数据结构--哈夫曼树
哈夫曼树
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
重要概念
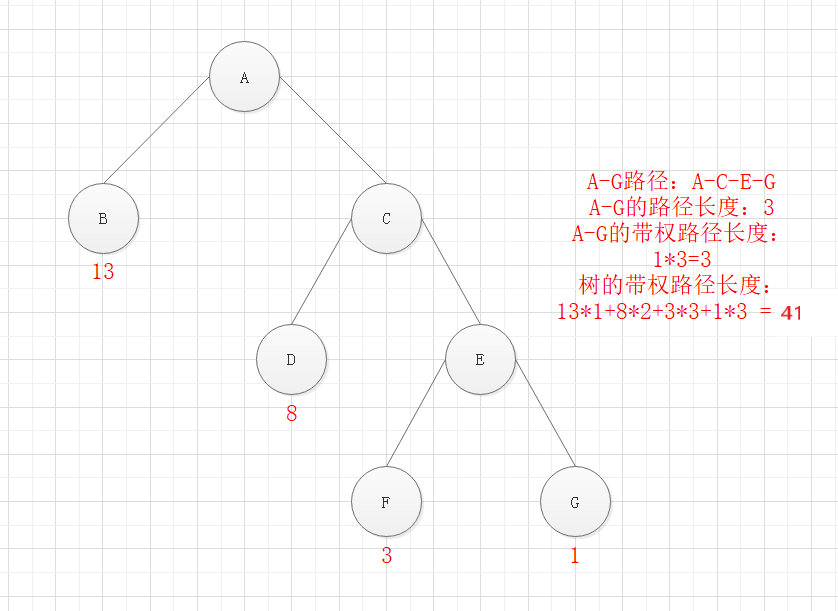
路径:从一个节点到它往下可以达到的节点所经shu过的所有节点,称为两个节点之间的路径
路径长度:即两个节点的层级差,如A节点在第一层,B节点在第四层,那它们之间的路径长度为4-1=3
权重值:为树中的每个节点设置一个有某种含义的数值,称为权重值(Weight),权重值在不同算法中可以起到不同的作用
节点的带权路径长度:从根节点到该节点的路径长度与该节点权重值的乘积
树的带权路径长度:所有叶子节点的带权路径长度之和,也简称为WPL
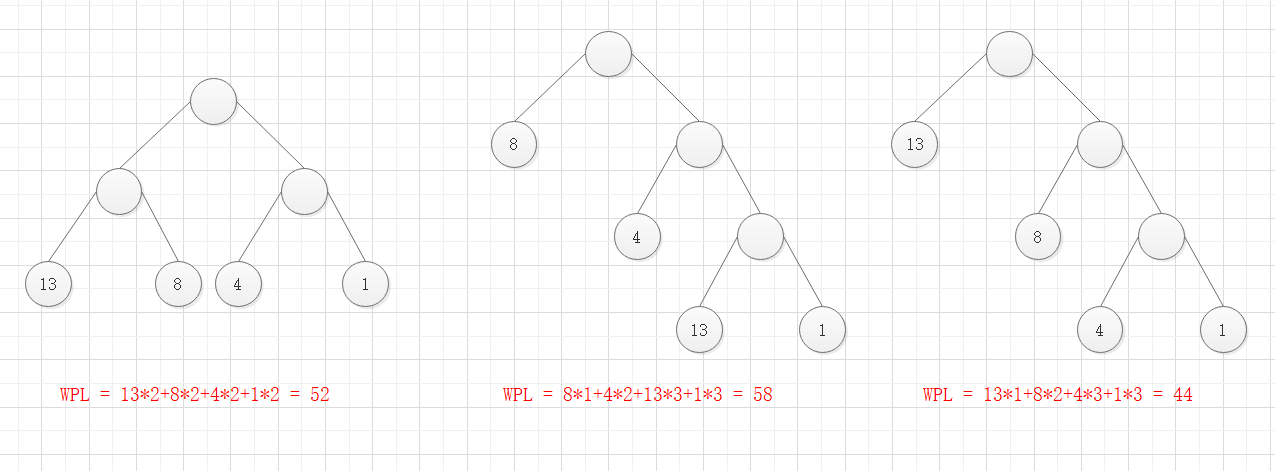
哈夫曼树判断
判断一棵树是不是哈夫曼树只要判断该树的结构是否构成最短带权路径。
在下图中3棵同样叶子节点的树中带权路径最短的是右侧的树,所以右侧的树就是哈夫曼树。
代码实现
案例:将数组{13,7,8,3,29,6,1}转换成一棵哈夫曼树
思路分析:从哈夫曼树的概念中可以看出,要组成哈夫曼树,权值越大的节点必须越靠近根节点,所以在组成哈夫曼树时,应该由最小权值的节点开始。
步骤:
(1) 将数组转换成节点,并将这些节点由小到大进行排序存放在集合中
(2) 从节点集合中取出权值最小的两个节点,以这两个节点为子节点创建一棵二叉树,它们的父节点权值就是它们的权值之和
(3) 从节点集合中删除取出的两个节点,并将它们组成的父节点添加进节点集合中,跳到步骤(2)直到节点集合中只剩一个节点
public class HuffmanTreeDemo {
public static void main(String[] args) {
int array[] = {13,7,8,3,29,6,1};
HuffmanTree huffmanTree = new HuffmanTree();
Node root = huffmanTree.create(array);
huffmanTree.preOrder(root);
}
}
//哈夫曼树
class HuffmanTree{
public void preOrder(Node root){
if (root == null){
System.out.println("哈夫曼树为空,无法遍历");
return;
}
root.preOrder();
}
/**
* 创建哈夫曼树
* @param array 各节点的权值大小
* @return
*/
public Node create(int array[]){
//先将传入的各权值转成节点并添加到集合中
List<Node> nodes = new ArrayList<>();
