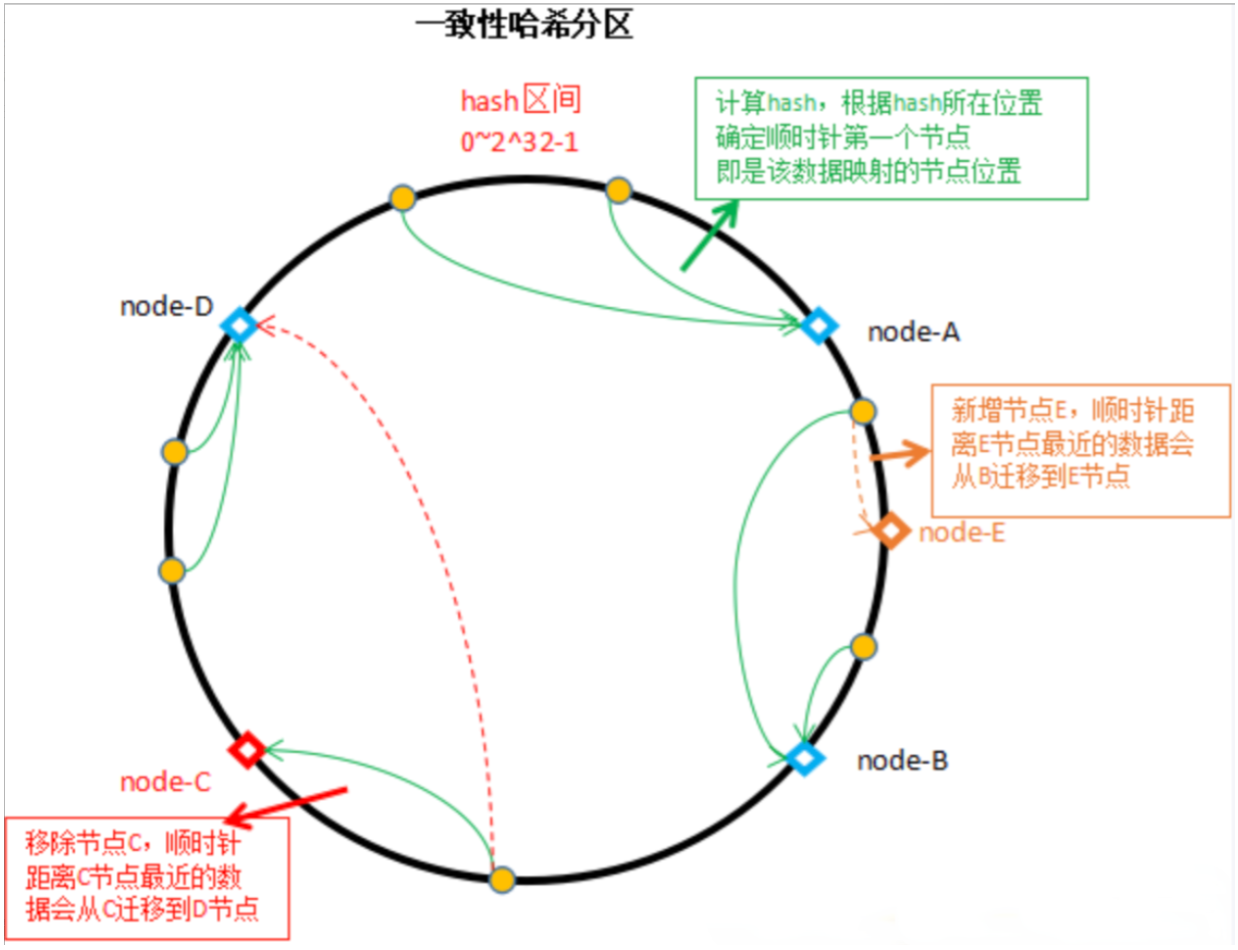
一致性哈希:
将hash值区间抽象为一个环形,节点均匀分布在该环形之上,然后根据数据的key计算hash值,在该hash值所在的圆环上的位置延顺时针行走找到的第一个节点的位置,该数据就放在该节点之上。相比哈希取余,一致性哈希分区将增减节点的影响限制为相邻节点。
例:在AB节点中新增一个节点E时,因为B上的数据的key的hash值在A和B所在的hash区间之内,因此只有B上的一部分数据会迁移到E节点之上;同理如果从BCD中移除C节点,由于C上的数据的key的hash值在B和C所在的hash区间之内,因此C上的数据顺时针找到的第一个节点就是D节点,因此C的数据会全部迁移到D节点之上。 但当节点数量较少的时候,增删节点对单个节点的影响较大,会造成数据分布不均,如移除C节点时,C的数据会全部迁移到D节点上,此时D节点拥有的数据由原来的1/4变成现在的1/2,相比于节点A和B来说负载更高。
-
带虚拟节点的一致性哈希 (Redis集群):
Redis采用的方案
在一致性哈希基础之上,引入虚拟节点的概念,虚拟节点被称为槽(slot)。Redis集群中,槽的数量为16384。槽介于数据和节点之间,将节点划分为一定数量的槽,每个槽包含哈希值一定范围内的数据。由原来的hash-->node 变为 hash-->slot-->node。当增删节点时,该节点所有拥有的槽会被重新分配给其他节点,可以避免在一致性哈希分区中由于某个节点的增删造成数据的严重分布不均。
4. 通信机制
在上面的哨兵方案中,节点被分为数据节点和哨兵节点,哨兵节点也是redis服务,但只作为选举监控使用,只有数据节点会存储数据。而在Redis集群中,所有节点都是数据节点,也都参与集群的状态维护。
在Redis集群中,数据节点提供两个TCP端口,在配置防火墙时需要同时开启下面两类端口:
-
普通端口:即客户端访问端口,如默认的6379;
-
集群端口:普通端口号加10000,如6379的集群端口为16379,用于集群节点之间的通讯;
集群的节点之间通讯采用Gossip协议,节点根据固定频率(每秒10次)定时任务进行判断,当集群状态发生变化,如增删节点、槽状态变更时,会通过节点间通讯同步集群状态,使集群收敛。
集群间发送的Gossip消息有下面五种消息类型:
-
MEET:在节点握手阶段,对新加入的节点发送meet消息,请求新节点加入当前集群,新节点收到消息会回复PONG消息
-
PING:节点互相发送ping消息,收到消息的会回复pong消息。ping消息内容包含本节点和其他节点的状态信息,以此达到状态同步
-
PONG:pong消息包含自身的状态数据,在接收到ping或meet消息时会回复pong消息,也会主动向集群广播pong消息
-
FAIL:当一个主节点判断另一个主节点进入fail状态时,会向集群广播这个消息,接收到的节点会保存消息并对该fail节点做状态判断
-
