python 使用selenium模块爬取同一个url下不同页的内容(浏览器模拟人工翻页)
页面翻页,下一页可能是一个新的url
也有可能是用js进行页面跳转,url不变,解决方法是实现浏览器模拟人工翻页
目标:爬取同一个url下不同页的数据(上述第二种情况)
url:http://www.gx211.com/collegemanage/search.aspx?id=1&xxcity=1
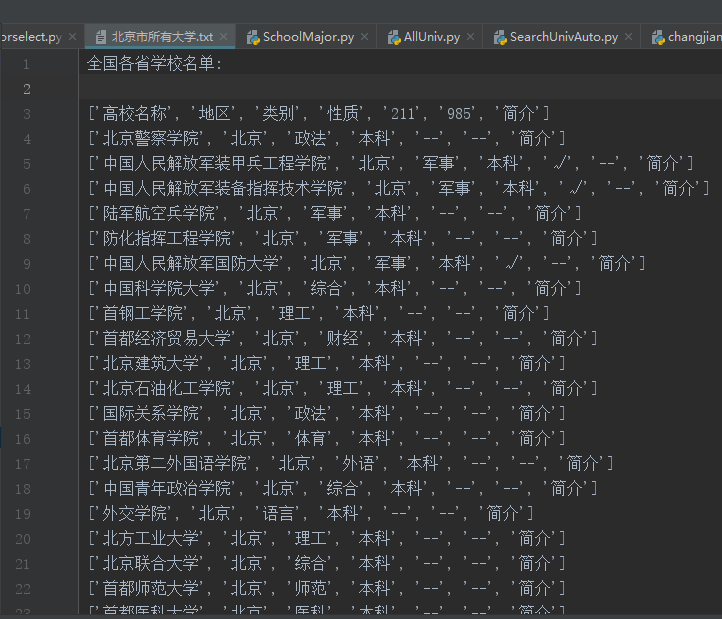
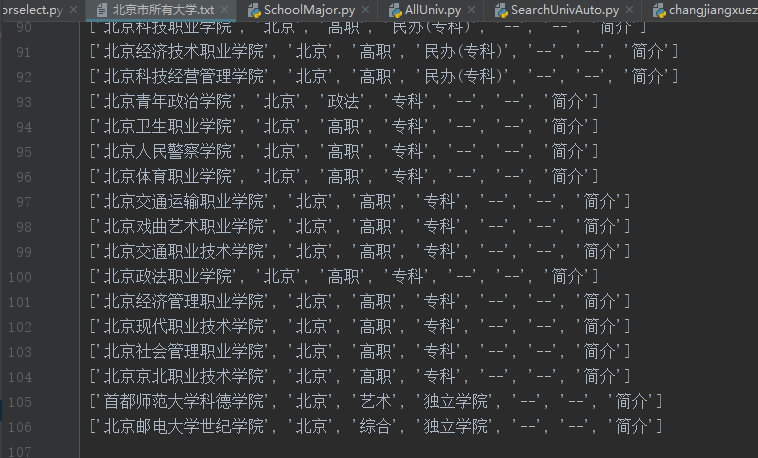
中国高校之窗,我要爬取北京市所有的学校列表,共有四页数据,四页都是同一个url。
部分页面如图:
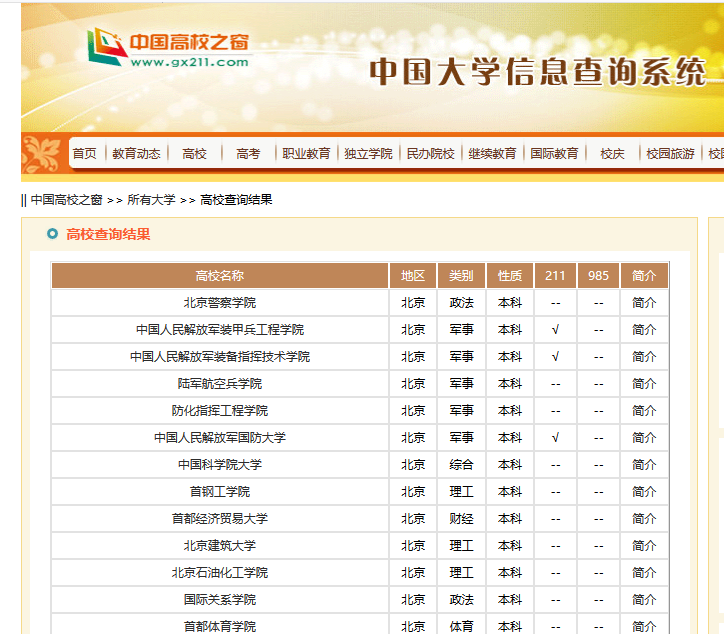
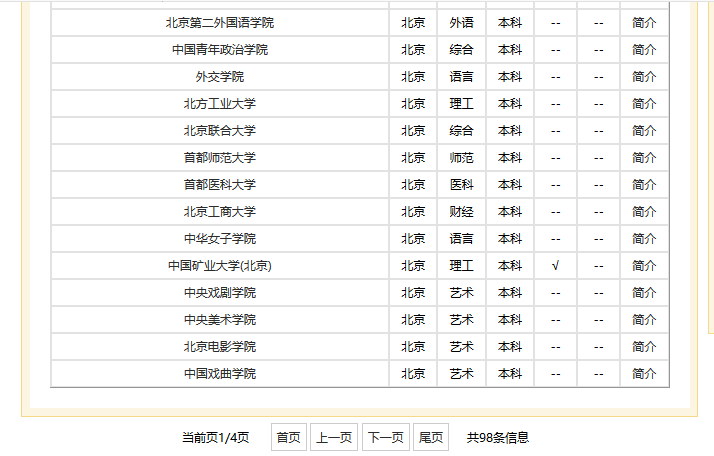
找到“下一页”按钮的源码,确认是用js进行的跳转。

工具:
- selenium
- pyquery
- 火狐浏览器
代码:
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from pyquery import PyQuery as pq # # 爬取北京市所有的学校 # browser = webdriver.Firefox() # 创建一个浏览器对象,这里还可以使用chrome等浏览器 try: BJuniv = [] browser.get('http://www.gx211.com/collegemanage/search.aspx?id=1&xxcity=1') # 获取并打开url for r in range(4): html = browser.page_source # 获取html页面 doc = pq(html) # 解析html table = doc('.content tbody') # 定位到表格 table.find('script').remove() # 除去script标签 list_cont = table('tr').items() # 获取tr标签列表 for i in list_cont: univ = (i.text()).split() # 获取每个tr标签中的文本信息,返回一个列表 print(univ) BJuniv.append(univ) nextpagebutton = browser.find_element_by_xpath('//*[@id="Lk_Down"]') # 定位到“下一页”按钮 nextpagebutton.click() # 模拟点击下一页 wait = WebDriverWait(browser, 10) # 浏览器等待10s finally: browser.close() # 关闭浏览器 with open("北京市所有大学.txt", "wt", encoding='utf8') as out_file: # 存储为txt格式 out_file.write('全国各省学校名单:\n\n') for u in BJuniv: out_file.write(str(u) + '\n')
运行过程:自动打开浏览器,输入url,获取页面,点击下一页,重复直到循环结束。(过程看不到很细致的,跳转比较快)
运行结果(部分):