for (int value : array){
nodes.add(new Node(value));
}
/*
当集合中的数组只有一个节点时,即集合内所有节点已经组合完成,
剩下的唯一一个节点即是哈夫曼树的根节点
*/
while (nodes.size() > 1){
//将节点集合从小到大进行排序
//注意:如果在节点类没有实现Comparable接口,则无法使用
Collections.sort(nodes);
//在集合内取出权值最小的两个节点
Node leftNode = nodes.get(0);
Node rightNode = nodes.get(1);
//以这两个节点创建一个新的二叉树,它们的父节点的权值即是它们的权值之和
Node parent = new Node(leftNode.weight + rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
//再从集合中删除已经组合成二叉树的俩个节点,并把它们俩个的父节点加入到集合中
nodes.remove(leftNode);
nodes.remove(rightNode);
nodes.add(parent);
}
//返回哈夫曼树的根节点
return nodes.get(0);
}
}
//因为要在节点的集合内,以节点的权值value,从小到大进行排序,所以要实现Comparable<>接口
class Node implements Comparable<Node>{
int weight;//节点的权值
Node left;
Node right;
public Node(int weight) {
this.weight = weight;
}
public void preOrder(){
System.out.println(this);
if (this.left != null){
this.left.preOrder();
}
if (this.right != null){
this.right.preOrder();
}
}
@Override
public String toString() {
return "Node{" +
"weight=" + weight +
'}';
}
@Override
public int compareTo(Node o) {
return this.weight - o.weight;
}
}
哈夫曼编码
定长编码
固定长度编码一种二进制信息的信道编码。这种编码是一次变换的输入信息位数固定不变。简称“定长编码”。
如将字符串 ”

可变长度编码
根据字符出现的频率进行编码,频率越高编码越短。
如上面的字符串中字符 i 出现了5次,那么可以将它编码为0,而字符 d 只出现了1次,则将它编码为0101.