PUBLISH:当节点收到publish命令时,会先执行命令,然后向集群广播publish消息,接收到消息的节点也会执行publish命令;
四、搭建集群
从Redis5之后可以直接使用redis-cli --cluster命令自动部署Redis集群
这里以一台机器上使用三主三从的方式部署Redis集群
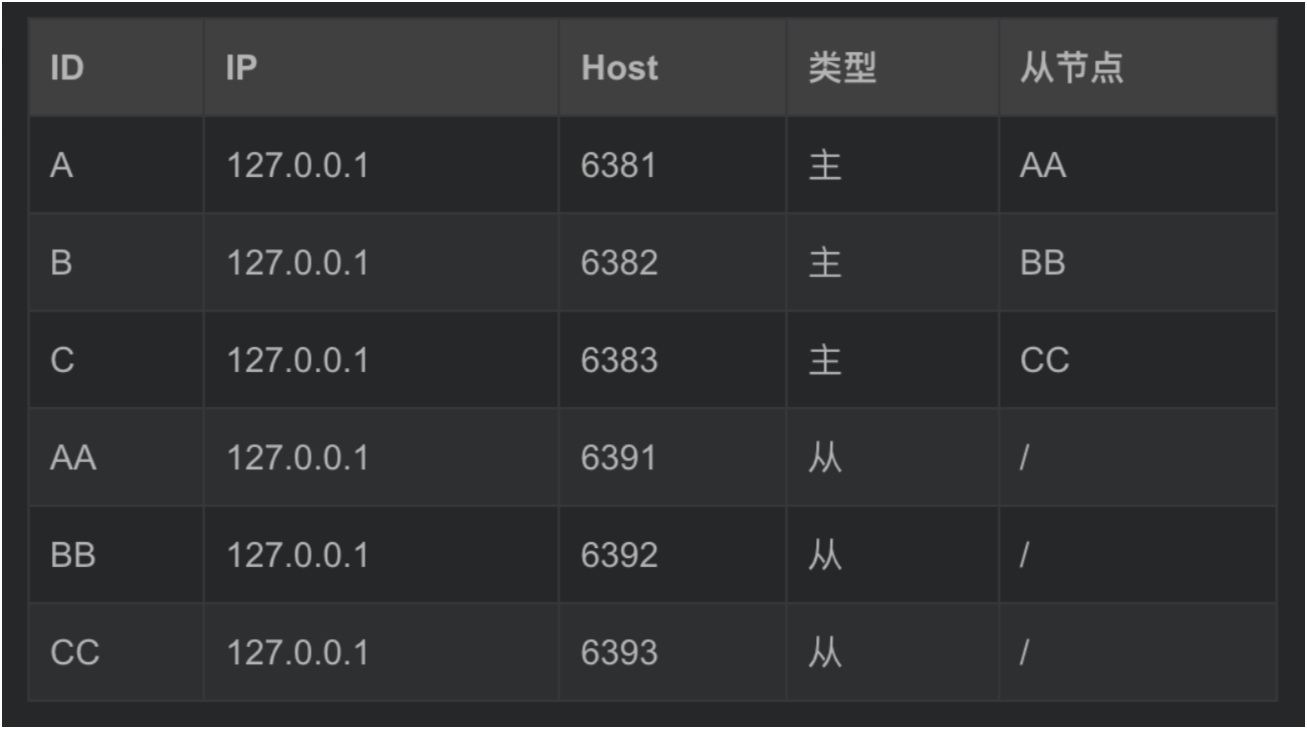
-
将redis目录复制出六个
cp -r /usr/local/soft/redis /usr/local/soft/redisA cp -r /usr/local/soft/redis /usr/local/soft/redisB cp -r /usr/local/soft/redis /usr/local/soft/redisC cp -r /usr/local/soft/redis /usr/local/soft/redisAA cp -r /usr/local/soft/redis /usr/local/soft/redisBB cp -r /usr/local/soft/redis /usr/local/soft/redisCC -
分别修改六个目录中的redis.conf文件,主要开启集群以及修改端口和文件路径
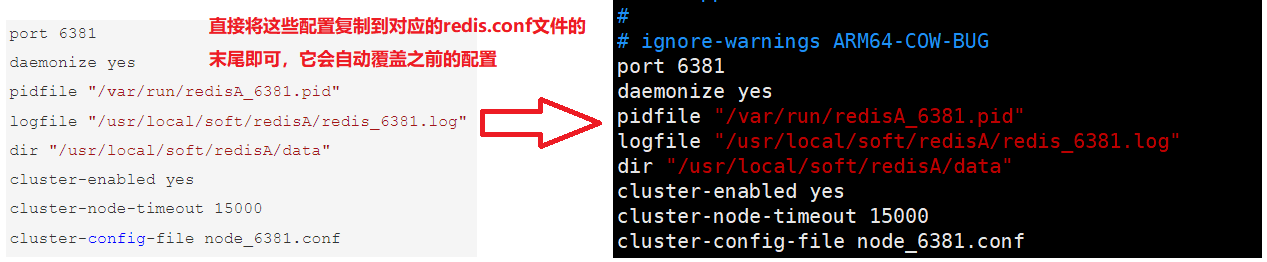
vim /usr/local/soft/redisA/redis.conf -------------------------------------------- port 6381 daemonize yes pidfile "/var/run/redisA_6381.pid" logfile "/usr/local/soft/redisA/redis_6381.log" dir "/usr/local/soft/redisA/data" cluster-enabled yes cluster-node-timeout 15000 cluster-config-file node_6381.conf vim /usr/local/soft/redisB/redis.conf -------------------------------------------- port 6382 daemonize yes pidfile "/var/run/redisB_6382.pid" logfile "/usr/local/soft/redisB/redis_6382.log" dir "/usr/local/soft/redisB/data" cluster-enabled yes cluster-node-timeout 15000 cluster-config-file node_6382.conf vim /usr/local/soft/redisC/redis.conf -------------------------------------------- port 6383 daemonize yes pidfile "/var/run/redisC_6383.pid" logfile "/usr/local/soft/redisC/redis_6383.log" dir "/usr/local/soft/redisC/data" cluster-enabled yes cluster-node-timeout 15000 cluster-config-file node_6383.conf vim /usr/local/soft/redisAA/redis.conf -------------------------------------------- port 6391 daemonize yes pidfile "/var/run/redisAA_6391.pid" logfile "/usr/local/soft/redisAA/redis_6391.log" dir "/usr/local/soft/redisAA/data" cluster-enabled yes cluster-node-timeout 15000 cluster-config-file node_6391.conf vim /usr/local/soft/redisBB/redis.conf -------------------------------------------- port 6392 daemonize yes pidfile "/var/run/redisB_6392.pid" logfile "/usr/local/soft/redisBB/redis_6392.log" dir "/usr/local/soft/redisBB/data" cluster-enabled yes cluster-node-timeout 15000 cluster-config-file node_6392.conf vim /usr/local/soft/redisCC/redis.conf -------------------------------------------- port 6393 daemonize yes pidfile "/var/run/redisCC_6393.pid" logfile "/usr/local/soft/redisCC/redis_6393.log" dir "/usr/local/soft/redisCC/data" cluster-enabled yes cluster-node-timeout 15000 cluster-config-file node_6393.confcluster-config-file:每个节点在运行过程中,会维护一份集群配置文件。 当集群信息发生变化时(如增减节点),集群内所有节点会将最新信息更新到该配置文件。 节点重启后,会重新读取该配置文件,获取集群信息,可以方便的重新加入到集群中。 也就是说,当 Redis 节点以集群模式启动时,会首先寻找是否有集群配置文件。 如果有则使用文件中的配置启动;如果没有,则初始化配置并将配置保存到文件中。
