python爬虫知识点总结(一)库的安装
环境要求:
1、编程语言版本python3;
2、系统:win10;
3、浏览器:Chrome68.0.3440.75;(如果不是最新版有可能影响到程序执行)
4、chromedriver2.41
注意点:pip3 install 命令必须在管理员权限下才能有效下载!
一、安装python3
不是本文重点,初学者,建议上百度搜索,提供几个思路:
1、官网:https://www.python.org/
IDE:pycharm
2、anaconda安装后自带python
等等。
二、配置环境变量
需要配置的路径有两个
1、python.exe所在路径(python所在)
2、Script文件夹下的路径(pip所在)
三、爬虫常用库的安装
(1)requests库
管理员运行cmd。
输入命令:pip3 install requests
测试:在cmd下运行一下代码实例测试:
import requests requests.get('http://www.baidu.com')
结果如图:

(2)selenium库
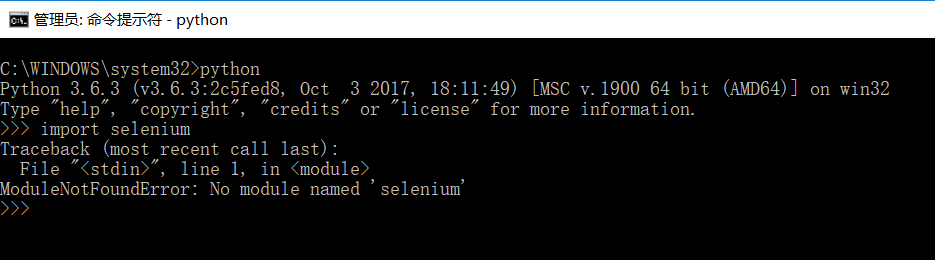
先检查selenium在本地有没有。
和上面的图操作一样,进到python->输入import selenium
如果没安装,会报错,如下图:
在cmd下输入命令:pip3 install selenium
安装结果如下图:

尝试运行代码实例:
import selenium from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.page_source
会报错:

因为本地没有Chromdriver,需要下载,下载最新版就可以了
http://npm.taobao.org/mirrors/chromedriver/
将chromedriver.exe放到python.exe文件夹下,或者Scripts文件夹下(本质是环境变量配置,方便python找到)
在cmd下输入命令:chromedriver
再次运行代码实例,如果出错如下,那就看我的这篇博客:
https://www.cnblogs.com/cthon/p/9390095.html
https://www.cnblogs.com/cthon/p/9390998.html
其本质是,chrome版本和webdriver不一致,一定记住下载最新版本的chrome