哈夫曼编码
在编码优化时,不仅要缩短编码后的长度,还有考虑是否符合前缀编码的要求,否则编码后将不能恢复回原先数据。而哈夫曼编码就是符合前缀编码要求的可变长度编码。
前缀编码:字符的编码都不能是其他字符编码的前缀,符合该条件的编码称为前缀编码。
哈夫曼编码思路
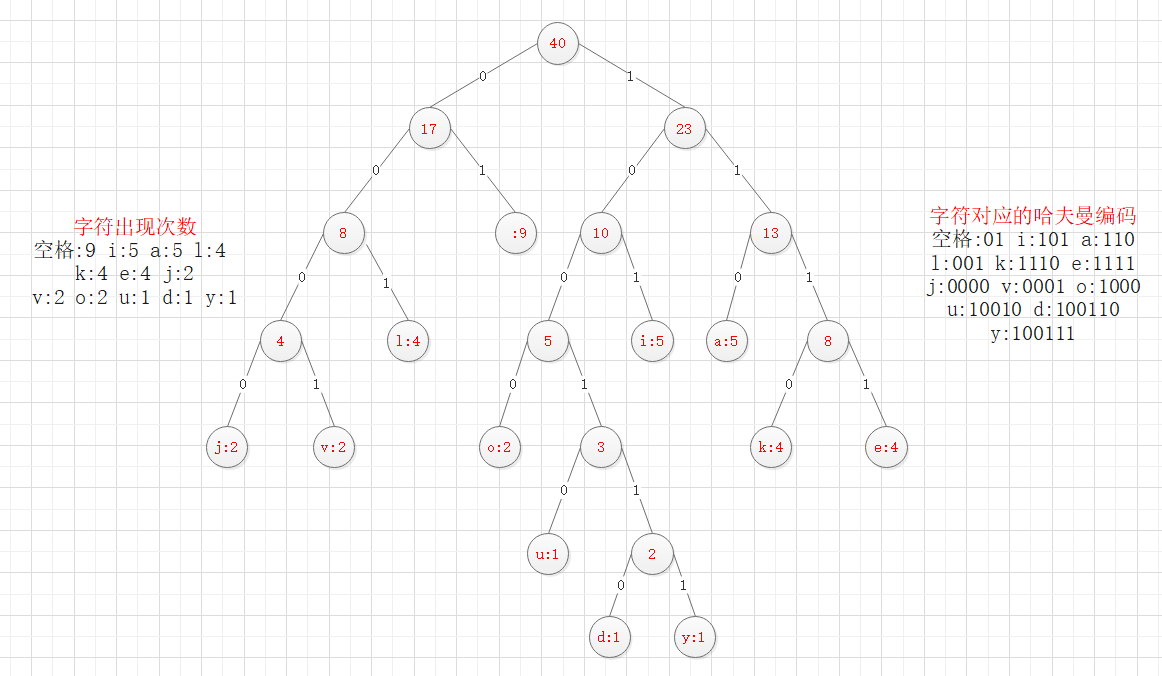
将字符出现的次数作为权值,把字符串转换成哈夫曼树,往左节点的路径为0,往右节点的路径为1。
如下图,将字符串"i like like like java do you like a java“ 中的字符转换成哈夫曼树,转换后的字符串的哈夫曼编码为:
1010100110111101111010011011110111101001101111011110100001100001110011001101000011001111000100100100110111101111011100100001100001110
编码长度为133,比定长编码的长度缩短了大半,缩短率约为:(320-133) / 320 = 58.4%
注:转换后的哈夫曼树不一定要和下图结构一致,只需树的带权路径长度一致就行。
使用哈夫曼编码解压缩
基础代码
创建哈夫曼树节点类
class Node2 implements Comparable<Node2>{
Byte data;//节点对应数据的字节值
int weight;//节点权值,即数据出现的次数
Node2 left;
Node2 right;
public Node2(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
public void preOrder(){
System.out.println(this);
if (this.left != null){
this.left.preOrder();
}
if (this.right != null){
this.right.preOrder();
}
}
@Override
public String toString() {
return "Node2{" +
"data=" + data +
", weight=" + weight +
'}';
}
@Override
public int compareTo(Node2 o) {
return this.weight - o.weight;
}
}创建哈夫曼树类,在类中创建一些基本 的属性和遍历方法
class HuffmanCodeTree{
//储存数据字节对应的哈夫曼树
Map<Byte, String> huffmanCodes = new HashMap<>();
//用于拼接字符串
StringBuilder stringBuilder = new StringBuilder();
//前序遍历
public void preOrder(Node2 root){
if (root == null){
System.out.println("哈夫曼树为空,无法遍历");
}else {
root.preOrder();
}
}
}压缩代码
/**
* 创建哈夫曼树
* @param bytes 需转成哈夫曼树的数据字节数组
* @return
*/
public Node2 create(byte[] bytes){
//储存数据字节在数据字节组出现的次数
Map<Byte, Integer> counts = new HashMap<>();
//遍历数据字节组,如果counts有该字节key则将次数+1,没有则设置次数为1
for (byte b : bytes){
Integer count = counts.get(b);
if (count == null){
counts.put(b, 1);
}else {
counts.put(b, count+1);
}
}
//根据counts映射创建节点集合
List<Node2> node2s = new ArrayList<>();
for (Map.Entry<Byte, Integer> entry : counts.entrySet()){
node2s.add(new Node2(entry.getKey(), entry.getValue()));
}
while (node2s.size() > 1){
Collections.sort(node2s);
Node2 leftNode = node2s.get(0);
Node2 rightNode = node2s.get(1);
Node2 parent = new Node2(null, leftNode.weight + rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
node2s.remove(leftNode);
node2s.remove(rightNode);
node2s.add(parent);
}
return node2s.get(0);
}2.创建一个生成哈夫曼编码的类,根据创建的哈夫曼树生成哈夫曼编码
//重载
public void getHuffmanCodes(Node2 root){
if (root == null){
return null;
}
getHuffmanCodes(root.left, "0", stringBuilder);
getHuffmanCodes(root.right, "1", stringBuilder);
}
/**
* 根据数据的哈夫曼树获取哈夫曼编码
* 如:{32=01, 97=100, 100=11000, 117=11001, 101=1110, 118=11011, 105=101, 121=11010, 106=0010, 107=1111, 108=000, 111=0011}
