RPC项目
第一部分 技术亮点
- 注册中心 :注册中心首先是要有的,推荐使用 Zookeeper。注册中心负责服务地址的注册与查找,相当于目录服务。服务端启动的时候将服务名称及其对应的地址(ip+port)注册到注册中心,服务消费端根据服务名称找到对应的服务地址。有了服务地址之后,服务消费端就可以通过网络请求服务端了。
- 网络传输 :既然要调用远程的方法就要发请求,请求中至少要包含你调用的类名、方法名以及相关参数吧!推荐基于 NIO 的 Netty 框架。
- 序列化 :既然涉及到网络传输就一定涉及到序列化,你不可能直接使用 JDK 自带的序列化吧!JDK 自带的序列化效率低并且有安全漏洞。 所以,你还要考虑使用哪种序列化协议,比较常用的有 hession2、kyro、protostuff。
- 动态代理 : 另外,动态代理也是需要的。因为 RPC 的主要目的就是让我们调用远程方法像调用本地方法一样简单,使用动态代理可以屏蔽远程方法调用的细节比如网络传输。也就是说当你调用远程方法的时候,实际会通过代理对象来传输网络请求,不然的话,怎么可能直接就调用到远程方法呢?
- 负载均衡 :负载均衡也是需要的。为啥?举个例子我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡的这四个字就能明显感受到它的意义。
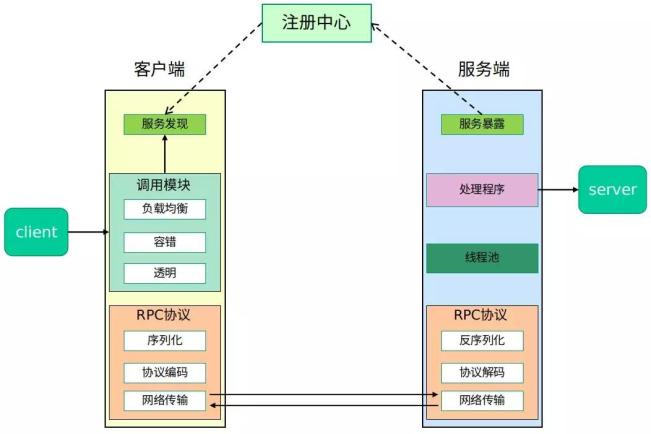
第二部分 技术原理和实现
一、网络传输:Netty
-
概念:一款基于NIO(Nonblocking I/O,非阻塞IO)开发的网络通信框架,对比于BIO(Blocking I/O,阻塞IO),他的并发性能得到了很大提高
-
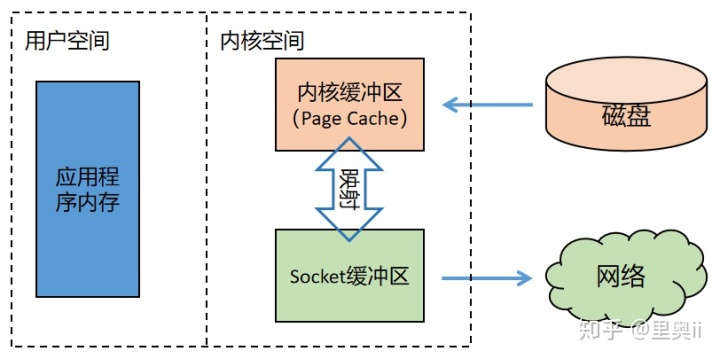
零拷贝:
- 概念数据如果需要从IO读取到堆内存,中间需要经过Socket缓冲区,也就是说一个数据会被拷贝两次才能到达他的的终点,如果数据量大,就会造成不必要的资源浪费。Netty中,当需要接收数据的时候,会在堆内存之外开辟一块内存,数据就直接从IO读到了那块内存中去,在netty里面通过ByteBuf可以直接对这些数据进行直接操作,从而加快了传输速度。
- 实现方式
-
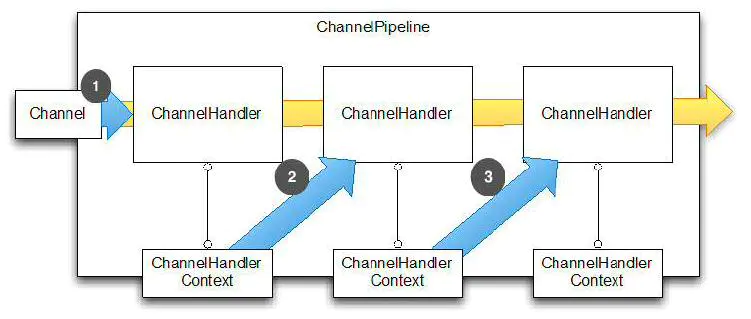
核心组件
-
Channel:数据传输流,Channel 接口是 Netty 对网络操作抽象类,表示一个连接,可以理解为每一个请求,就是一个Channel。
- ChannelHandler,核心处理业务就在这里,用于处理业务请求。ChannelHandler 是消息的具体处理器。负责处理读写操作、客户端连接等事情。
- ChannelHandlerContext,用于传输业务数据。
- ChannelPipeline,用于保存处理过程需要用到的ChannelHandler和ChannelHandlerContext。可以在 ChannelPipeline 上通过 addLast() 方法添加一个或者多个ChannelHandler ,因为一个数据或者事件可能会被多个 Handler 处理。当一个 ChannelHandler 处理完之后就将数据交给下一个 ChannelHandler 。
- ChannelFuture(操作执行结果):Netty 是异步非阻塞的,所有的 I/O 操作都为异步的。因此,我们不能立刻得到操作是否执行成功,但是,你可以通过 ChannelFuture 接口的 addListener() 方法注册一个 ChannelFutureListener,当操作执行成功或者失败时,监听就会自动触发返回结果。
-
ByteBuf:最大特点就是使用方便,网络通信最终都是通过字节流进行传输的。 ByteBuf 就是 Netty 提供的一个字节容器,其内部是一个字节数组。 当我们通过 Netty 传输数据的时候,就是通过 ByteBuf 进行的。
- Heap Buffer 堆缓冲区:堆缓冲区是ByteBuf最常用的模式,他将数据存储在堆空间。
- Direct Buffer 直接缓冲区:直接缓冲区是ByteBuf的另外一种常用模式,他的内存分配都不发生在堆,jdk1.4引入的nio的ByteBuffer类允许jvm通过本地方法调用分配内存,这样做有两个好处:
- 通过免去中间交换的内存拷贝, 提升IO处理速度; 直接缓冲区的内容可以驻留在垃圾回收扫描的堆区以外。
- DirectBuffer 在 -XX:MaxDirectMemorySize=xxM大小限制下, 使用 Heap 之外的内存, GC对此”无能为力”,也就意味着规避了在高负载下频繁的GC过程对应用线程的中断影响.