正确的执行结果应该是:
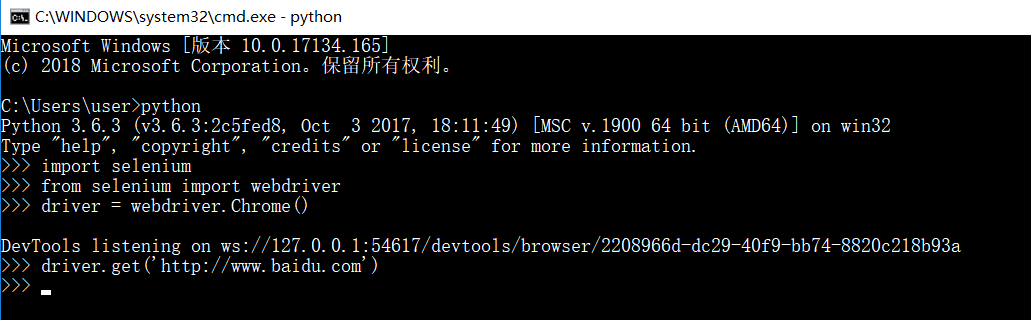
执行成功会自动弹出Google浏览器并进入百度界面

(3)phantomjs(无界面浏览器)
下载链接:http://phantomjs.org/download.html
解压后,配置环境变量phantomjs

检查是否配置成功
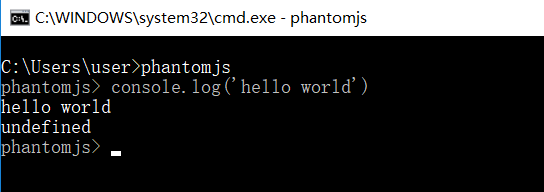
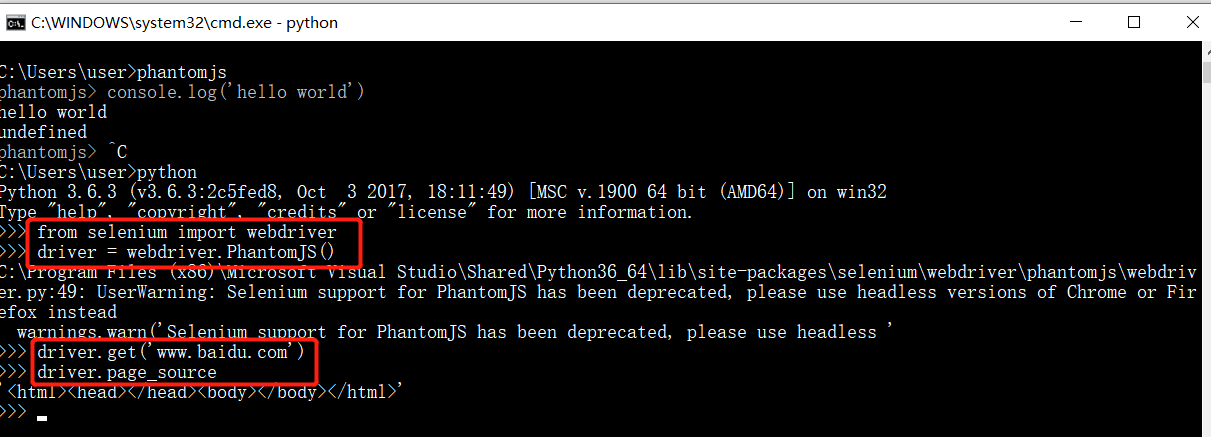
代码实例测试:
from selenium import webdriver driver = webdriver.PhantomJS() driver.get("http://www.baidu.com") driver.page_source
(4)lxml库
在cmd下,输入命令:pip3 install lxml
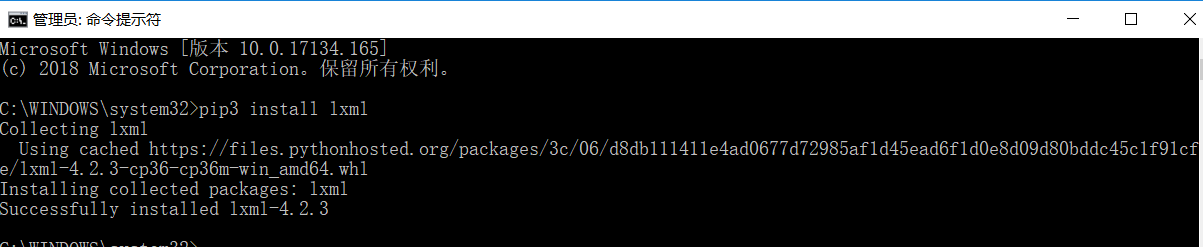
(5)beautifulsoup库
在cmd下,输入命令:pip3 install beautifulsoup4
有可能会爆出找不到该版本的错误信息,那就通过下载链接:https://www.crummy.com/software/BeautifulSoup/bs4/download/

运行代码示例:
from bs4 import BeautifulSoup soup = BeautifulSoup('<html></html>','lxml')

(6)pyquery库(和beautifulsoup一样是网页解析库,个人觉得比较方便)
官方学习:https://pythonhosted.org/pyquery/
在cmd下,输入命令:pip3 install pyquery
运行代码实例:
from pyquery import PyQuery as pq doc = pq('<html></html>') doc = pq('<html>hello</html>') result = doc('html').text() result
(7)pymysql库(操作mysql)
在cmd下,输入命令:pip3 install pymysql
运行代码实例:
import pymysql conn = pymysql.connect(host='localhost',user='root',password='root',port=3306,db='mysql') cursor = conn.cursor() cursor.execute('select * from db') cursor.fetchone() cursor.execute('select * from myuser')
对比一下,mysql的数据

(8)pymongo库(操作mongodb)--key-value型,数据存储很方便,不需要建表,可以动态增加一些键名
在cmd下,输入命令:pip3 install pymongo