* @param node2 节点
* @param path 路径:左节点为0,右节点为1
* @param stringBuilder 用于拼接路径
*/
public void getHuffmanCodes(Node2 node2, String path, StringBuilder stringBuilder){
//为了不影响上个递归前进段,需创建一个新的StringBuilder
StringBuilder stringBuilder2 = new StringBuilder(stringBuilder);
//将路径path拼接
stringBuilder2.append(path);
if (node2 != null){//如果该节点为空,则已经超过哈夫曼树范围
//判断该节点是不是叶子节点
if (node2.data == null){
//如果是非叶子节点则分别向左和向右进行递归
getHuffmanCodes(node2.left, "0", stringBuilder2);
getHuffmanCodes(node2.right, "1", stringBuilder2);
}else {
//如果是叶子节点,则说明该叶子节点的哈夫曼编码已经完成,添加进哈夫曼编码映射
huffmanCodes.put(node2.data, stringBuilder2.toString());
}
}
}3.在哈夫曼树类中创建一个转换方法,根据字符的哈夫曼编码将数据字节数组转换成哈夫曼编码格式的字符串,在将该字符串存储成字节数组
/**
* 根据哈夫曼编码将传入的数据字节组全部转成哈夫曼编码格式的字符串,
* 再将字符串以8位为1字节的格式储存成字节数组(需将8位二进制转成整型再储存)
* 又因为压缩时二进制转字节和解压时字节转二进制会有所变动(解压时说明),
* 所以需要在切割时将最后一段二进制的最后一个1前的所有0记录下来,
* 并把这些零的数量保存在返回字节数组的最后
* 如:[105,32,108,105,107,101,32,108,105,107,101,32,108,105,107,101,32,106,97,118,97,32,100,111,32,121,111,117,32,108,105,107,101,32,97,32,106,97,118,97] =>
* 1010100010111111110010001011111111001000101111111100100101001101110001110000011011101000111100101000101111111100110001001010011011100 =>
* [-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28, 0]
* @param huffmanCodes 哈夫曼编码映射
* @param bytes 需转码的数据字节数组
* @return 哈夫曼编码格式字符串的整形字节数组
*/
public byte[] getHuffmanCodeBytes(Map<Byte, String> huffmanCodes, byte[] bytes){
StringBuilder stringBuilder = new StringBuilder();
//根据传入的数据字节数组从哈夫曼编码映射中取出相应的编码,并拼接
for (int i=0; i<bytes.length; i++){
stringBuilder.append(huffmanCodes.get(bytes[i]));
}
/*
虽然将数据字节数组转成了哈夫曼编码格式,但是转换后的字符串长度并没有比原先短,反而更长了,
所以要将转换后的字符串再以8位为1字节(1字节最多只能存储8位)转换成整型存进新的字节数组
*/
int len;//转换后新的字节数组的长度
int strLength = stringBuilder.length();//赫夫曼编码格式字符串的长度
int zeroCount = 0;//解压时需补零的数量
int subIndex = 0;//判断补零数量的开始切割索引
//因为转换后的字符串不一定刚好能被8整除,所以为了防止超出范围异常,需判断
if (stringBuilder.length() % 8 == 0){
//因为需要储存补零的数量,所以需+1
len = strLength / 8 +1;
//当字符串长度能被8整除时,那补零数量判断的开始索引就是字符串长度-8
subIndex = strLength - 8;
/*
补零数量判断逻辑:
从开始索引进行判断,当等于0时,就把补零的数量+1,并将开始索引往后移动一位
因为当开始索引到字符串最后一位时,仍然是0的话,即最后一段二进制全部都是0,
这时转换成字节整型为0,当解压时重新把字节转换成二进制字符串时也是0,
所以字符串长度最后一位无论是不是零都不影响,无需判断
*/
while (subIndex<strLength-1 && stringBuilder.substring(subIndex, subIndex+1).equals("0")) {
zeroCount++;//补零数量+1
subIndex++;//并将切割开始索引往后移动一位
}
}else {
//如果不能被8整除,字节数组的长度还需+1
len = strLength / 8 + 2;
//不能被8整除时,补零长度判断的开始索引就是字符串数量减去它们的余数
subIndex = strLength - strLength % 8;