集群配置文件由 Redis 节点维护,不需要人工修改。
-
分别在6个目录下创建log文件和data目录
# 创建log文件 touch /usr/local/soft/redisA/redis_6381.log touch /usr/local/soft/redisB/redis_6382.log touch /usr/local/soft/redisC/redis_6383.log touch /usr/local/soft/redisAA/redis_6391.log touch /usr/local/soft/redisBB/redis_6392.log touch /usr/local/soft/redisCC/redis_6393.log # 创建data目录 mkdir /usr/local/soft/redisA/data mkdir /usr/local/soft/redisB/data mkdir /usr/local/soft/redisC/data mkdir /usr/local/soft/redisAA/data mkdir /usr/local/soft/redisBB/data mkdir /usr/local/soft/redisCC/data -
启动所有节点
redis-server /usr/local/soft/redisA/redis.conf redis-server /usr/local/soft/redisB/redis.conf redis-server /usr/local/soft/redisC/redis.conf redis-server /usr/local/soft/redisAA/redis.conf redis-server /usr/local/soft/redisBB/redis.conf redis-server /usr/local/soft/redisCC/redis.conf -
创建集群
部署集群需要先启动各个节点的服务,此时这些节点都没加到集群中,使用redis-cli --cluster create xxx命令创建集群
集群只需要被创建一次
# 这里的--cluster-replicas表示每个主节点有几个副本节点 # 192.168.190.100为master的IP 需根据自己实际情况指定 # 否则无法通过JedisCluster代码访问Redis集群 redis-cli --cluster create 192.168.190.100:6381 192.168.190.100:6382 192.168.190.100:6383 192.168.190.100:6391 192.168.190.100:6392 192.168.190.100:6393 --cluster-replicas 1redis-cli --cluster代替了之前的redis-trib.rb,我们无需安装ruby环境即可直接使用它附带的所有功能:创建集群、增删节点、槽迁移、完整性检查、数据重平衡等等。
-
