
【数据结构】FHQ Treap 详解
FHQ Treap 是什么?
前置知识:
C++二叉搜索树的基本性质,下面会讲二叉堆
二叉搜索树的基本性质
很简单,就这几个。
- 在
二叉搜索树中,每个结点都满足左子树的结点的值都小于等于自己的值,右子树的结点的值都大于自己的值,左右子树也是二叉搜索树。 - 中序遍历
二叉搜索树可以得到一个由这棵树的所有结点的值组成的有序序列。(即所有的值排序后的结果)
原理&代码实现
本文中,
Treap就是指有旋Treap。
FHQ Treap不是通过旋转来保持平衡的,而是通过两个函数split和merge。顾名思义,split就是分裂,merge就是合并。当然,从最底层的原理来看,还不是这两个函数。FHQ Treap中的Treap代表Tree + Heap,也就是说,FHQ Treap会按二叉搜索树一样根据键值排序结点,并且随机赋给每个结点一个优先级,按照二叉堆的顺序排序结点(这里用大根堆)。Treap通过旋转,使平衡树同时满足这两个性质,从而达到平衡。而FHQ Treap通过调用merge函数时使平衡树满足堆序,实现原理与Treap不同。
结点信息
template <typename T, int MaxSize>
class FHQTreap
{
public:
FHQTreap() { Seed = (int)(MaxSize * 565463ll % 2147483647); }
// ...
private:
struct Node
{
T Key;
int Left, Right, Size, Priority;
} Tree[MaxSize];
int Seed, Total, Root;
int random() { return Seed = (int)(Seed * 104831ll % 0x7fffffff); }
void pushup(int root) {
if (root != 0) {
Tree[root].Size = Tree[Tree[root].Left].Size + Tree[Tree[root].Right].Size + 1; // + 1是要算上自己
}
}
// ...
}
Node即结点,里面的Key就是要存的值,Priority即优先级。Seed就是随机数种子,在构造函数中初始化,random()会生成一个在int范围内的整数,作为结点的优先级。(我自己写随机数生成函数只是个人习惯)
构造新结点
int create(T key) {
int root = ++Total;
Tree[root].Key = key;
Tree[root].Size = 1;
Tree[root].Left = Tree[root].Right = 0;
Tree[root].Priority = rad();
return root;
}
create(T key)会初始化一个结点,并返回它的ID,大家也可以用指针实现。这里比较简单,就不多解释了。
split函数
split分为两种:
- 按值分裂:根据一个值\(key\)把一棵树分裂成两棵树,一棵树的值全部小于等于\(key\),另外一棵全部大于\(key\)
- 按大小分裂:根据一个值\(size\)分裂树,一棵的大小为\(size\),另外一棵为剩下的。
按值分裂
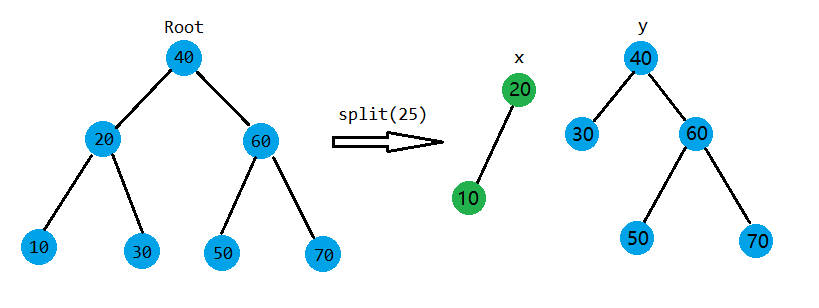
如上图。这里split函数简化了,只写了值。根据图可以看出,比\(25\)小的结点都被分裂到以\(x\)为根的树上,比\(25\)大的结点被分到了\(y\)树上。
那我们该怎么写呢?如果我们到了一个结点\(root\),假设\(X,Y\)是分裂后的两棵树,且满足\(\forall i \in X,j \in Y ,Key_{i} < Key_{j}\),要是\(Key_{root} \leq key\),那它就应该被放到\(X\)树上,否则它应该被放到\(Y\)树上。如果它被放到了\(X\)树上,我们还要再检查一下是否有结点\(z\),满足\(Key_{root} \leq Key_{z} \leq key\),如果有,也要插入\(X\)树,具体的操作就是把\(z\)挂到\(root\)的右子树上,这可以通过继续递归调用split函数实现。如果满足\(Key_{root} > key\),就做一次相反的过程。