- Composite Buffer 复合缓冲区:复合缓冲区相当于多个不同ByteBuf的视图,这是netty提供的,jdk不提供这样的功能。

-
Codec:Netty中的编码/解码器,能完成字节与pojo、pojo与pojo的相互转换,从而达到自定义协议的目的。在Netty里面最有名的就是HttpRequestDecoder和HttpResponseEncoder了。
-
Bootstrap 和 ServerBootstrap(启动引导类):辅助类,提供了链式配置方法,方便了Channel的引导和启动。
-
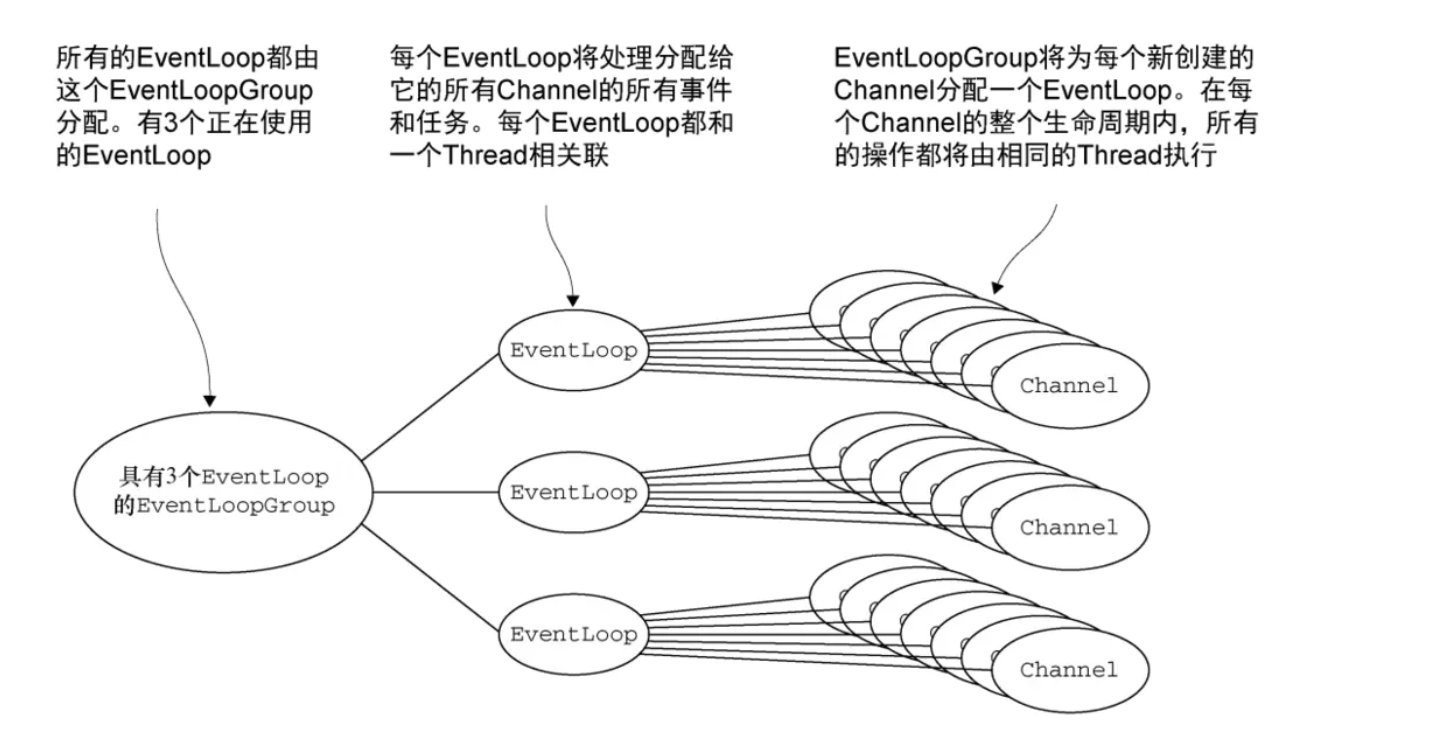
EventLoop(事件循环)
-
主要作用:责监听网络事件并调用事件处理器进行相关 I/O 操作(读写)的处理。
-
Channel 和 EventLoop 的关系:Channel 为 Netty 网络操作(读写等操作)抽象类,EventLoop 负责处理注册到其上的Channel 的 I/O 操作,两者配合进行 I/O 操作。
-
EventloopGroup 和 EventLoop 的关系:EventLoopGroup 包含多个 EventLoop(每一个 EventLoop 通常内部包含一个线程),它管理着所有的 EventLoop 的生命周期。
-
TaskQueue:在 Netty 的每一个 NioEventLoop 中都有一个 TaskQueue,设计它的目的是在任务提交的速度大于线程的处理速度的时候起到缓冲作用。或者用于异步地处理 Selector 监听到的 IO 事件。
-
-
Selector:选择器(Selector)是实现 IO 多路复用的关键,多个 Channel 注册到某个 Selector 上,当 Channel 上有事件发生时,Selector 就会取得事件然后调用线程去处理事件。Netty 的 IO 线程 NioEventLoop 聚合了 Selector
-
-
Netty特点
- 并发高:在NIO中,当一个Socket建立好之后,Thread并不会阻塞去接受这个Socket,而是将这个请求交给Selector,Selector会不断的去遍历所有的Socket,一旦有一个Socket建立完成,他会通知Thread,然后Thread处理完数据再返回给客户端——这个过程是不阻塞的,这样就能让一个Thread处理更多的请求了。
- 传输快:零拷贝
- 封装好:
-
Reactor 线程模型
-
概念:Reactor 是一种经典的线程模型,Reactor 模式基于事件驱动,采用多路复用将事件分发给相应的 Handler 处理,特别适合处理海量的 I/O 事件。
-
单Reactor单线程模型:这种模型在Reactor中处理事件,并分发事件,如果是连接事件交给acceptor处理,如果是读写事件和业务处理就交给handler处理,但始终只有一个线程执行所有的事情。不足:(1)仅用一个线程处理请求,对于多核资源机器来说是有点浪费的;(2)当处理读写任务的线程负载过高后,处理速度下降,事件会堆积,严重的会超时,可能导致客户端重新发送请求,性能越来越差;(3)单线程也会有可靠性的问题
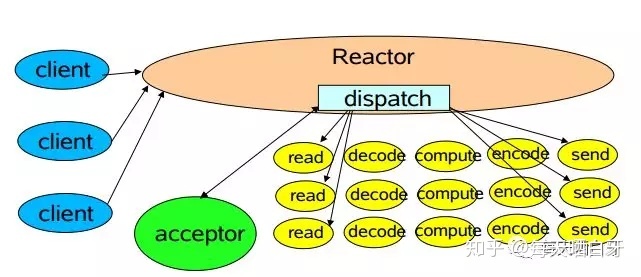
-
单Reactor多线程模型:把业务处理从之前的单一线程脱离出来,换成线程池处理,也就是Reactor线程只处理连接事件和读写事件,业务处理交给线程池处理,充分利用多核机器的资源、提高性能并且增加可靠性。不足:Reactor线程承担所有的事件,例如监听和响应,高并发场景下单线程存在性能问题。
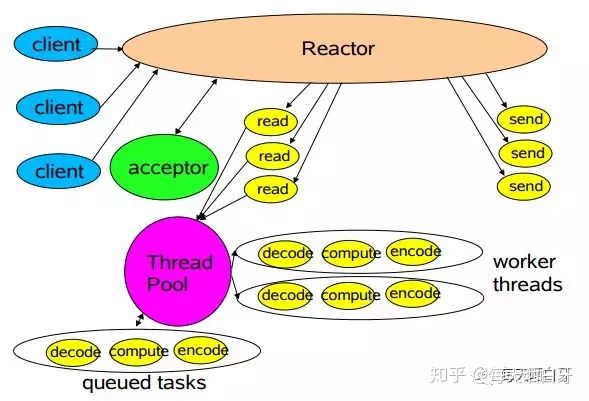
-
主从多线程 Reactor:把Reactor线程拆分了mainReactor和subReactor两个部分,mainReactor只处理连接事件,读写事件交给subReactor来处理。业务逻辑还是由线程池来处理。
