Python爬取高清壁纸
需要准备的东西:
- 用到的网址:https://wall.alphacoders.com/
- 用到的环境:python3.7
- 用到的ide:pycharm
- 用到的库 time、BeautifulSoup、requests
本次的目标:
- 下载几百张海贼王的高清壁纸
- 练习爬虫
分析网页
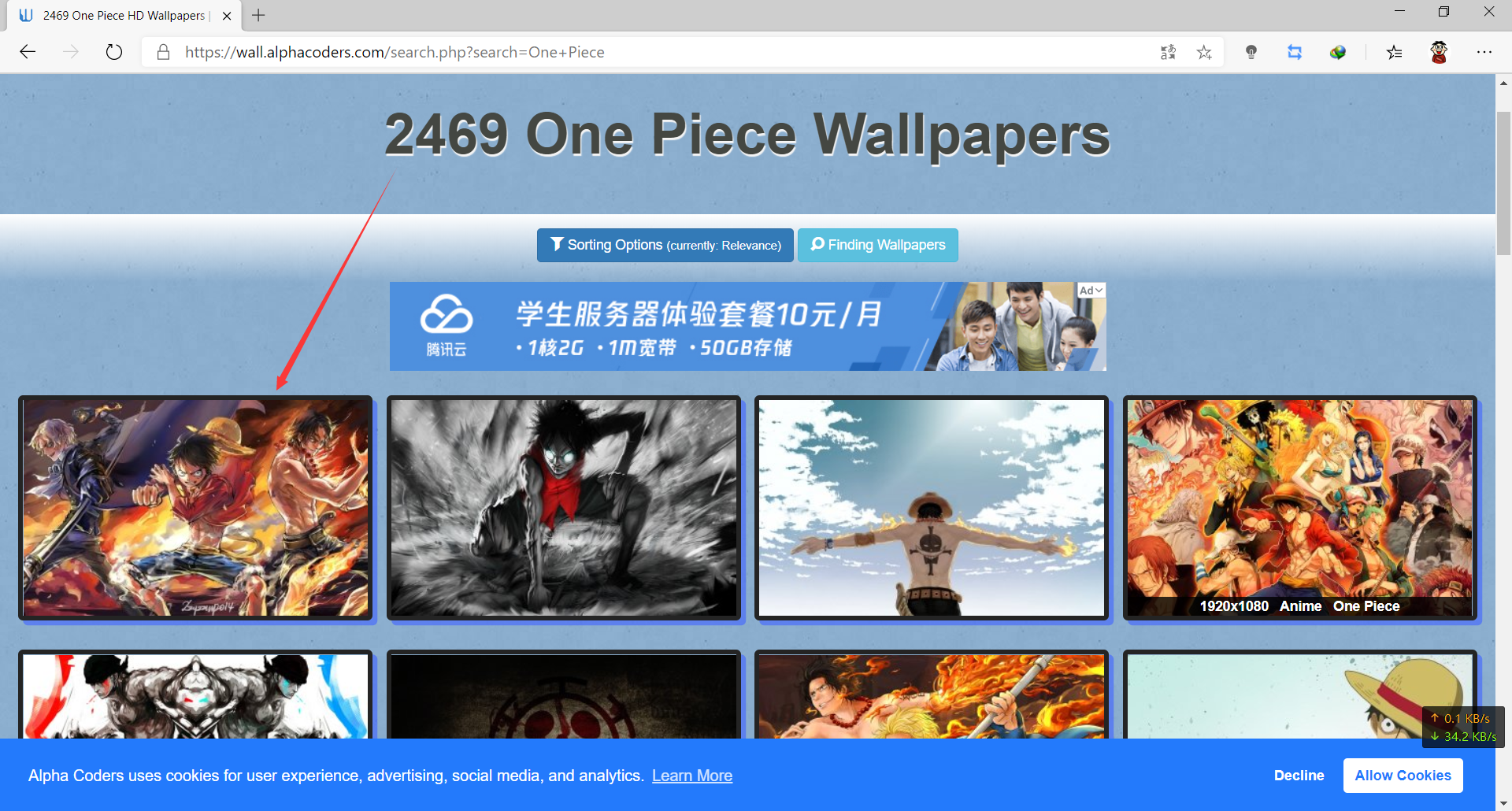
首先,我们进入这个网站,搜索海贼王,还是挺好看的