void split(int root, int key, int &x, int &y) { // x, y即分裂出的两个树
if (root == 0) {
x = y = 0;
return;
}
if (!(key < Tree[root].Key)) { // 等价于 Tree[root].Key <= key
x = root; // 把root设为x树的根(当前)
split(Tree[root].Right, key, Tree[root].Right, y); // 找更大的结点
} else {
y = root; // 相反过程
split(Tree[root].Left, key, x, Tree[root].Left);
}
pushup(root); // 记得更新大小
}
按大小分裂
void split(int root, int sze, int &x, int &y) {
if (root == 0) {
x = y = 0;
return;
}
if (Tree[Tree[root].Left].Size + 1 <= sze) {
x = root;
split(Tree[root].Right, sze - Tree[Tree[root].Left].sze - 1, Tree[root].Right, y);
} else {
y = root;
split(Tree[root].Left, sze, x, Tree[root].Left);
}
pushup(root);
}
merge函数
我比较懒,把上面那个图复制粘贴了一下。
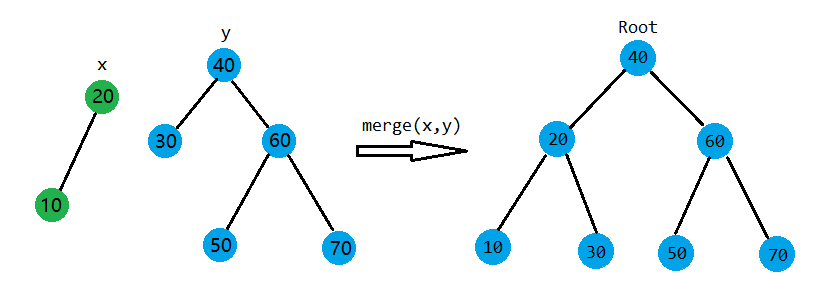
假设\(X,Y\)是需要合并的两棵树,且满足\(\forall i \in X,j \in Y ,Key_{i} < Key_{j}\),\(x\)为\(X\)根节点,\(y\)为\(Y\)根节点。所以,在合并的时候,我们只要按照优先级,看一下是把\(x\)放在上还是把\(y\)放在上。以下是\(x,y\)在不同的优先级关系下的树的结构:
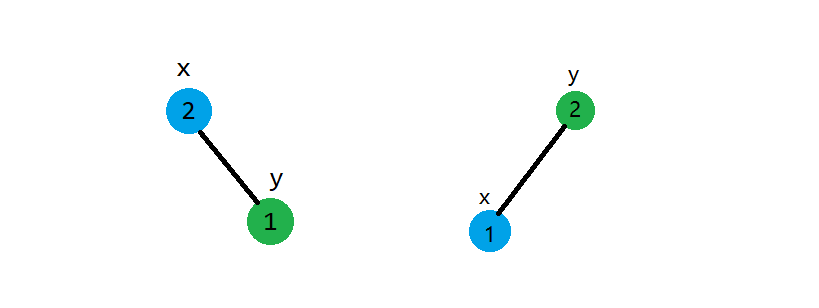
如果我们已经确定好了\(x,y\)这两个点的结构,那就直接拿那个被替换的子树与在下面的结点去merge。说起来比较抽象,我们就用上面那个图的左边那种情况作为例子(这个图是只考虑\(x,y\)两个结点的,并没有算上它们的子树)。\(x\)的优先级比\(y\)的优先级大(按照大根堆),那么\(x\)就在上,\(y\)在下。那么有要满足二叉搜索树的性质,\(y\)的值比\(x\)大,则\(y\)在右边,即在\(x\)的右子树。如果在考虑\(x,y\)两个结点都子树的情况,\(x\)的左子树不动,把\(y\)和\(x\)的右子树合并的结果作为\(x\)新的右子树。另外一种情况同理。
int merge(int x, int y) {
if (x == 0 || y == 0)
return x + y;
/*
如果其中一个结点为空,即只剩另下一棵树需要处理,就直接返回
因为空结点的ID为0,所以直接返回 x + y 即可。 如果两棵树都为空,这样也是没有问题的。
*/
if (Tree[x].Priority > Tree[y].Priority) {
Tree[x].Right = merge(Tree[x].Right, y);
pushup(x);
return x;
} else {
Tree[y].Left = merge(x, Tree[y].Left);
pushup(y);
return y;
}
}
各种修改&查询
插入
假设插入的值为\(key\),把树分裂按\(key-1\)分裂成两棵,在中间新建结点,合并。
void insert(T key) {
int x, y;
split(Root, key - 1, x, y);
Root = merge(merge(x, create(key)), y);
}
删除
假设删除的值为\(key\),把树分裂按\(key\)分裂成\(X,Z\),把\(X\)按\(key-1\)分裂成\(X,Y\)。这里\(Y\)上的结点的值都等于\(key\)。如果只删除一个结点,就把\(Y\)赋值为它的左右子树合并的结果,在合并\(X,Y,Z\)。如果删除所有,就直接合并\(X,Z\)。
void remove(T key) {
int x, y, z;