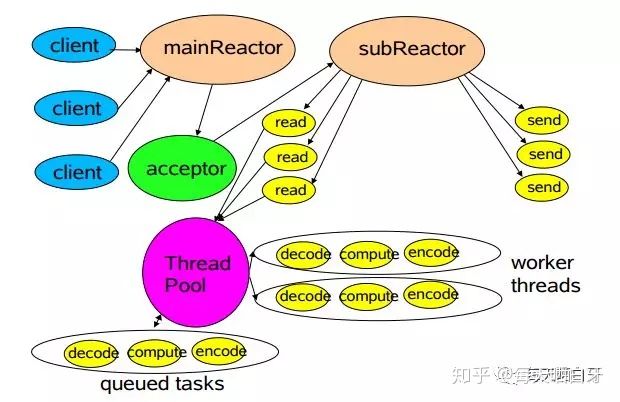
-
Netty 线程模型:
- 采用“服务端监听线程”和“IO线程”分离的方式,与多线程Reactor模型类似。抽象出NioEventLoop来表示一个不断循环执行处理任务的线程,每个NioEventLoop有一个selector,用于监听绑定在其上的socket链路。
- Netty 通过 Reactor 模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss 线程池和 work 线程池,其中boss 线程池**的线程负责处理请求的 accept 事件,当接收到 accept 事件的请求时,把对应的 socket 封装到一个 NioSocketChannel 中,并交给 **work线程池,其中 work 线程池负责请求的 read 和 write 事件,由对应的 Handler 处理。
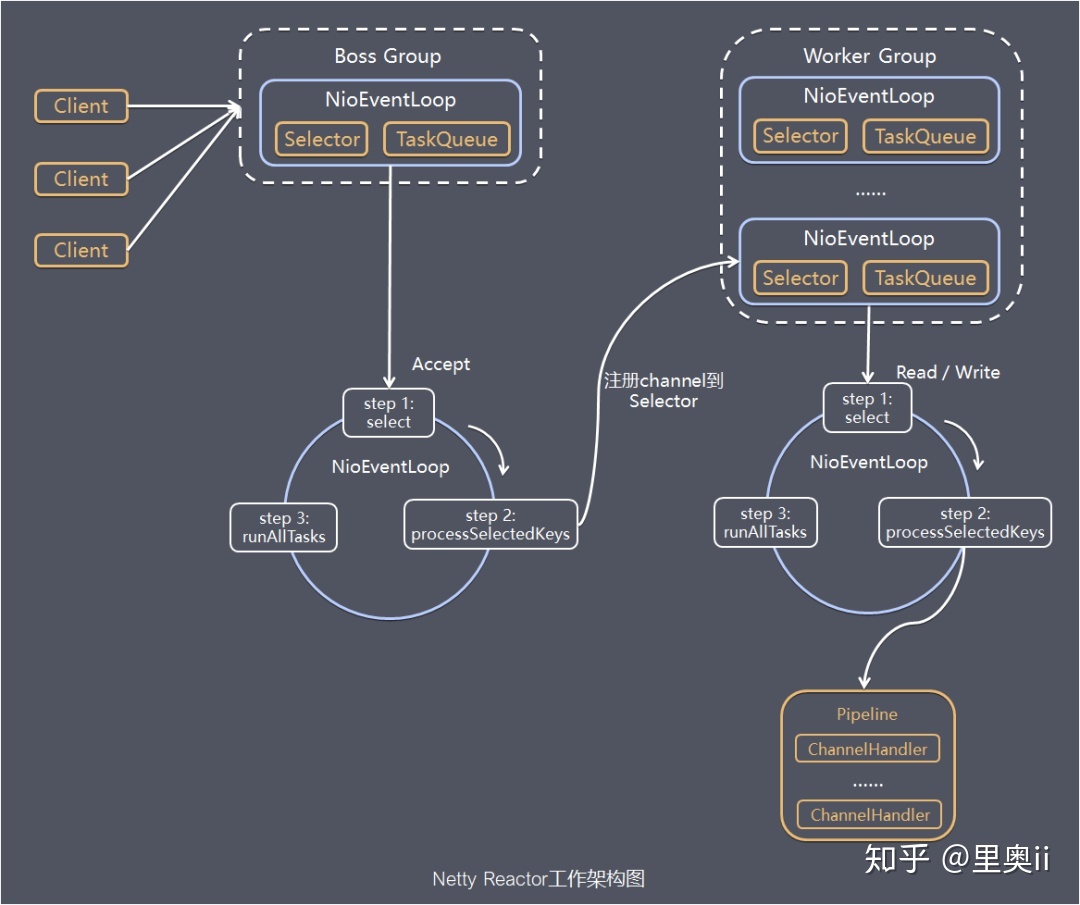
-
-
Netty 服务端和客户端的启动过程
- 服务端:
- 创建了两个 NioEventLoopGroup 对象实例:bossGroup 和 workerGroup。
- 创建了一个服务端启动引导/辅助类: ServerBootstrap,这个类将引导我们进行服务端的启动工作。
- 通过 .group() 方法给引导类 ServerBootstrap 配置两大线程组,确定了线程模型。
- 通过channel()方法给引导类 ServerBootstrap指定了 IO 模型为NIO
- .通过 .childHandler()给引导类创建一个ChannelInitializer ,然后指定了服务端消息的业务处理逻辑 HelloServerHandler 对象
- 调用 ServerBootstrap 类的 bind()方法绑定端口
- 客户端
- 创建一个 NioEventLoopGroup 对象实例
- 创建客户端启动的引导类是 Bootstrap
- 通过 .group() 方法给引导类 Bootstrap 配置一个线程组
- 通过channel()方法给引导类 Bootstrap指定了 IO 模型为NIO
- 通过 .childHandler()给引导类创建一个ChannelInitializer ,然后指定了客户端消息的业务处理逻辑 HelloClientHandler 对象
- 调用 Bootstrap 类的 connect()方法进行连接
- 服务端:
-
Netty解决TCP 粘包/拆包:
- 使用 Netty 自带的解码器
- LineBasedFrameDecoder : 发送端发送数据包的时候,每个数据包之间以换行符作为分隔,LineBasedFrameDecoder 的工作原理是它依次遍历 ByteBuf 中的可读字节,判断是否有换行符,然后进行相应的截取。
- DelimiterBasedFrameDecoder : 可以自定义分隔符解码器,LineBasedFrameDecoder 实际上是一种特殊的 DelimiterBasedFrameDecoder 解码器。
- FixedLengthFrameDecoder: 固定长度解码器,它能够按照指定的长度对消息进行相应的拆包。
- LengthFieldBasedFrameDecoder:
- 自定义序列化编解码器
- 使用 Netty 自带的解码器
-
Netty 长连接、心跳机制
- 心跳机制:在 TCP 保持长连接的过程中,可能会出现断网等网络异常出现,异常发生的时候, client 与 server 之间如果没有交互的话,它们是无法发现对方已经掉线的。为了解决这个问题, 需要引入 心跳机制 。