打开我们的分析工具(按F12)并刷新这个网页,这个数据这么多,很明显就是这个页加载了大量的图片

然后我们右键单击任意一张图片,复制图像链接
在刚刚那个单页里面搜索这个 链接,试试打开这个链接(怎么打开我应该不用说了)
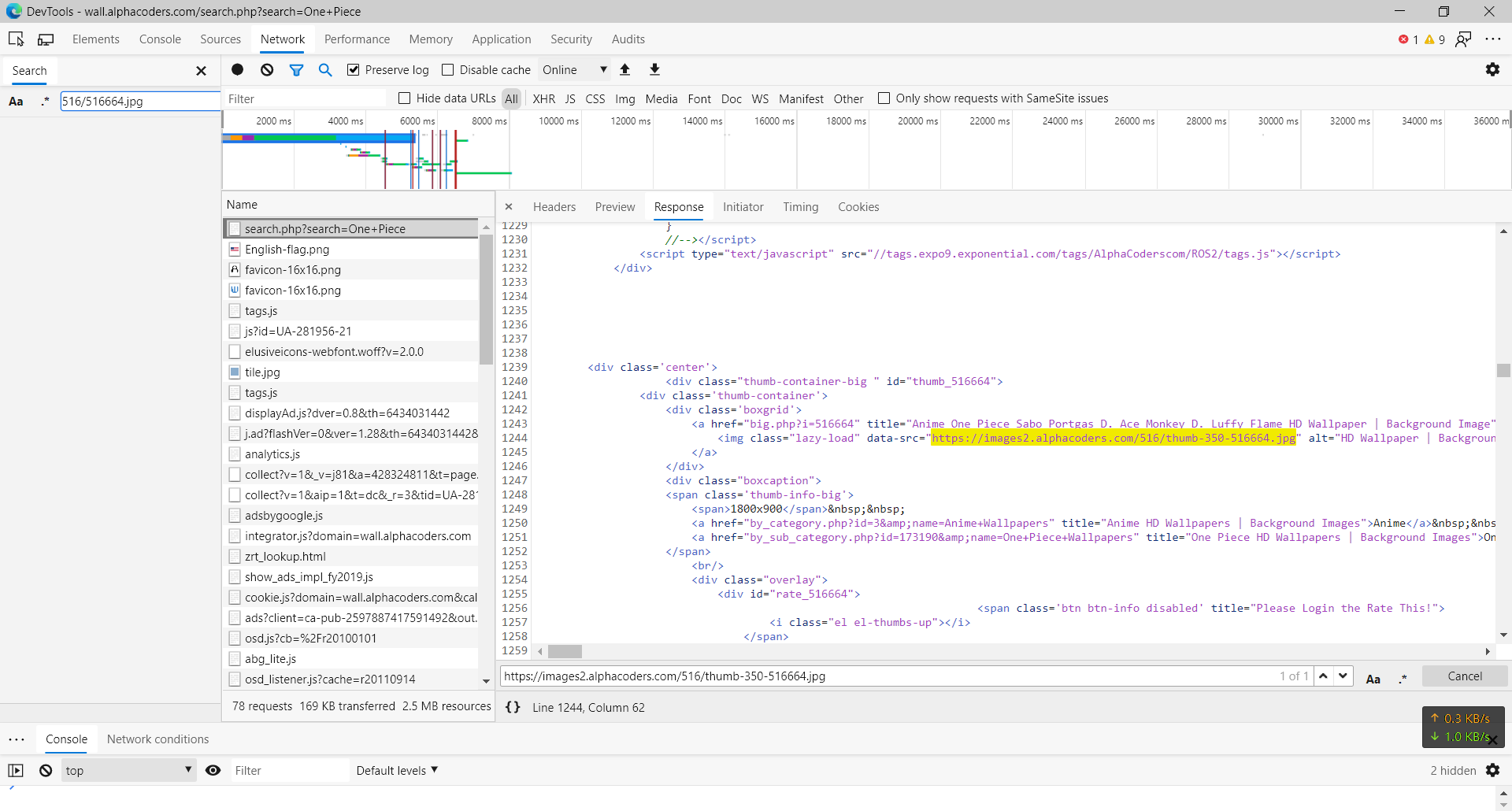
打开链接