停止集群
直接停止6个Redis服务即可
-
重新创建集群
# 停止集群 redis-cli -p 6381 shutdown redis-cli -p 6382 shutdown redis-cli -p 6383 shutdown redis-cli -p 6391 shutdown redis-cli -p 6392 shutdown redis-cli -p 6393 shutdown # 删除文件 rm -rf /usr/local/soft/redisA/data/* rm -rf /usr/local/soft/redisB/data/* rm -rf /usr/local/soft/redisC/data/* rm -rf /usr/local/soft/redisAA/data/* rm -rf /usr/local/soft/redisBB/data/* rm -rf /usr/local/soft/redisCC/data/* # 重新启动6个Redis服务 redis-server /usr/local/soft/redisA/redis.conf redis-server /usr/local/soft/redisB/redis.conf redis-server /usr/local/soft/redisC/redis.conf redis-server /usr/local/soft/redisAA/redis.conf redis-server /usr/local/soft/redisBB/redis.conf redis-server /usr/local/soft/redisCC/redis.conf # 重新创建集群 redis-cli --cluster create 192.168.190.100:6381 192.168.190.100:6382 192.168.190.100:6383 192.168.190.100:6391 192.168.190.100:6392 192.168.190.100:6393 --cluster-replicas 1
五、集群限制
由于Redis集群中数据分布在不同的节点上,因此有些功能会受限:
-
db库:单机的Redis默认有16个db数据库,但在集群模式下只有一个db0;
-
复制结构:上面的复制结构有树状结构,但在集群模式下只允许单层复制结构;
-
事务/lua脚本:仅允许操作的key在同一个节点上才可以在集群下使用事务或lua脚本;(使用Hash Tag可以解决)
-
key的批量操作:如mget,mset操作,只有当操作的key都在同一个节点上才可以执行;(使用Hash Tag可以解决)