- 心跳机制原理:在 client 与 server 之间在一定时间内没有数据交互时, 即处于 idle 状态时, 客户端或服务器就会发送一个特殊的数据包给对方, 当接收方收到这个数据报文后, 也立即发送一个特殊的数据报文, 回应发送方, 此即一个 PING-PONG 交互。所以, 当某一端收到心跳消息后, 就知道了对方仍然在线, 这就确保 TCP 连接的有效性。
-
使用的设计模式(未完成)
- 单例模式(Singleton):保证独一无二。MqttEncoder
- 策略模式(Strategy):用户选择、结果统一。DefaultEventExecutorChooserFactory.newChooser()
- 装饰器模式(Decorator):包装,同宗同源。wrappedByteBuf、UnreleasableByteBuf、SimpleLeakAwareByteBuf
- 观察者模式(Observer):任务完成时通知。channel.writeAndFlush()
- 迭代器模式(Iterator):遍历元素。CompositeByteBuf
- 责任链模式(Chain):一条链上处理各自任务。Pipeline、AbstractChannelHandlerContext
- 工厂模式(Factory):只对结果负责,封装创建过程。ReflectiveChannelFactory
-
NioEventLoopGroup源码分析
-
参考连接:
- https://blog.csdn.net/qq_24313635/article/details/80989450?utm_medium=distribute.pc_feed_404.none-task-blog-2defaultBlogCommendFromBaiduRate-2.pc_404_mixedpudn&depth_1-utm_source=distribute.pc_feed_404.none-task-blog-2defaultBlogCommendFromBaiduRate-2.pc_404_mixedpud
- https://www.cnblogs.com/xiaojiesir/p/15579577.html
- https://gitee.com/souyunku/DevBooks/blob/master/docs/Netty/Netty最新2021年面试题附答案解析,大汇总.md
- https://blog.csdn.net/qq36846776/article/details/110263106
二、注册中心:
Nacos(微服务)
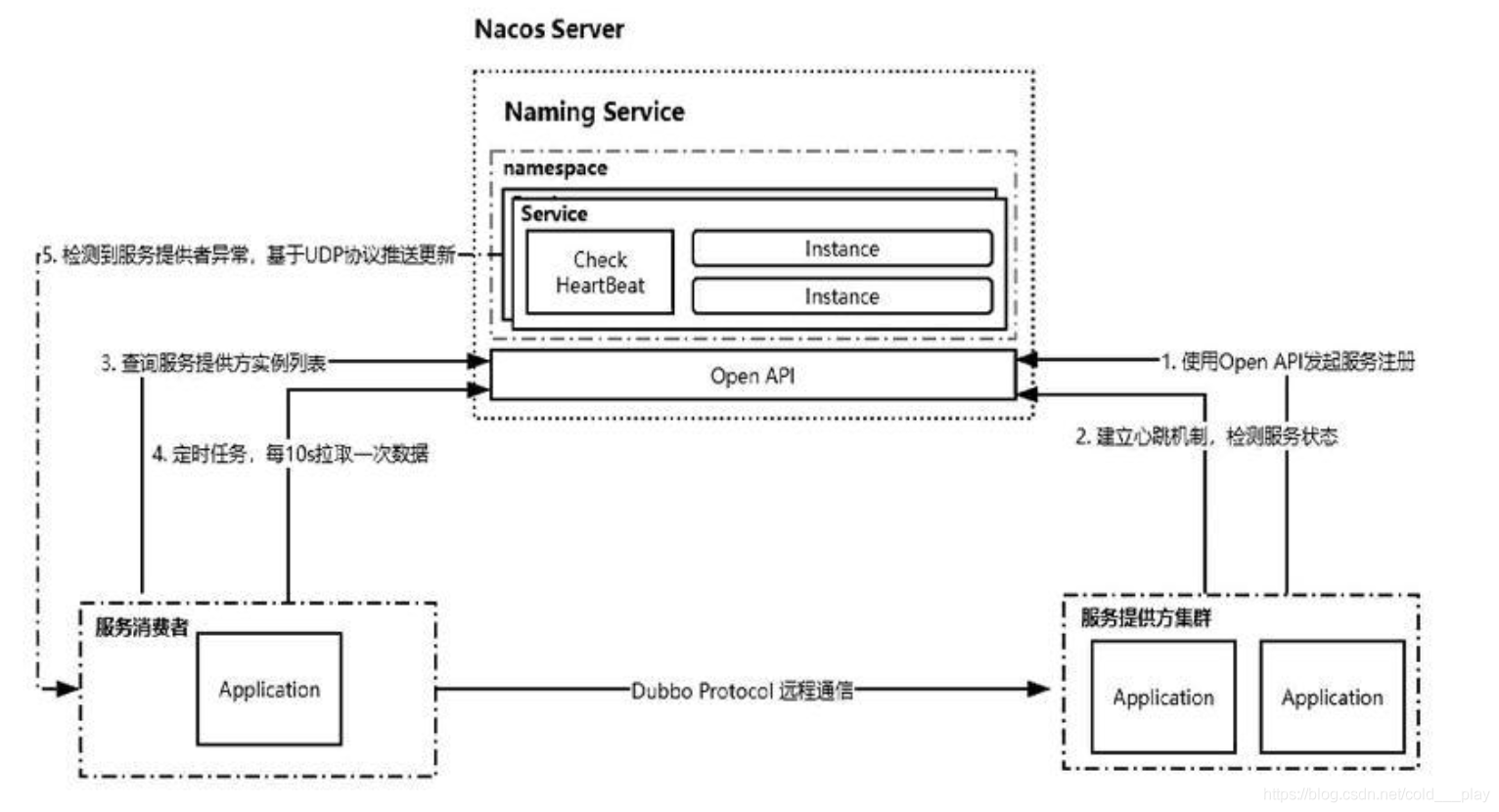
-
组件:
- Provider APP:服务提供者
- Consumer APP:服务消费者
- Name Server:通过VIP(Virtual IP)或DNS的方式实现Nacos高可用集群的服务路由
- Nacos Server:Nacos服务提供者,里面包含的Open API是功能访问入口,Conig Service、Naming Service 是Nacos提供的配置服务、命名服务模块Consitency Protocol是一致性协议,用来实现Nacos集群节点的数据同步,这里使用的是Raft算法(Etcd、Redis哨兵选举)
- Nacos Console:控制台
-
注册中心:
- Nacos注册中心分为Server与Client,Nacos提供SDK和openApi,如果没有SDK也可以根据openApi手动写服务注册与发现和配置拉取的逻辑。
- Server采用Java编写,基于Spring Boot框架,为Client提供注册发现服务与配置服务。
- Client支持包含了目前已知的Nacos多语言客户端及Spring生态的相关客户端。Client与微服务嵌套在一起。