输入代码实例:
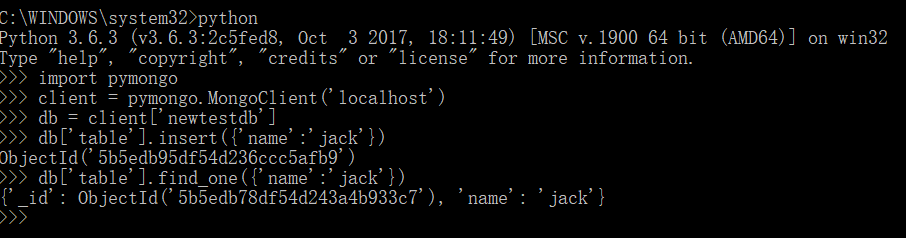
import pymongo client = pymongo.MongoClient('localhost') db = client['newtestdb'] db['table'].insert({'name':'jack'})
db['table'].find_one({'name':'jack'})
(9)redis库(操作redis)--key-value型,用在分布式爬虫,维护爬取队列,效果比较理想
在cmd下:输入命令:pip3 install redis

运行代码实例:
import redis r = redis.Redis('localhost',6379) r.set('name','jack') r.get('name')

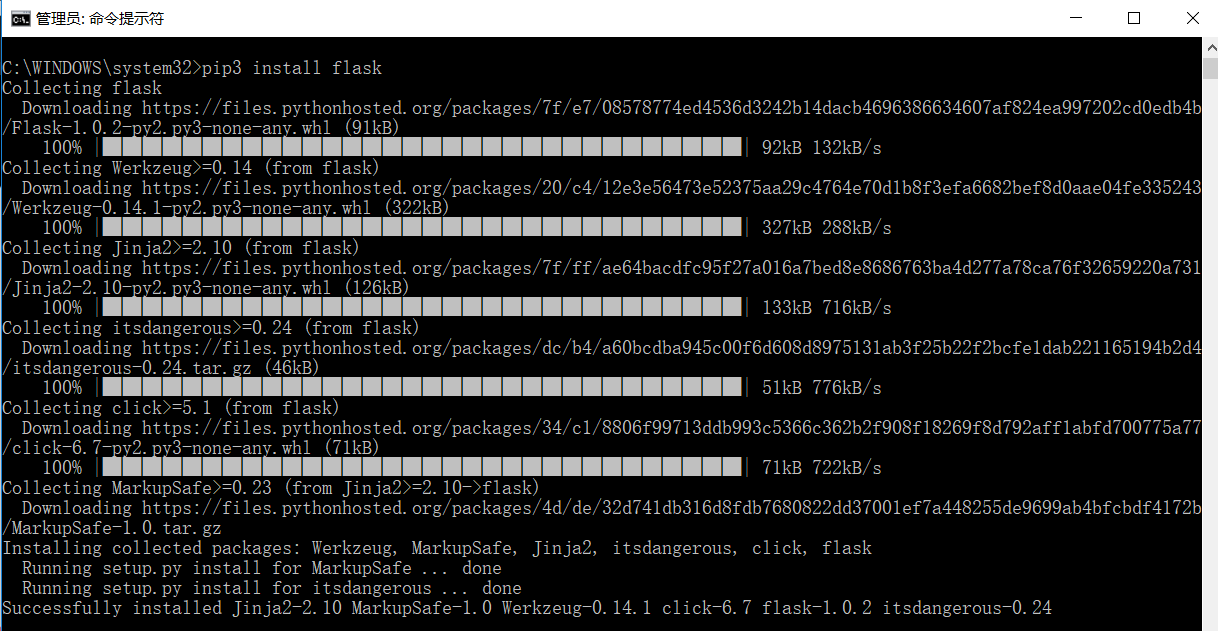