while (subIndex<strLength-1 && stringBuilder.substring(subIndex, subIndex+1).equals("0")) {
zeroCount++;
subIndex++;
}
}
//储存哈夫曼编码格式的数据字符串转换后的字节
byte[] huffmanCodeBytes = new byte[len];
//将补零数量储存在字节数组的最后的位置
huffmanCodeBytes[len-1] = (byte)zeroCount;
int index = 0;//字节数组的下标索引
//遍历哈夫曼编码格式的数据字符串, 每次递增8位
for (int i=0; i<strLength; i+=8){
String strBytes;//储存从字符串中切割出来的二进制
//为了防止范围超出,需判断字符串从i下标到转换后的字节数组末尾的长度是否>8
if (i+8 < strLength){
strBytes = stringBuilder.substring(i, i+8);
}else {
//如果剩余不足8位,则把剩下的二进制取出即可
strBytes = stringBuilder.substring(i);
}
//将切割出的二进制转换成整型,并储存进转换后的字节数组
huffmanCodeBytes[index] = (byte)Integer.parseInt(strBytes, 2);
index++;
}
return huffmanCodeBytes;
}4.在哈夫曼树类中创建一个压缩方法,调用上面的所有方法
//使用哈夫曼编码进行压缩
public byte[] huffmanZip(byte[] bytes){
Node2 root = create(bytes);
getHuffmanCodes(root);
return getHuffmanCodeBytes(huffmanCodes, bytes);
}解压代码
1.在哈夫曼树类中创建一个字节转二进制的方法,将传入的字节转换成二进制字符串
/**
* 将字节转换成二级制字符串
* 因为在压缩时除了最后一段二进制都是满8位的,而在解压时转换后的二进制会自动去掉最后一位1前面的所有0
* 如:压缩: 01001101 => 77,解压: 77 => 1001101,差了个0,
* 所以在转换成二进制字符串时,需要进行补高位,即在最后一个1前面补0直到长度等于8位
* 但是有一个是例外的,即是转换字节组除开补零数的最后一个数,因为在压缩时它可能是不满8位二进制的,要额外处理
* @param b 需转换的字节
* @param flag 是否是数组中最后一个数据
* @param zeroCount 补零的长度
* @return 返回字节对应的二进制字符串
*/
public String byteToBinaryString(byte b, boolean flag, int zeroCount){
//将字节转成整型,以便使用Integer的方法转成二进制字符串
int temp = b;
/*
因为除了数组的最后一个,其它数据在压缩时的二进制都是满足8位的,
所以在解压时(除外最后一个数据),只需在不足8位的时候补高位,即只要按位或|256 (100000000),
如:77 => 1001101 按位或256(100000000) => 101001101
然后再取字符串的最后8位即可获得原先压缩时的二进制字符串
*/
//如果不是最后一个则按位或|256,不足8位的补高位,够8位则不会变
if (!flag){
temp |= 256;
}
//将整型转成二级制字符串
String binaryString = Integer.toBinaryString(temp);
if (!flag){//判断是否是最后一个
//不是,则因为按位或256的原因,只需取二进制字符串的最后8位
return binaryString.substring(binaryString.length() - 8);
}else {//不是则补零后返回
//补零的字符串
String zeroStr = "";
for (int i=0; i<zeroCount; i++){
zeroStr += "0";
}
//将补零字符串添加到转换后的二进制字符串前面
return (zeroStr + binaryString);
}
}2.在哈夫曼类中创建一个解压方法,调用上面的方法将整形字节数组转成二进制字符串,再将二进制字符串通过字节的哈夫曼编码映射恢复回原先数据字节数组
/**
* 使用根据哈夫曼编码进行解压
* @param huffmanCodes 数据对应的哈夫曼编码映射
* @param bytes 需解压的字节数组
* @return 解压后数据的字节
*/
public byte[] decode(Map<Byte, String> huffmanCodes, byte[] bytes){
//用于拼接需解压字节转换后的二进制字符串
StringBuilder stringBuilder = new StringBuilder();
int zeroCount = bytes[bytes.length-1];//将补零数量从字节组中取出
//遍历需解压字节数组(最后一位是补零数量,要除开)
for (int i=0; i<bytes.length-1; i++){
//判断是否是数组中除开补零数量的最后一个数
boolean flag = (i == bytes.length-2);
//把转换后的二进制字符串进行拼接
stringBuilder.append(byteToBinaryString(bytes[i], flag, zeroCount) );
}