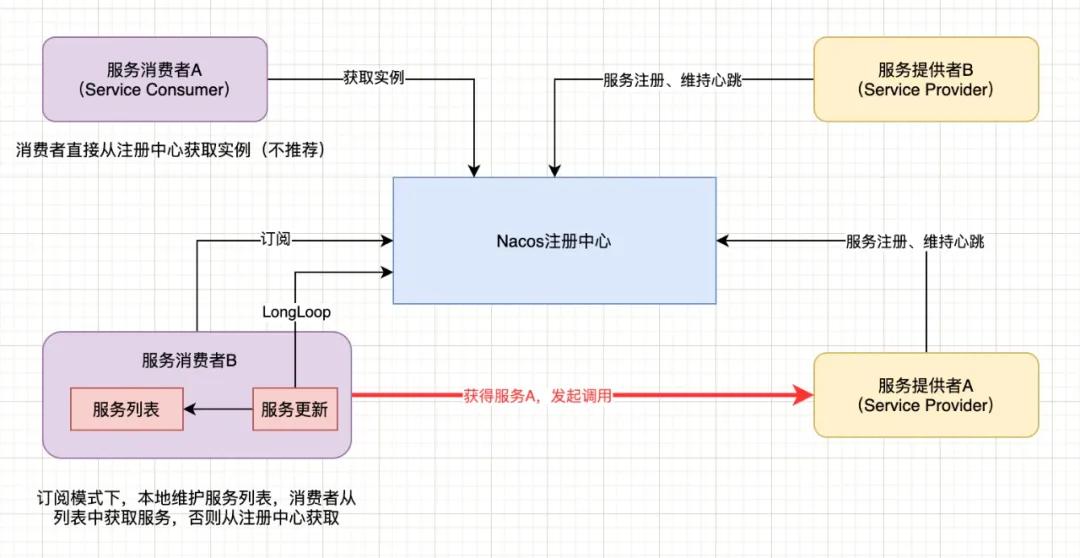
-
核心功能:
- 服务注册: Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。Nacos Server接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
- 服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一-次心跳。
- 服务同步: Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。
- 服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给Nacos Server,获取上面注册的服务清单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存
- 服务健康检查: Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它的healthy属性置为false(客户端服务发现时不会发现),如果某个实例超过30秒没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册)
-
Nacos数据模型:服务注册表结构为Map,数据模型的Key由三元组唯一确定,Namespace默认是空串,公共命名空间(public),分组默认是DEFAULT_GROUP。
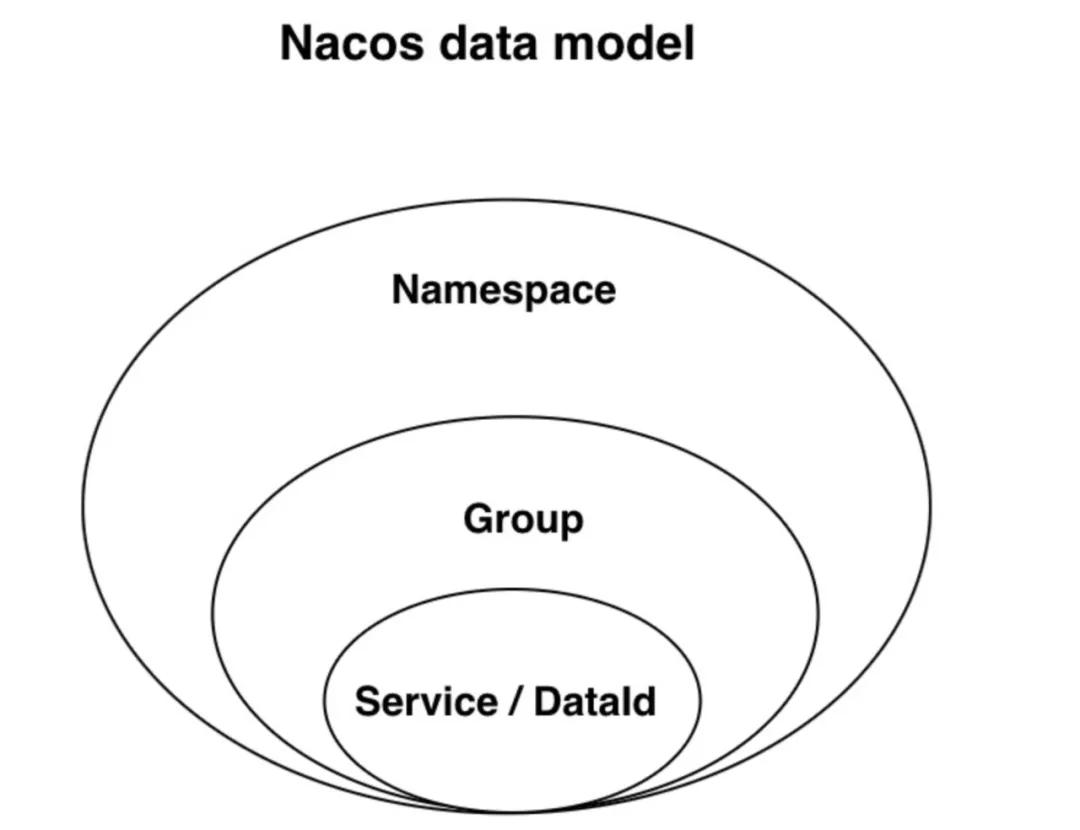
-
实现原理:
-
源码分析:
-
参考链接:
Zookeeper
-
概念:Zookeeper 是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等。
-
角色:
- Leader:
- 一个 Zookeeper 集群同一时间只会有一个实际工作的 Leader,它会发起并维护与各 Follwer及 Observer 间的心跳。
- 所有的写操作必须要通过 Leader 完成再由 Leader 将写操作广播给其它服务器。只要有超过半数节点(不包括 observeer 节点)写入成功,该写请求就会被提交
- Follower:
- 一个 Zookeeper 集群可能同时存在多个 Follower,它会响应 Leader 的心跳,
- Follower 可直接处理并返回客户端的读请求,同时会将写请求转发给 Leader 处理,
- 并且负责在 Leader 处理写请求时对请求进行投票。
- Observer:Zookeeper 需保证高可用和强一致性,为了支持更多的客户端,需要增加更多 Server;Server 增多,投票阶段延迟增大,影响性能;引入 Observer,Observer 不参与投票; Observers 接受客户端的连接,并将写请求转发给 leader 节点;
- Leader:
-
ZAB 协议( ZooKeeper 原子消息广播协议——支持崩溃恢复的原子广播协议)——工作原理
- 事务编号 Zxid (事务请求 计数器 + epoch ):
- Zxid 是一个 64 位的数字,其中低 32 位是一个简单的单调递增的计数器,针对客户端每一个事务请求,计数器加 1;而高 32 位则代表 Leader 周期 epoch 的编号;
- 每个当选产生一个新的 Leader 服务器,就会从这个 Leader 服务器上取出其本地日志中最大事务的 ZXID,并从中读取epoch 值,然后加 1,以此作为新的 epoch,并将低 32 位从 0 开始计数。
- ZAB 协议 4 阶段