-
keys/flushall:只会在该节点之上进行操作,不会对集群的其他节点进行操作;
HashTag
由于key被分布在不同的节点之上,因此无法跨节点做事务或lua脚本操作,但我们可以使用hash tag方式解决。
hash tag:当key包含{}的时候,不会对整个key做hash,只会对{}包含的部分做hash然后分配槽slot;因此我们可以让不同的key在同一个槽内,这样就可以解决key的批量操作和事务及lua脚本的限制了;
但由于hash tag会将不同的key分配在相同的slot中,如果使用不当,会造成数据分布不均的情况,需要注意
六、访问集群
上面介绍了槽的概念,在每个节点存储着不同范围的槽,数据也分布在不同的节点之上,我们在访问集群的时候,如何知道数据在哪个节点或者在哪个槽之上呢? 下面介绍两种访问连接:
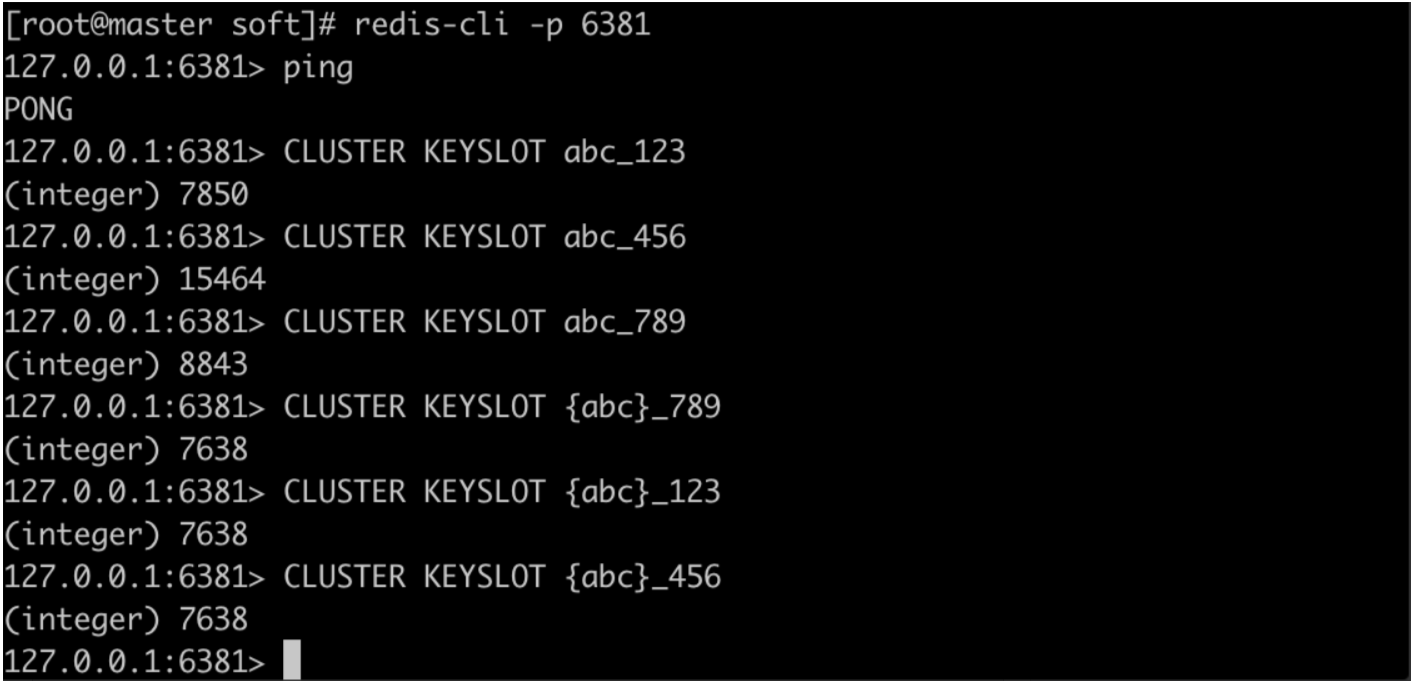
查看key在哪个slot:cluster keyslot you_key
-
Dummy客户端
使用redis-cli客户端连接集群被称为dummy客户端,只会在执行命令之后通过MOVED错误重定向找到对应的节点,如图,可以使用redis-cli -c命令进入集群命令行,当查看或设置key的时候会根据上面提到的CRC16算法计算key的hash值找到对应的槽slot,然后重定向到对应的节点之后才能操作,也可以使用cluster keyslot命令查看key所在的槽solt:
#使用-c进入集群命令行模式 redis-cli -c -p 6381 #使用命令查看key所在的槽 cluster keyslot key1 -
Smart客户端
相比于dummy客户端,smart客户端在初始化连接集群时就缓存了槽slot和节点node的对应关系,也就是在连接任意节点后执行cluster slots,JedisCluster就是smart客户端:
cluster slots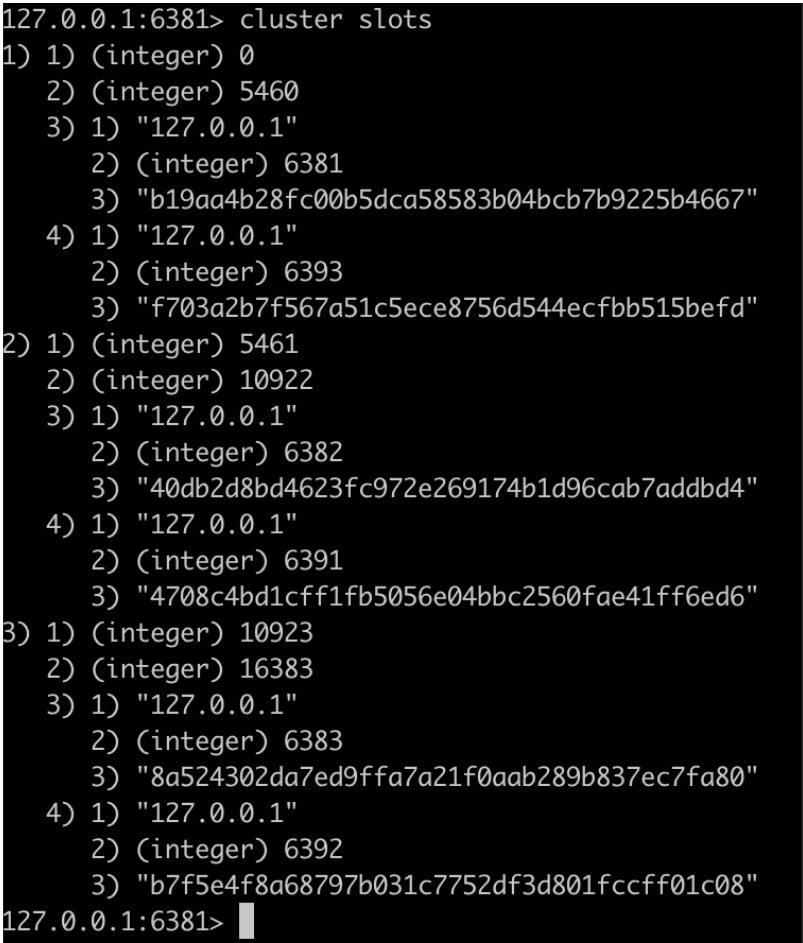
七、集群参数优化
-
cluster_node_timeout:默认值为15s。
影响ping消息接收节点的选择,值越大对延迟容忍度越高,选择的接收节点就越少,可以降低带宽,但会影响收敛速度。应该根据带宽情况和实际要求具体调整。
影响故障转移的判定,值越大越不容易误判,但完成转移所消耗的时间就越长。应根据网络情况和实际要求具体调整。
-
cluster-require-full-coverage
为了保证集群的完整性,只有当16384个槽slot全部分配完毕,集群才可以上线,但同时,若主节点发生故障且故障转移还未完成时,原主节点的槽不在任何节点中,集群会处于下线状态,影响客户端的使用。该参数可以改变此设定:
-
no: 表示当槽没有完全分配时,集群仍然可以上线;
-
yes: 默认配置,只有槽完全分配,集群才可以上线;
-