哎~,这个图片怎么这么小,和我们想象的高清壁纸不太一样,看来我们还得继续分析,接下来返回那个网站,点击进入这个图片发现:

这个图一点也不小啊,为什么我们提取出来就变小了呢,接下来复制这个大图的链接和小图链接对比一下
- 大图链接:https://images2.alphacoders.com/516/516664.jpg
- 小图链接:https://images2.alphacoders.com/516/thumb-350-516664.jpg
很明显小图链接多了thumb-350-应该是为了加快加载进度做的缩略图,没关系,这个东西在Python里面可以很轻易的去除
接下来进入代码时刻:
import requests
import time
from bs4 import BeautifulSoup
class downloader():
def __init__(self):
self.url=[];
self.target = 'https://wall.alphacoders.com/search.php?search=One+Piece'
def find_down(self):
req = requests.get(self.target)
print(req.text)
#没有什么新的知识点,所以未加注释
if __name__ == '__main__':
gp = downloader()
gp.find_down()
运行结果:

很明显我们把整个网站爬下来了,但是我们需要的仅仅是链接而已,下面进行分析,并用BeautifulSoup库过滤不必要的东西
这个很简单,根据我们上次的知识直接过滤就ok
import requests
import time
from bs4 import BeautifulSoup
class downloader():
def __init__(self):
self.url=[];
self.target = 'https://wall.alphacoders.com/search.php?search=One+Piece'
def find_down(self):
req = requests.get(self.target)
html = req.text
bf = BeautifulSoup(html)
div = bf.find_all('div',class_='boxgrid') #只保留class=boxgrid的数据,也就是图片链接
print(div)
if __name__ == '__main__':
gp = downloader()
gp.find_down()
运行结果:

对了,我们想要的就是这些,但是还需要进一步过滤,过滤img标签:
import requests
import time
from bs4 import BeautifulSoup
class downloader():
def __init__(self):
self.target = 'https://wall.alphacoders.com/search.php?search=One+Piece'
def find_down(self):
req = requests.get(self.target)
html = req.text
bf = BeautifulSoup(html)
div = bf.find_all('div',class_='boxgrid') #只保留class=boxgrid的数据,也就是图片链接
img = BeautifulSoup(str(div))
print(img)
if __name__ == '__main__':
gp = downloader()
gp.find_down()
运行结果:

看起来基本上没有任何作用,下面我们通过data-src来取出这些链接,至于为什么用data-src,上面图中有
完全过滤代码:
import requests
import time
from bs4 import BeautifulSoup
class downloader():
def __init__(self):
self.target = 'https://wall.alphacoders.com/search.php?search=One+Piece'
def find_down(self):
req = requests.get(self.target)
html = req.text
bf = BeautifulSoup(html)
div = bf.find_all('div',class_='boxgrid') #只保留class=boxgrid的数据,也就是图片链接
img = BeautifulSoup(str(div))
img_data = img.find_all('img')
for each in img_data:
print(each.get('data-src'))
if __name__ == '__main__':
gp = downloader()
gp.find_down()
运行结果:

这一片蓝蓝的url就是我们需要的了,但是我们似乎忽略的一件事,那就是我们现在只是获取了一页的url,我们需要爬更多页的怎么办,下面我们一起来分析一下,首先打开抓包工具(还是那个F12),然后点击第二页,看一下url有什么区别
然后我们发现,第二页的url是:https://wall.alphacoders.com/search.php?search=one+piece&page=2
所以也就不用分析了,第三页的url肯定是page=3,以此类推...
爬取任意页到任意页代码:
import requests
import time
from bs4 import BeautifulSoup
class downloader():
def __init__(self):
self.target = 'https://wall.alphacoders.com/search.php?search=one+piece&page='
def find_down(self):
for i in (1,5):
self.target = self.target + str(i) #到整数的i
req = requests.get(self.target)
html = req.text
bf = BeautifulSoup(html)
div = bf.find_all('div',class_='boxgrid') #只保留class=boxgrid的数据,也就是图片链接
img = BeautifulSoup(str(div))
img_data = img.find_all('img')
for each in img_data:
print(each.get('data-src'))
if __name__ == '__main__':
gp = downloader()
gp.find_down()
不难发现,我们其实只加了两行代码,就实现了获取多页的功能,下面我们来把多余的thumb-350-过滤掉
过滤代码:
img = BeautifulSoup(str(div))
img_data = img.find_all('img')
img_data = str(img_data) #str是转为文本型
img_url = img_data.replace('thumb-350-','') #把thumb-350-替换为空
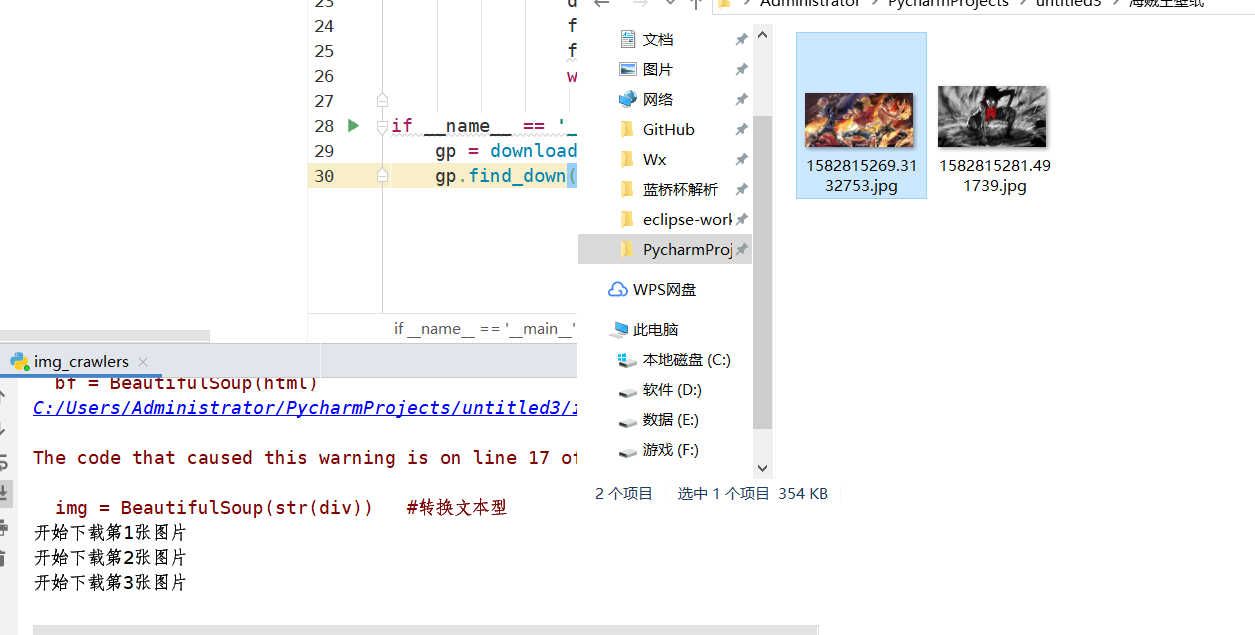
既然所有工作都已完成,现在我们就完成程序,把图片下载下来
完整代码:
import requests
import time
from bs4 import BeautifulSoup
class downloader():
def __init__(self):
self.target = 'https://wall.alphacoders.com/search.php?search=one+piece&page='
def find_down(self):
num = 1
path = 'C:\\Users\\Administrator\\PycharmProjects\\untitled3\\海贼王壁纸\\'
for i in (1,5):
print('开始下载第'+str(i)+'页')
self.target = self.target + str(i) #到文本的i,页数
req = requests.get(self.target)
html = req.text
bf = BeautifulSoup(html)
div = bf.find_all('div',class_='boxgrid') #只保留class=boxgrid的数据,也就是图片链接
img = BeautifulSoup(str(div)) #转换文本型
imgs = img.find_all('img') #匹配img标签
for each in imgs:
print('开始下载第'+str(num)+'张图片')
num = num + 1
data = each.get('data-src') #获取data-src后面的内容,也就是链接
data = str(data).replace('thumb-350-', '') #替换thumb-350-为空
file = requests.get(data) #访问图片文件
fileName = str(time.time()) #取现行时间戳,时间戳含义请百度
with open(path + fileName +'.jpg','wb')as f: #写文件,wb是权限
f.write(file.content) #写文件
if __name__ == '__main__':
gp = downloader()
gp.find_down()
#本次代码还留下了几处可以完善的地方,增加运行效率
运行效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号