- Leader election (选举阶段 - 选出准 Leader ):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。只有到达 广播阶段(broadcast) 准 leader 才会成为真正的 leader。这一阶段的目的是就是为了选出一个准 leader,然后进入下一个阶段。
- Discovery (发现阶段 - 接受提议、生成 epoch 、接受 epoch ):在这个阶段,followers 跟准 leader 进行通信,同步 followers最近接收的事务提议。这个一阶段的主要目的是发现当前大多数节点接收的最新提议,并且准 leader 生成新的 epoch,让 followers 接受,更新它们的 accepted Epoch
- Synchronization (同步阶段 - 同步 follower 副本 ):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。只有当大多数节点都同步完成,准 leader 才会成为真正的 leader。follower 只会接收 zxid 比自己的 lastZxid 大的提议。
- Broadcast (广播阶段 -leader 消息广播 ):到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
- 事务编号 Zxid (事务请求 计数器 + epoch ):
-
投票机制:每个 sever 首先给自己投票,然后用自己的选票和其他 sever 选票对比,权重大的胜出,使用权重较大的更新自身选票箱。
- 每个 Server 启动以后都询问其它的 Server 它要投票给谁。对于其他 server 的询问,server 每次根据自己的状态都回复自己推荐的 leader 的 id 和上一次处理事务的 zxid(系统启动时每个 server 都会推荐自己)
- 收到所有 Server 回复以后,就计算出 zxid 最大的哪个 Server,并将这个 Server 相关信息设置成下一次要投票的 Server。
- 计算这过程中获得票数最多的的 sever 为获胜者,如果获胜者的票数超过半数,则改server 被选为 leader。否则,继续这个过程,直到 leader 被选举出来
- leader 就会开始等待 server 连接
- Follower 连接 leader,将最大的 zxid 发送给 leader
- Leader 根据 follower 的 zxid 确定同步点,至此选举阶段完成。
- 选举阶段完成 Leader 同步后通知 follower 已经成为 uptodate 状态
- Follower 收到 uptodate 消息后,又可以重新接受 client 的请求进行服务了
-
ZK节点:(1)短暂/临时(Ephemeral):当客户端和服务端断开连接后,所创建的Znode(节点)会自动删除;(2)持久(Persistent):当客户端和服务端断开连接后,所创建的Znode(节点)不会删除。
- PERSISTENT:持久的节点。除非手动删除,否则节点一直存在于Zookeeper上
- EPHEMERAL:暂时的节点。临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与zookeeper连接断开,不一定会话失效),那么这个客户端创建的所有临时节点都会被移除。
- PERSISTENT_SEQUENTIAL:持久化顺序编号目录节点。基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型 数字。
- EPHEMERAL_SEQUENTIAL:暂时化顺序编号目录节点。基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的自增整型数字。
