论文笔记:Scaling Memcache at Facebook
论文笔记:Scaling Memcache at Facebook
论文介绍了Facebook如何使用memcache,以及相关魔改和维护memcache集群。
欢迎访问我的博客
背景
facebook使用一致性哈希来构建memcahce集群。
We provision hundreds of memcached servers in a cluster to reduce load on databases and other services.
Items are distributed across the memcached servers through consistent hashing [22].
Thus web servers have to routinely communicate with many memcached servers to satisfy a user request
使用
cache aside模式
facebook根据他们的场景,也就是读多写少使用了cache aside模式。原文叫demand-filled look-aside cache。具体使用方式如下图。
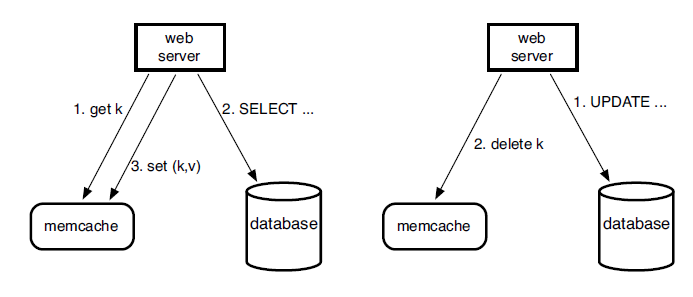
facebook 使用delete而不是update缓存的原因是因为delete是幂等的,而update不是(we choose to delete cached data instead of updating it because deletes are idempotent).如果直接更新可能出现先更新的后放入缓存。
在facebook也是用memcache作为大数据平台计算的中间结果存储平台,用来存放一些中间结果
魔改
魔改背景
一个web请求会请求平均521个独立的缓存项.(A single user web request can often result in hundreds of individual memcache get requests. For example, loading one of our popular pages results in an average of 521 distinct items fetched from memcache)
魔改目的
魔改的目的是为了降低延迟,降低负载。
魔改方法
延迟与负载:1.网络延迟 2.由于cache miss带来的延迟和后端的负载。解决方案如下:
- 代码批量化访问缓存,减少来回的网络开销
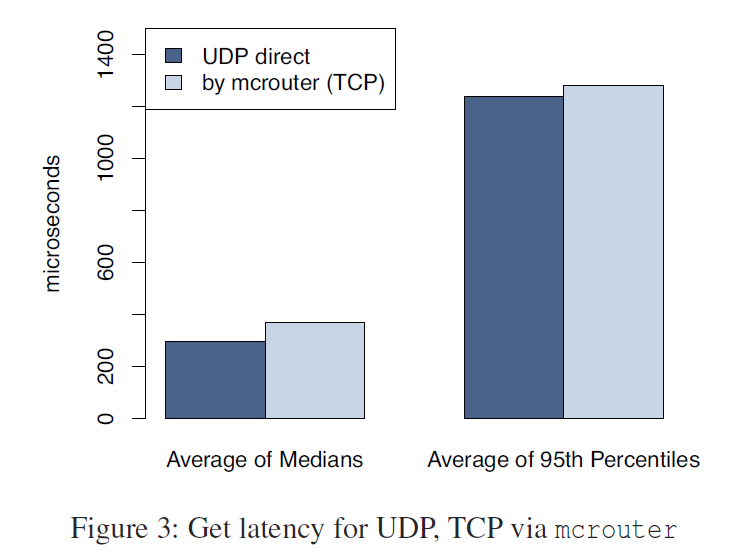
- 对于网络延迟的降低,facebook对于GET使用UDP传输,SET和DELETE使用TCP传输。因为UDP是无连接的,可以降低TCP维护链接的开销。使用UDP客户端自己记录请求序号,丢包和乱序被视为客户端错误,在实际生产环境中,有0.25%的get请求被扔掉。其中的80%是因为回包延迟,其他的是因为乱序。对于上面的错误,客户端直接认为是cache miss。直接取后端,但是不会放入缓存是为了避免额外的网络开销
效果如下图:
![]()
- 使用类似TCP拥塞控制的方法来防止缓存集群负载过高。客户端维护一个滑动窗口,当服务端正常响应,就加大窗口,当服务端没响应或者超时就减小窗口。
后端负载降低
1.引入“租约Leases”,租约用来解决两个方面的问题 1. 过期的设置 2.惊群效应(stale sets and thundering herds)。
- 过期的设置主要来源于放入缓存的顺序错乱(后来先到)。
- 惊群效应发生在某个key被频繁的读写。由于写是invalid cache,所以大量读请求就会无法命中缓存,导致进入了后端的数据库。
- 租约就是一个对应于请求的key的64bit的token。(The lease is a 64-bit token bound to the specific key the client originally requested)。当set cache的时候,客户端需要把这个key带上一起给到缓存服务器,当服务端发现token不匹配的时候,就说明这是一个过期的写请求。
- 租约同时可以降低惊群效应。缓存服务器控制发token的频率,默认是10秒一次,缓存服务器发过一次token后,后续再来的请求就直接等一会(等前面那个拿到token的返回之后,缓存就有数据了)
Without leases, all of the cache misses resulted in a peak database query rate of 17K/s. With leases, the peak database query rate was 1.3K/s
2.使用过期值
- 通过返回slightly out-of-date data,当一个key被删除的时候,在真正flush之前,会被放入一个特殊的数据结构中。get请求可以返回一个租约或者这个被标记为过期的值。
3.处理失败,这里的失败有两种
- 有一小部分机器由于网络原因无法访问(facebook依赖一个自动化的组件去发现这些机器,但需要时间 few minutes,在这一段时间内可能会带来一些连锁失败)
解决办法:有一个叫gutter的小池子,大概是cache集群的1%大小,用来替代那些无法访问的机器。当client无法收到缓存服务器的响应,他们就去访问gutter池子里面的机器。注意这根一般一致性哈希的玩法不一样,原因是有可能有些key非常的热,如果把它hash到下一台机器,就会增加那台机器的负载,导致又爆炸。把它导到空闲的gutter机器上就可以避免这个问题。一旦出现一台缓存机器无法访问,gutter通常能在4分钟内,缓存命中率能超过35%,有时能达到50% - 集群中的大部分机器都无法访问
解决办法:切换流量到其他可用region
维护memcache集群
待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号