//因为解压时需通过二进制字符串获取哈夫曼编码对应的字节,所以需将哈夫曼编码映射关系倒过来
Map<String, Byte> decodeHuffmanCodes = new HashMap<>();
for (Map.Entry<Byte, String> entry : huffmanCodes.entrySet()){
decodeHuffmanCodes.put(entry.getValue(), entry.getKey());
}
//存放二进制字符串通过哈夫曼编码映射转换后的字节
List<Byte> list = new ArrayList<>();
/*
将拼接二级制字符串根据赫夫曼编码转换成字节的逻辑:
1. 设置俩个指针用于切割二级制字符串,一个指向起点(开始为0),一个指向终点(开始为起点+1)
2. 根据两个指针切割二进制字符串得到一段二进制,再以该段二进制为key从哈夫曼编码映射中取值
3.1 如果取到的值为空,则表示为该段二进制没有对应的字节,则将终点指针后移一位,继续步骤2的操作
3.2 如果取到的值不为空,则将该值添加进解压结果集合,并将起点指针指向终点
*/
for (int i=0; i<stringBuilder.length();){
//储存根据二进制从哈夫曼编码映射中取出的字节
Byte b = null;
//切割终点指针
int end = i;
while (b==null){//判断取值是否为空
end ++;//为空,将终点指针向后移一位
//从拼接后的二进制字符串切割除一段二进制
String key = stringBuilder.substring(i, end);
//根据切割出的二进制从哈夫曼编码映射中取出相应的值
b = decodeHuffmanCodes.get(key);
}
//当取值不为空时,将取值添加进解压结果集,并把起点指针指向终点
list.add(b);
i = end;
}
//将结果集合转换成字节数组的形式,再返回
byte[] decodeResult = new byte[list.size()];
for (int i=0; i<decodeResult.length; i++){
decodeResult[i] = list.get(i);
}
return decodeResult;
}对文件进行解压缩
/**
* 压缩文件
* @param srcFile 需压缩的文件路径
* @param dstFile 压缩后的文件存放路径
*/
public void fileZip(String srcFile, String dstFile){
InputStream is = null;
OutputStream os = null;
ObjectOutputStream oos = null;
try {
is = new FileInputStream(srcFile);
//将文件转换成字节数组
byte[] bytes = new byte[is.available()];
is.read(bytes);
//对字节数组进行压缩
byte[] huffmanBytes = huffmanZip(bytes);
os = new FileOutputStream(dstFile);
oos = new ObjectOutputStream(os);
//将压缩后的字节数组和字节的哈夫曼编码写入文件中
oos.writeObject(huffmanBytes);
oos.writeObject(huffmanCodes);
}catch (Exception e){
System.out.println(e.getMessage());
}finally {
try {
oos.close();
os.close();
is.close();
}catch (IOException e){
System.out.println(e.getMessage());
}
}
}
/**
* 解压文件
* @param srcFile 需解压的文件路径
* @param dstFile 解压后的文件存放路径
*/
public void unzipFile(String srcFile, String dstFile){
InputStream is = null;
ObjectInputStream ois = null;
OutputStream os = null;
try{
is = new FileInputStream(srcFile);
ois = new ObjectInputStream(is);
//将文件压缩后的整形字节数组和字节的哈夫曼编码从文件中取出
byte[] huffmanBytes = (byte[])ois.readObject();
Map<Byte, String> huffmanCodes = (Map<Byte, String>)ois.readObject();
byte[] unzipResult = decode(huffmanCodes, huffmanBytes);
os = new FileOutputStream(dstFile);
//将解压后的字节数组写入文件
os.write(unzipResult);
}catch (Exception e){
System.out.println(e.getMessage());
}finally {
try{
os.close();
ois.close();
is.close();
}catch (IOException e){
System.out.println(e.getMessage());
}
}
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号