-
RPC服务注册、发现过程
- 服务提供者启动时,会将其服务名称,ip地址注册到配置中心。
- 服务消费者在第一次调用服务时,会通过注册中心找到相应的服务的IP地址列表,并缓存到本地,以供后续使用。当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从IP列表中取一个服务提供者的服务器调用服务。
- 当服务提供者的某台服务器宕机或下线时,相应的ip会从服务提供者IP列表中移除。同时,注册中心会将新的服务IP地址列表发送给服务消费者机器,缓存在消费者本机。
- 当某个服务的所有服务器都下线了,那么这个服务也就下线了。
- 同样,当服务提供者的某台服务器上线时,注册中心会将新的服务IP地址列表发送给服务消费者机器,缓存在消费者本机。
- 服务提供方可以根据服务消费者的数量来作为服务下线的依据。
-
心跳检测:定时向各个服务提供者发送一个请求(实际上建立的是一个 socket 长连接),如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除。
-
统一配置管理:
-
统一命名服务:
-
分布式锁:
-
集群状态:
-
参考链接
三、序列化
四、负载均衡
- 负载均衡策略
- 轮循均衡(Round Robin):每一次来自网络的请求轮流分配给内部中的服务器,从 1 至 N 然后重新开始。此种均衡算法适合于服务器组中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
- 权重轮循均衡(Weighted Round Robin):根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。此种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
- 随机均衡(Random):把来自网络的请求随机分配给内部中的多个服务器。
- 权重随机均衡(Weighted Random):此种均衡算法类似于权重轮循算法,不过在处理请求分担时是个随机选择的过程。
- 响应速度均衡(Response Time 探测时间):负载均衡设备对内部各服务器发出一个探测请求(例如 Ping),然后根据内部中各服务器对探测请求的最快响应时间来决定哪一台服务器来响应客户端的服务请求。
- 最少连接数均衡(Least Connection):对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器。
- 处理能力均衡(CPU、内存):把服务请求分配给内部中处理负荷(根据服务器 CPU 型号、CPU 数量、内存大小及当前连接数等换算)最轻的服务器。
- DNS 响应均衡(Flash DNS):在此均衡算法下,分处在不同地理位置的负载均衡设备收到同一个客户端的域名解析请求,并在同一时间内把此域名解析成各自相对应服务器的 IP 地址并返回给客户端,则客户端将以最先收到的域名解析 IP 地址来继续请求服务,而忽略其它的 IP 地址响应。
- 哈希算法:一致性 Hash,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
- IP 地址散列( 保证客户端服务器对应关系稳定 ):通过管理发送方 IP 和目的地 IP 地址的散列,将来自同一发送方的分组(或发送至同一目的地的分组)统一转发到相同服务器的算法。
- URL 散列:通过管理客户端请求 URL 信息的散列,将发送至相同 URL 的请求转发至同一服务器的算法。
- 负载均衡分类
- 二层负载均衡(mac):根据OSI模型分的二层负载,一般是用虚拟mac地址方式,外部对虚拟MAC地址请求,负载均衡接收后分配后端实际的MAC地址响应.