(10)flask库(web库,在做一些代理的设置时需要用到,用来设置一些代理的获取和存储)
官方文档:http://www.pythondoc.com/flask/index.html
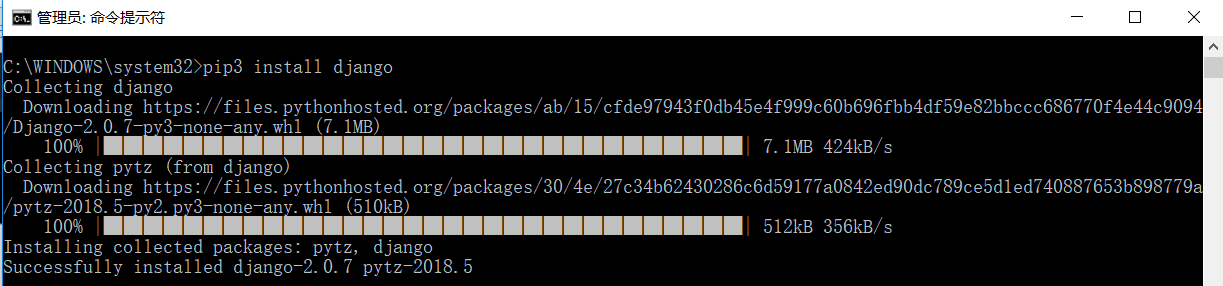
(11)django库(web服务器框架,提供了服务器后台管理,模板引擎,接口,路由,用于分布式爬虫的维护)
官方文档:https://docs.djangoproject.com/en/2.0/
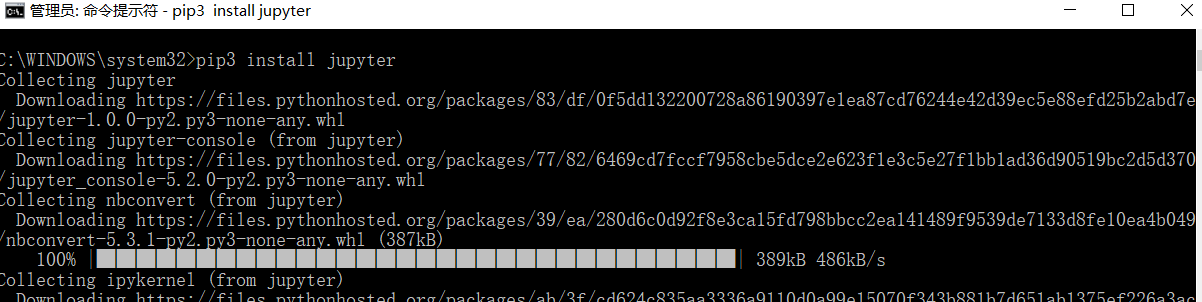
(12)jupyter库(相当于notebook,用来编写代码记录)
官方文档:https://jupyter.org/documentation
在cmd下,输入命令:pip3 install jupyter
内容很多,我就不全部截图了,正确运行就可以了。
jupyter的启动方法有两个:
1、在命令行输入:jupyter notebook
会在浏览器中弹出一个网页notebook 代码编辑页
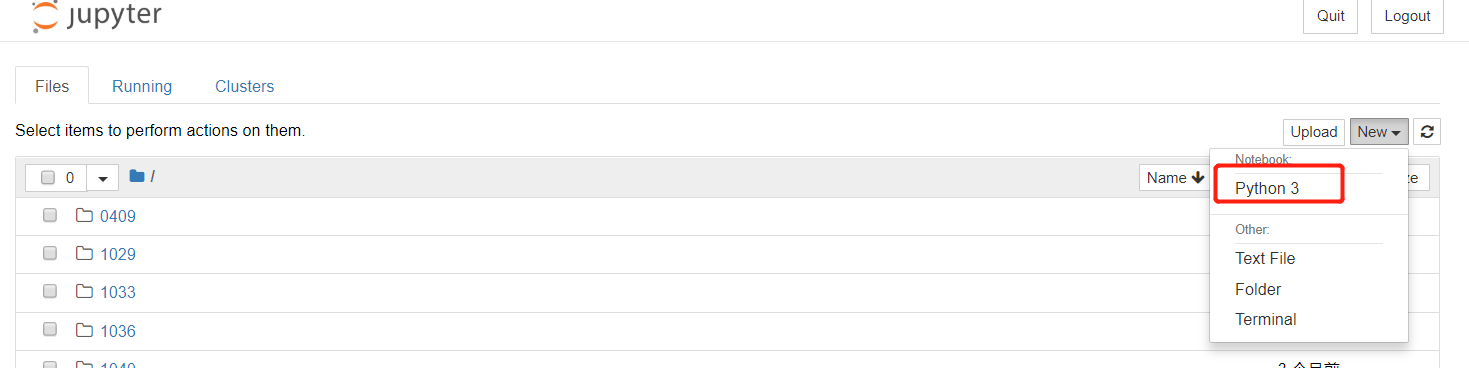
按照以下步骤可以进行代码编辑,
首先:新建一个python3文件
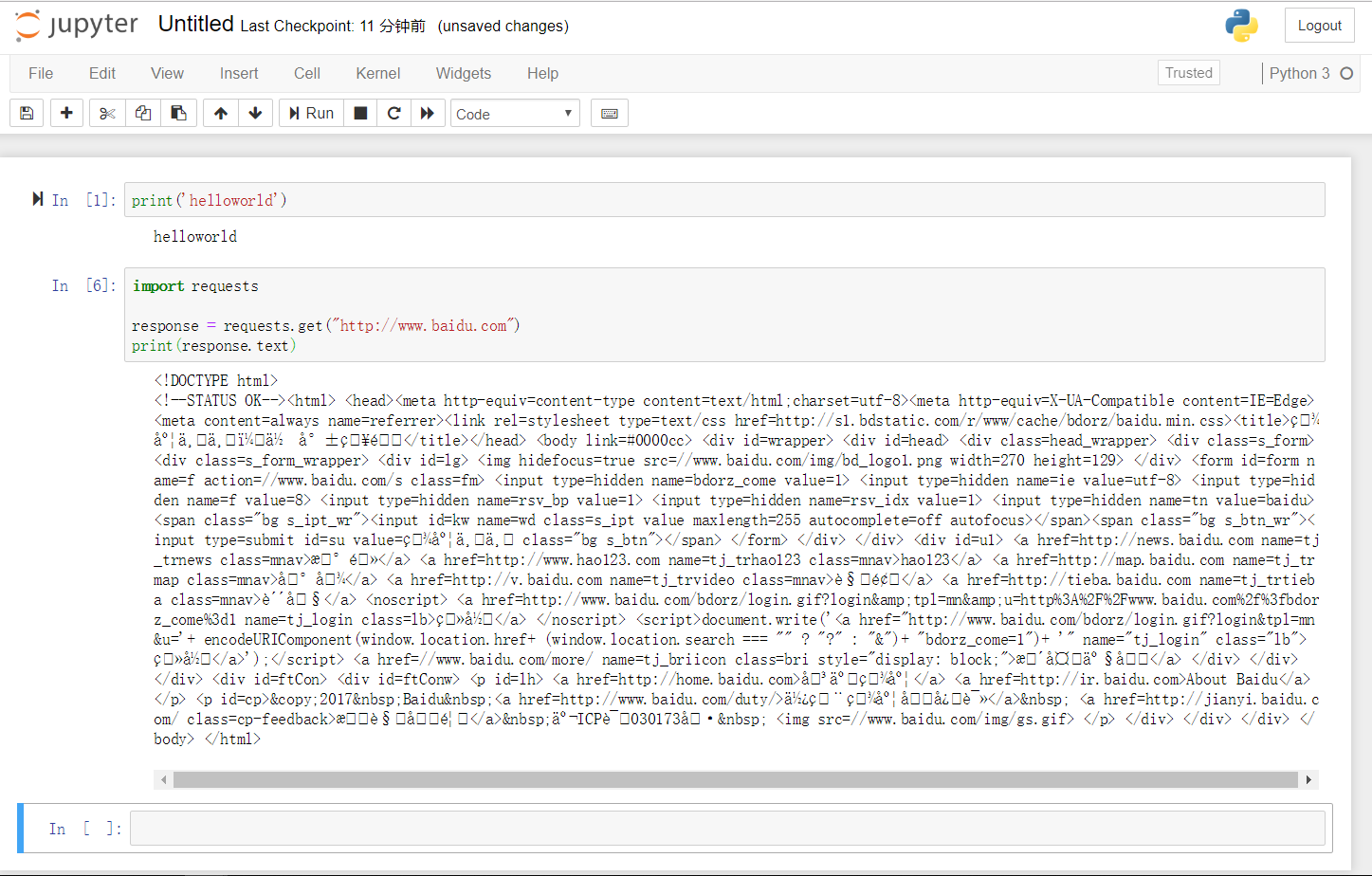
编写代码:
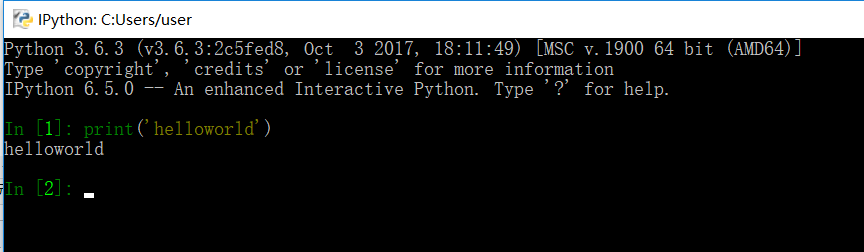
2、在命令行输入:ipython
这种方式会在命令行进行编写
Linux和Mac下安装
直接输入命令:
pip3 install selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter
验证方法和windows下一样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号