split(Root, key, x, z);
split(x, key - 1, x, y);
if (y) { // 如果删除所有,就直接去掉这个if语句块,并且下面的只合并x, z
y = merge(Tree[y].Left, Tree[y].Right);
}
Root = merge(merge(x, y), z);
}
查询指定值的排名
如果是在一个有序的序列中查询排名,我们可以二分查找这个序列,然后根据找到的元素的下标来确定排名,假设下标从\(1\)开始,那么排名就为该元素的下标\(i\)。那么,在它之前,也就有\(i-1\)个元素。由此,我们可以得到排名的一种定义:在有序序列中,一个元素的排名就是它前面的元素的个数\(+1\)。
在FHQ Treap上,我们就直接按\(key-1\)分裂树,查一下值小于等于\(key-1\)的树的大小,再\(+1\)即可。
int rank(T key) {
int x, y, ans;
split(Root, key - 1, x, y);
ans = Tree[x].Size + 1;
Root = merge(x, y);
return ans;
}
查询指定排名的值
写法1
从根节点开始,根据左子树的\(size+1\)确定往哪里走,分三种情况。
- \(size+1=rank\),找到答案
- \(size+1>rank\),在左子树
- \(size+1<rank\),在右子树
T at(int r) {
int root = Root;
while (true) {
if (Tree[Tree[root].Left].Size + 1 == r) {
break;
} else if (Tree[Tree[root].Left].Size + 1 > r) {
root = Tree[root].Left;
} else {
r -= Tree[Tree[root].Left].Size + 1;
root = Tree[root].Right;
}
}
return Tree[root].Key;
}
写法2
// 这里的split是按大小分裂
T at(int r) {
int x, y, z;
split(Root, r - 1, x, y);
split(y, 1, y, z);
T ans = Tree[y].Key;
Root = merge(merge(x, y), z);
return ans;
}
推荐大家用写法1,总的代码更少,速度更快。
查询前驱
前驱,即最大的小于被查询元素的元素
按\(key-1\)分裂树,在值小于等于\(key-1\)的树上一直向右下走,就是走到中序遍历的最后一个结点,合并后返回值即可。
T prev(T key) {
int x, y, root;
T ans;
split(Root, key - 1, x, y);
root = x;
while (Tree[root].Right) root = Tree[root].Right;
ans = Tree[root].Key;
Root = merge(x, y);
return ans;
}
查询后继
后继,即最小的大于被查询元素的元素
和查询前驱一样的。就是在另外一棵树上往左下走。
T next(T key) {
int x, y, root;
T ans;
split(Root, key, x, y);
root = y;
while (Tree[root].Left) root = Tree[root].Left;
ans = Tree[root].Key;
Root = merge(x, y);
return ans;
}
查询树的大小
直接返回根节点记录的大小。
int size() {
return Tree[Root].Size;
}
查询一个元素是否存在
把树分裂为三棵,中间那棵的值全部等于\(key\),再看看中间的树的大小是否不为\(0\),不为\(0\)则有这个元素。
bool find(T key) {
int x, y, z;
split(Root, key, x, z);
split(x, key - 1, x, y);
bool ans;
if (Tree[y].Size) ans = true;
else ans = false;
Root = merge(merge(x, y), z);
return ans;