- 三层负载均衡(ip):一般采用虚拟IP地址方式,外部对虚拟的ip地址请求,负载均衡接收后分配后端实际的IP地址响应. (即一个ip对一个ip的转发, 端口全放开)
- 四层负载均衡(tcp):在三次负载均衡的基础上,即从第四层"传输层"开始, 使用"ip+port"接收请求,再转发到对应的机器。
- 七层负载均衡(http):从第七层"应用层"开始, 根据虚拟的url或IP,主机名接收请求,再转向相应的处理服务器。
- 参考链接:https://www.cnblogs.com/kevingrace/p/6137881.html
- 区别:
五、动态代理实现(未理解)
- 静态代理
- 步骤
- 定义一个接口及其实现类;
- 创建一个代理类同样实现这个接口
- 将目标对象注入进代理类,然后在代理类的对应方法调用目标类中的对应方法。这样的话,我们就可以通过代理类屏蔽对目标对象的访问,并且可以在目标方法执行前后做一些自己想做的事情。
- 步骤
- JDK动态代理
- 步骤:
- 定义一个接口及其实现类;
- 自定义 InvocationHandler 并重写invoke方法,在 invoke 方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑;
- 通过 Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h) 方法创建代理对象;
- 实现原理:https://blog.csdn.net/mhmyqn/article/details/48474815
- JDK提供了java.lang.reflect.Proxy类来实现动态代理的,可通过它的newProxyInstance来获得代理实现类
- 对于代理的接口的实际处理,是一个java.lang.reflect.InvocationHandler,它提供了一个invoke方法供实现者提供相应的代理逻辑的实现
- 步骤:
- CGLIB 动态代理
- 步骤:
- 定义一个类;
- 自定义 MethodInterceptor 并重写 intercept 方法,intercept 用于拦截增强被代理类的方法,和 JDK 动态代理中的 invoke 方法类似;
- 通过 Enhancer 类的 create()创建代理类;
- 实现原理:https://blog.csdn.net/john_lw/article/details/79539070
- 步骤:
- 参考链接
第三部分 dubbo原理与源码
一、dubbo-registry——注册中心模块
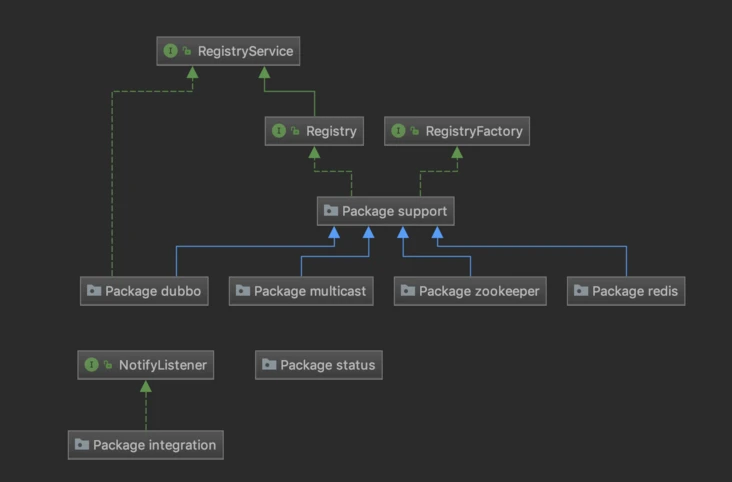
- 概念:dubbo的注册中心实现有Multicast注册中心、Zookeeper注册中心、Redis注册中心、Simple注册中心,这个模块就是封装了dubbo所支持的注册中心的实现。
- 组成:
- dubbo-registry-api:抽象了注册中心的注册和发现,实现了一些公用的方法,让子类只关注部分关键方法。
- 四个包是分别是四种注册中心实现方法的封装,其中dubbo-registry-default就是官方文档里面的Simple注册中心。
二、dubbo-cluster——集群模块
三、dubbo-common——公共逻辑模块
四、dubbo-config——配置模块
五、dubbo-rpc——远程调用模块
六、dubbo-remoting——远程通信模块
七、dubbo-container——容器模块
八、dubbo-monitor——监控模块
九、dubbo-bootstrap——清理模块
十、dubbo-demo——示例模块
十一、dubbo-filter——过滤器模块
十二、dubbo-plugin——插件模块
十三、dubbo-serialization——序列化模块
十四、dubbo-test——测试模块
十五、Dubbo扩展机制SPI
- JDK的SPI思想:SPI的全名为Service Provider Interface,面向对象的设计里面,模块之间推荐基于接口编程,而不是对实现类进行硬编码,这样做也是为了模块设计的可拔插原则。为了在模块装配的时候不在程序里指明是哪个实现,就需要一种服务发现的机制,jdk的spi就是为某个接口寻找服务实现。
- Dubbo的SPI扩展机制原理:改进了JDK标准的SPI机制
- 实现:
- 注解@SPI
- 注解@Adaptive
- 注解@Activate
- 接口ExtensionFactory
- ExtensionLoader
- AdaptiveExtensionFactory
- SpiExtensionFactory
- ActivateComparator
第四部分 面试题
-
rpc流程:
-
rpc使用的协议
-
Netty 的高性能体现在哪方面、Netty为什么说使用简单、Netty 的优势有哪些?
-
默认情况 Netty 起多少线程?何时启动?
-
rpc服务调用失败怎么做的(failovercluster)
-
RPC框架设计需要哪些功能你怎么实现的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号