}
垃圾回收优化
需要修改的函数:
// Stack[]即栈,用来存储结点,也可以使用std::stack<T>
void remove(T key) {
int x, y, z;
split(Root, key, x, z);
split(x, key - 1, x, y);
if (y) {
if(Top < (MaxSize >> 8) - 5) Stack[++Top] = y;
y = merge(Tree[y].Left, Tree[y].Right);
}
Root = merge(merge(x, y), z);
}
int create(T key) {
int root = Top ? Stack[Top--] : ++Total;
Tree[root].Key = key;
Tree[root].Size = 1;
Tree[root].Left = Tree[root].Right = 0;
Tree[root].Priority = rad();
return root;
}
完整实现
不贴代码了,如果想看指针版来GitHub。
例题
普通平衡树
平衡树板子题,直接复制GitHub的代码再加上头文件和main函数就可以\(AC\)了。(知道你们最喜欢\(AC\)了)
文艺平衡树
时间原因,码风有点不一样,就凑合这看吧。
我们可以给每个结点多维护一个信息——翻转标记。对于翻转的每个区间\([l,r]\),我们可以按大小分裂,实现按\(l-1\)分裂出\(X,Y\),再将\(Y\)按\(r-l+1\)分裂为\(Y,Z\)。给\(Y\)树大上翻转标记即可。再考虑标记下传,如果一个结点没有被翻转(被翻转偶数次也算没有翻转),就直接返回,否则去除当前结点的翻转标记,给子结点的翻转标记取反(或异或\(1\)),交换两个子结点。同时,在split函数和merge函数里添加标记下传代码。
实现细节如下:
void pushdown(int rt) {
if (tree[rt].rev == 0)
return;
swap(tree[rt].l, tree[rt].r);
tree[tree[rt].l].rev ^= 1;
tree[tree[rt].r].rev ^= 1;
tree[rt].rev = 0;
}
void split(int rt, int sze, int &x, int &y) {
if (rt == 0) {
x = y = 0;
return;
}
pushdown(rt);
if (tree[tree[rt].l].sze + 1 <= sze) {
x = rt;
split(tree[rt].r, sze - tree[tree[rt].l].sze - 1, tree[rt].r, y);
} else {
y = rt;
split(tree[rt].l, sze, x, tree[rt].l);
}
pushup(rt);
}
int merge(int x, int y) {
if (x == 0 || y == 0)
return x + y;
if (tree[x].pri > tree[y].pri) {
pushdown(x);
tree[x].r = merge(tree[x].r, y);
pushup(x);
return x;
} else {
pushdown(y);
tree[y].l = merge(x, tree[y].l);
pushup(y);
return y;
}
}
void reverse(int l, int r) {
int x, y, z;
split(root, l - 1, x, y);
split(y, r - l + 1, y, z);
tree[y].rev ^= 1;
root = merge(merge(x, y), z);
}
最后按题目要求输出即可。
郁闷的出纳员
本来这到题用Treap是需要打标记的,但是有了FHQ Treap就是个简单题了。如果给员工减工资,就先遍历一遍,然后对树split,把小于\(min\)的那棵树直接扔掉,并把它的大小加入答案。其他都没有什么问题了。
如果你也是自己写随机函数,一定要记得初始化种子,否则你会像我之前一样
random()总是返回\(0\),最后卡成了链,T飞了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号